
预测性维护并非如仙人算命般,可预估数月之后某台机器的某个部件会出现何种问题。事实上,即便现代医学历经多年发展,亦无法对人体进行如此精准的预测。至多只能表明,若一个人长期维持不健康的生活方式,20年后患某某疾病的概率颇高。然而,这种具有较大时间跨度的估计,显然无法助力我们对工业设备开展更为高效的运维工作。
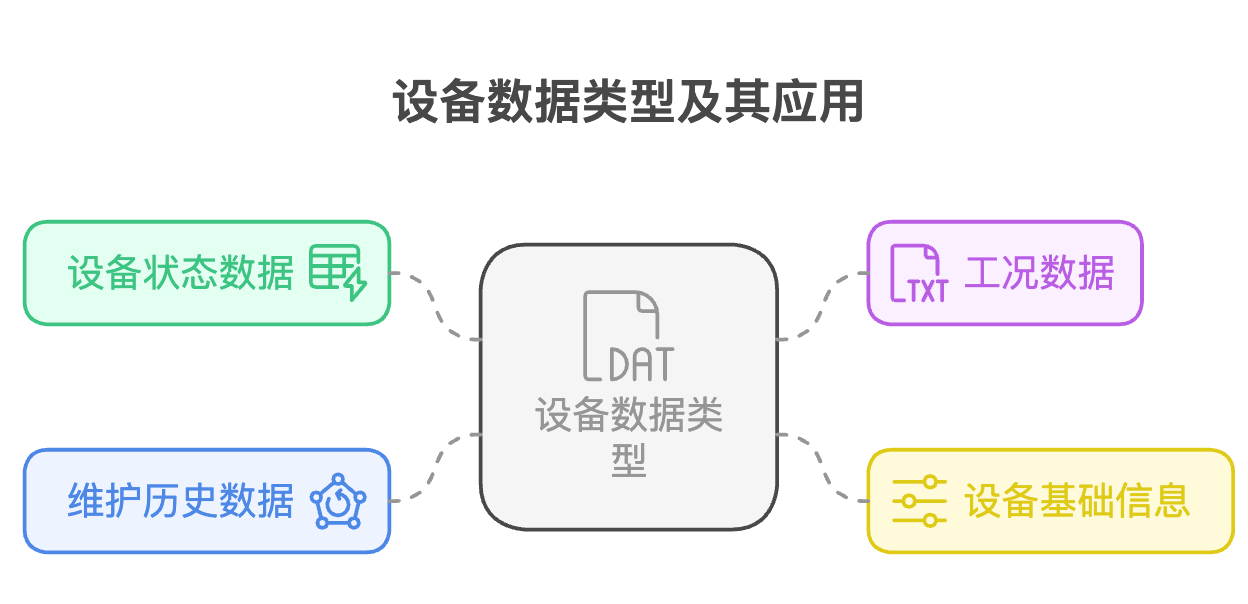
在常见的场景下,预测性维护需要维护4种设备数据
这些数据直接反映设备运行时的物理表现,通常由传感器或控制器实时采集。比如设备运转时的各类测量值,它们构成评估设备健康度的基础指标。这些数据的特点是高频持续产生,需要专门的采集通道。对于To C产品如工程机械,会影响到终端客户对设备使用结果的情绪,会产生抱怨,甚至投诉到设备生产商去,对于To B产品如产线上的设备,会影响到批量产成品的质量一致性,进而造成更大的损失。
单独看设备状态数据容易误判,就像只看体温无法区分患者是运动后发热还是疾病引起的高烧。工况数据记录设备执行的任务内容、环境参数等背景信息。例如机床正在加工的材料硬度,或者风机当前遭遇的风速变化。这些数据一般存在于生产管理系统,需要与状态数据时间对齐。
相同型号的设备可能因配置差异表现出不同特性。基础信息包括设备的生产批次、零部件规格、设计参数等静态属性。当某台设备出现异常时,这些信息帮助锁定特定批次的组件缺陷或设计缺陷。这类数据通常存储在资产管理系统,变更频率较低但检索需求频繁。
