
实时数据仓库是一种能够实时或近实时处理、存储和分析大规模数据的系统。与传统批处理数据仓库不同,它在数据生成的瞬间即可完成处理和分析,将数据处理延迟从小时或天级压缩到秒级甚至毫秒级。其核心价值在于支持企业即时洞察业务状态、快速响应市场变化并做出精准决策。 区别于“近似实时”(延迟在分钟或小时级),真正的实时数据仓库要求延迟可忽略不计,这种能力已成为企业数字化转型的核心基础设施,尤其在需要快速决策的领域。
由于不同行业对实时性的需求不同。按照数据目标划分为两类,数据存储与数据分析。
需要支持高并发和低延迟的查询,常见的选择包括NoSQL数据库(如Cassandra)和内存数据库(如Redis)。
数据分析的场景中,目前也有两种主流架构:
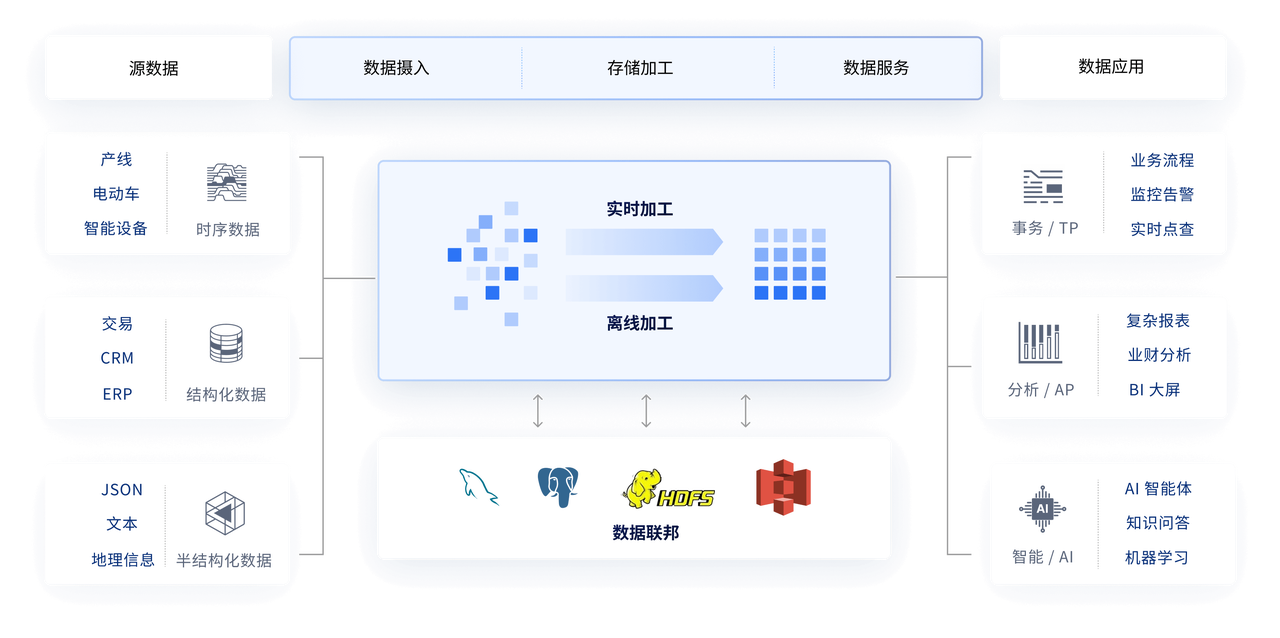
数据采集层负责捕获实时数据流入,例如通过消息队列系统(如Kafka)进行数据传输。数据处理层则使用流处理框架(如Apache Flink或Apache Storm)进行实时数据处理和计算。
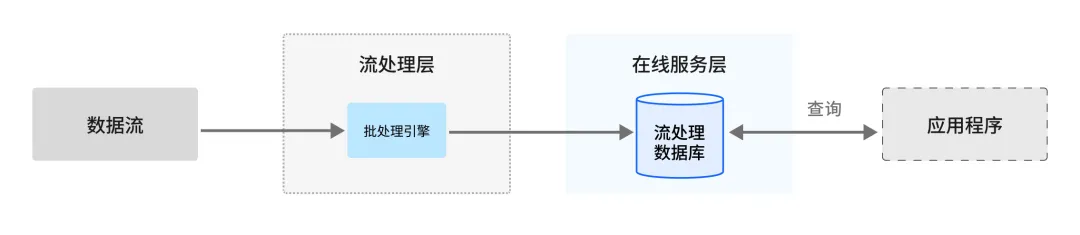
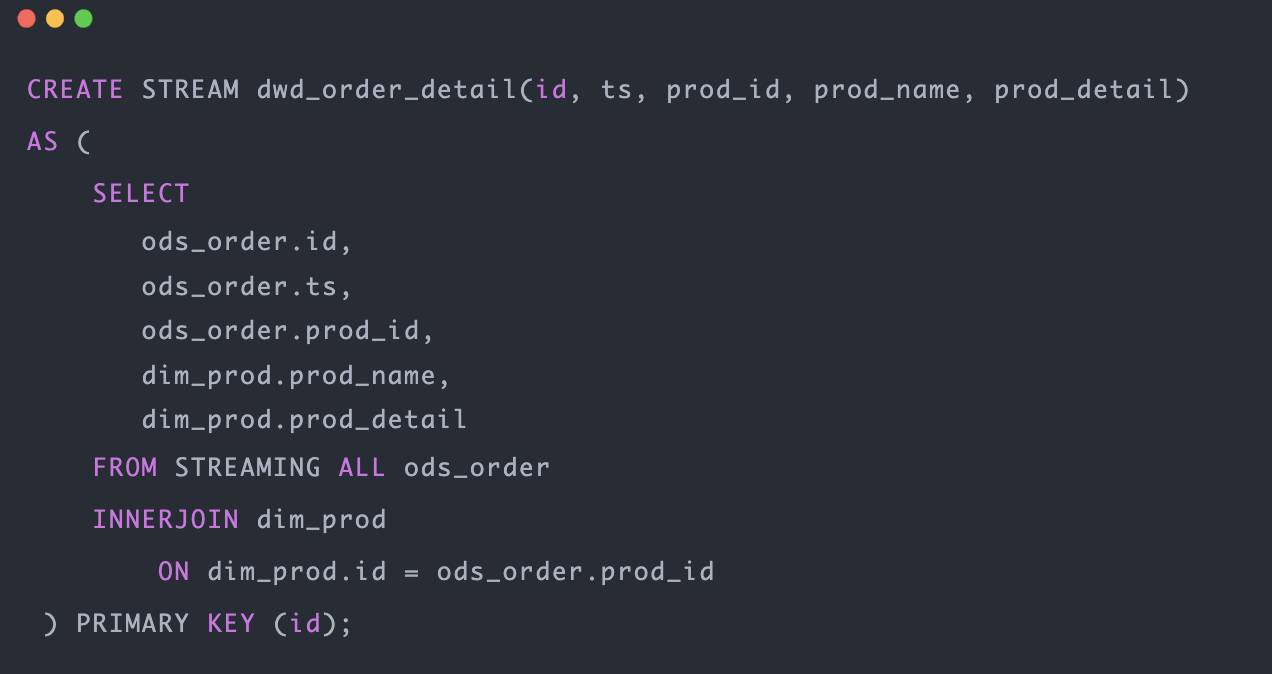
数据不分层, YMatrix的“流表” 模型它将流数据视为表的连续更新,任何时间点的分析不必从数据采集层调取数据,可以对“流表”当前数据进行实时计算。下面是一个简单的流表(dwd_order_detail) 的示意,实现了一个基础的扩维操作。