设备维修记录包含故障现象、处理方法和复发周期等重要信息。比如某台泵机过去两次振动超标分别是密封圈老化和轴承损坏,维修方案完全不同。这类数据通过持续积累形成故障诊断的知识库,存在于维护管理系统,往往包含非结构化描述。
所以,做预测性维护的目的,不是单纯地为了保障机器能【正常】运转,而是为了保障机器能按照最理想的或最初的性能【高校】运转,不要给产线或终端用户产生额外的经济损失。
如果要达到上述目标,对企业的数据基础设施性能提出了非常大挑战。而我们一般通过如下思路去完成上述数据的获取和分析。
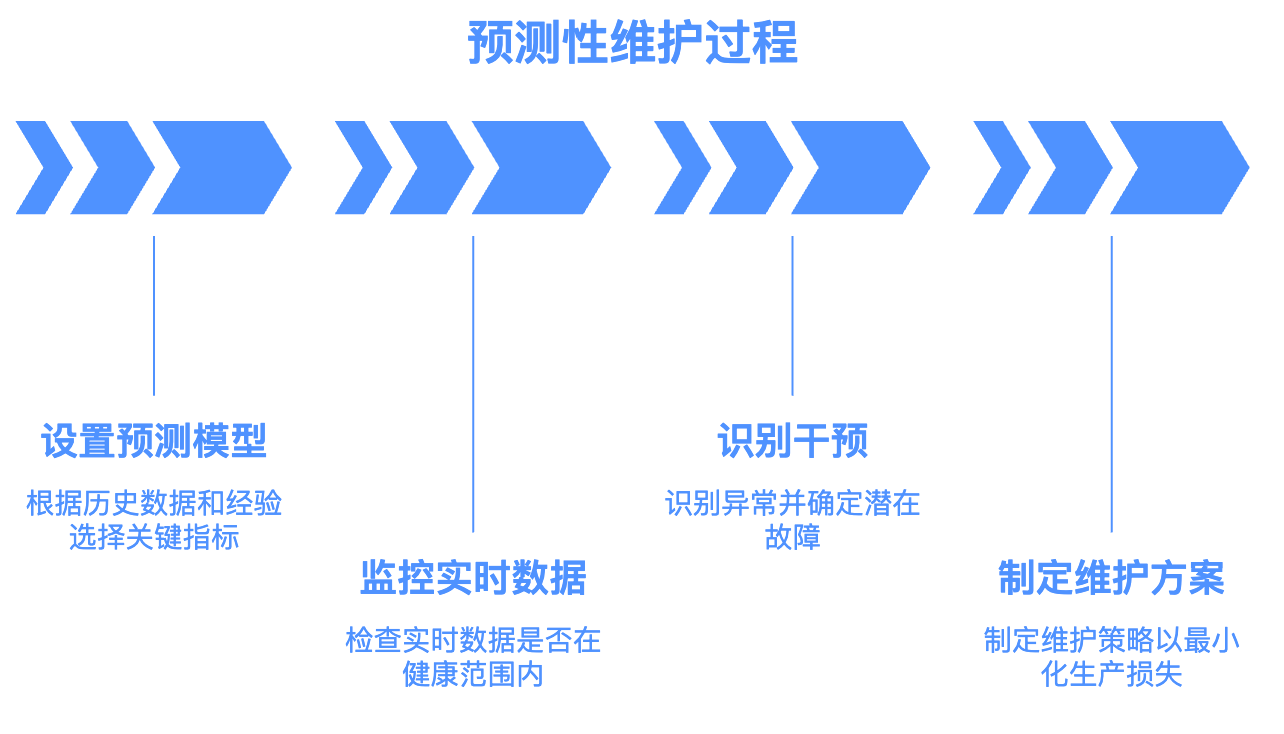
根据已有的数据进行分析,或者是经验人士的推理验证,选定1个或几个与结果最相关的指标,所谓预测模型的关键值。并根据过往值设置健康范围。
根据设备的实时数据及历史数据,计算当前设备的关键值是否符合健康范围。如果处于健康范围则正常,如果超过健康范围则进入干预进程。
针对非健康情况,会有不同的指标表现。比如同一台设备,可能会出现多个温度超标、噪音超标、功率超标表现,这样不同的表现,会意味着不同的故障,由异常表现推理出故障的过程为便辨识过程。这一过程需要非常大的信息量,既需要设备信息,有需要设备历史状况信息,也需要历史维修信息(如何维修、具体问题等);只有当上述信息完整获取时,才能为问题辨识提供准确的信息基础。
根据信息制作方案,方案除了维护方法和策略以外,还需要需要包含停工时间,停工时长等设置。以确保达到生产损耗最小的效果。
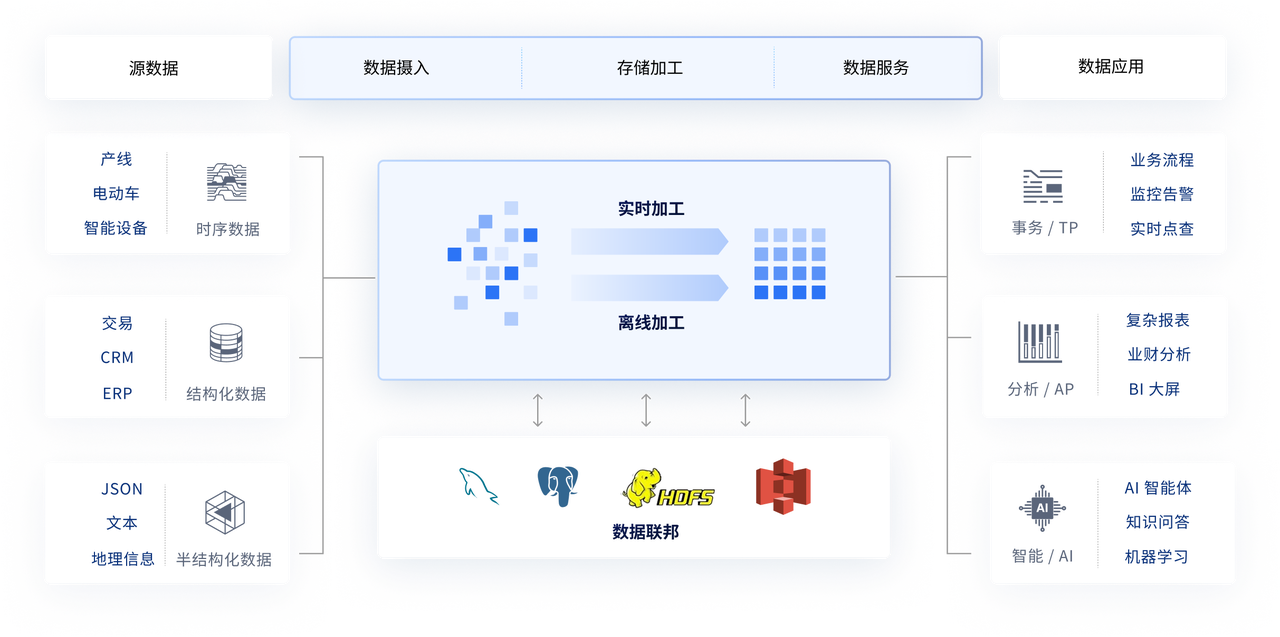
上文的思路,一般在实际情况中遇到的最大阻碍是,不同类的数据分别分散于不同系统之中:比如状态数据源自监控系统,工况数据出自生产系统,基础信息存放于资产库,而维护记录则存在于服务系统。这种数据分离的状况引发了两个主要问题:其一,数据关联存在困难,如果报警出现无法关联其他系统的历史工况数据;其二,无法充分整合不同系统的数据,以获得指标的完整信息。
其次是实时性。除了散布在多系统中的数据导致运算速度慢以外,本身数据量的大小也会影响计算结果的实时性。因此高性能的实时数仓也是预测性维护效果的一个重要支撑。
解决方案在于构建一个统一的实时数据平台。根据文章第一部分的数据分类来看,状态数据宜采用时序数据库予以存储,以契合高频写入的需求;工况数据则适宜运用分布式数据库,如此便于开展关联查询;基础数据可置于关系型数据库;维护记录则需具备支持文本检索与关系映射的功能。因此一个具有四类数据库能力的统一数据底座非常重要。目前超融合实时数据库是一个很好的选择。例如国产YMatrix超融合数据库,能够同时支持不同数据的高效存入和实时分析。
预测性维护的落地本质是数据体系的建设过程。它要求企业持续积累设备全生命周期的状态记录、任务上下文、结构属性和维护经验,并通过技术手段实现四类数据的时空对齐。这个过程没有捷径,但每一步推进都能提升设备性能监护的准确性。当数据链条足够完整时,维护策略才能从被动检修转向精准预防。