实时数据仓库能够帮助业务前线做到,决策速度提升:将传统T+1天的决策周期缩短至秒级。零售企业可实时监控销售数据,金融公司能实时识别欺诈交易。运营效率跃升:制造企业通过实时监控生产线设备状态,可提前预测故障并自动调度维护资源;升级客户体验:基于实时用户行为分析,电商平台推送转化更精确,客户服务系,及时介入避免负面评价扩散。
不同行业已形成特色鲜明的实时数据应用模式。零售电商多用于实时监控全渠道销售动态,结合库存状态动态调整定价策略。智能制造多用于时序数据存储,和产线的风险预警,提高产品良品率。金融风控用于识别异常模式。物流行业综合配送数据实时推送物流动态保障物流安全。医疗健康 检测病患动态或是物品库存。
实时数据仓库的未来发展将会呈现两大核心趋势。一方面是数据需求日益复杂化,表现为数据量激增(如海量物联网设备数据)、数据类型更加多样(需同时处理交易、日志、传感器、位置等各类数据)、处理要求更高(需实时关联、预测分析等);另一方面则是技术架构追求简约化,企业用一套系统、一套代码(如统一SQL)同时处理实时数据和历史数据,彻底告别过去两套系统并行的复杂架构,显著提升开发效率和运维简便性。 这种“以简驭繁”的趋势还将融合AI实时分析、云计算的弹性伸缩能力以及边缘计算的分层处理,最终目标是以更简单强大的架构支撑更复杂的实时业务需求。
成功部署实时数仓需把握五个关键环节: 首先是明确业务需求和目标,确定需要实现的实时数据处理和分析场景,以及相应的性能和可用性要求。其次是选择合适的技术和工具,比如银行可以选择Redis,工业物联网可以选择YMatrix。然后渐进式建设路径 进行测试优化,避免一步到位的高风险方案,从核心场景起步。之后建立健壮的保障机制,部署三位一体防护网:Exactly-once语义/离线补数通道/自动监控等。最后是优化及控制成本,通过业务深度融合,减少数仓使用成本。
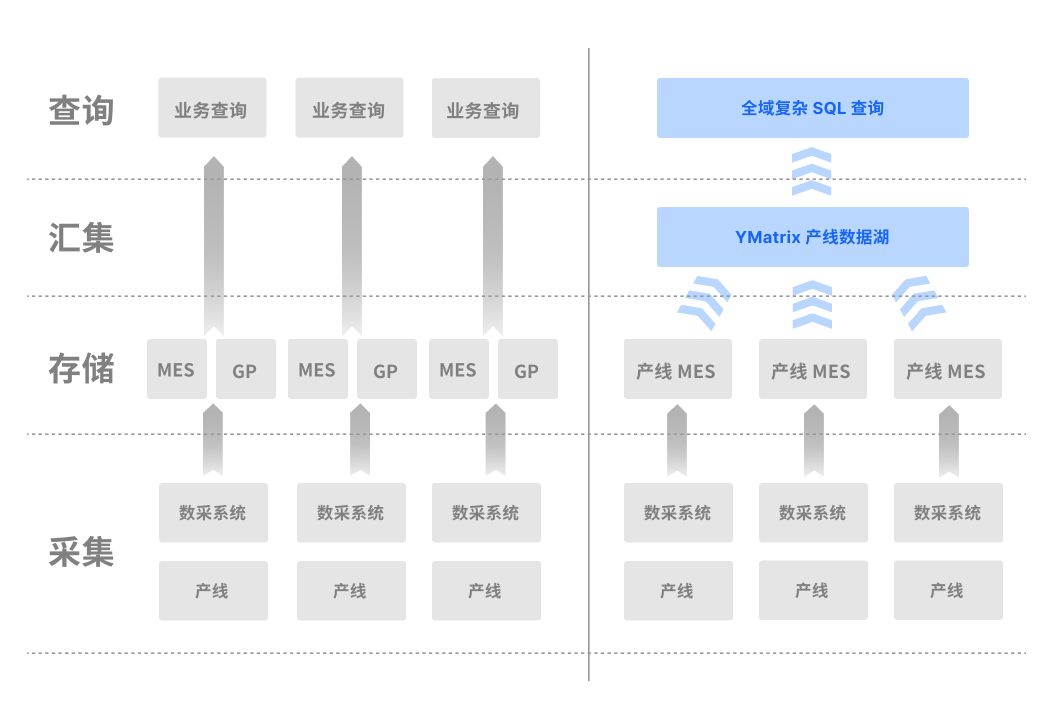
某大型能源科技公司在新能源电池生产领域不断扩张,其多个生产基地产线数据库繁杂,数据采集标准不一,工厂级 MES 层数据查询与分析效率低下。使用YMatrix,利用其实时数仓性能,打破数据孤岛,将历史数据数据迁移,并且将实时数据引入数仓,完成压缩与复杂 SQL 计算,架构简化,写入延迟降低,复杂查询效率提升,及时发现生产异常,帮助企业进行快速决策分析。
构建实时数仓,选对技术很关键。处理实时数据流,常用引擎有:Flink(延迟极低毫秒级,保证数据准确处理一次,适合当前数据设施复杂的系统,直接添加),Spark Streaming(延迟稍高秒级,开发相对简单,适合准实时报表),YMatrix(特别擅长处理海量设备传感器数据,写入快,实时分析)。。此外存储数据方面:Redis(极快缓存),HBase(存超大数据),Cassandra(多地部署防故障)也常用于特定环节。企业根据自身需求,选择相应架构,下文提到的数仓运维难度也应当纳入考量。
要确保实时数仓高效稳定运行,关键点在于:动态调配资源,比白天优先保障实时任务,夜间做批量校准;根据业务管理数据周期新数据放快速存储,稍旧数据转低成本存储,历史数据归档压缩。并且建立全面监控以持续优化调整。






