
为了适应不同场景的需求,在 YMatrix 中支持三种写入模式,由表级参数 prefer_load_mode 和 rowstore_size 共同决定:
不同模式的写入流程
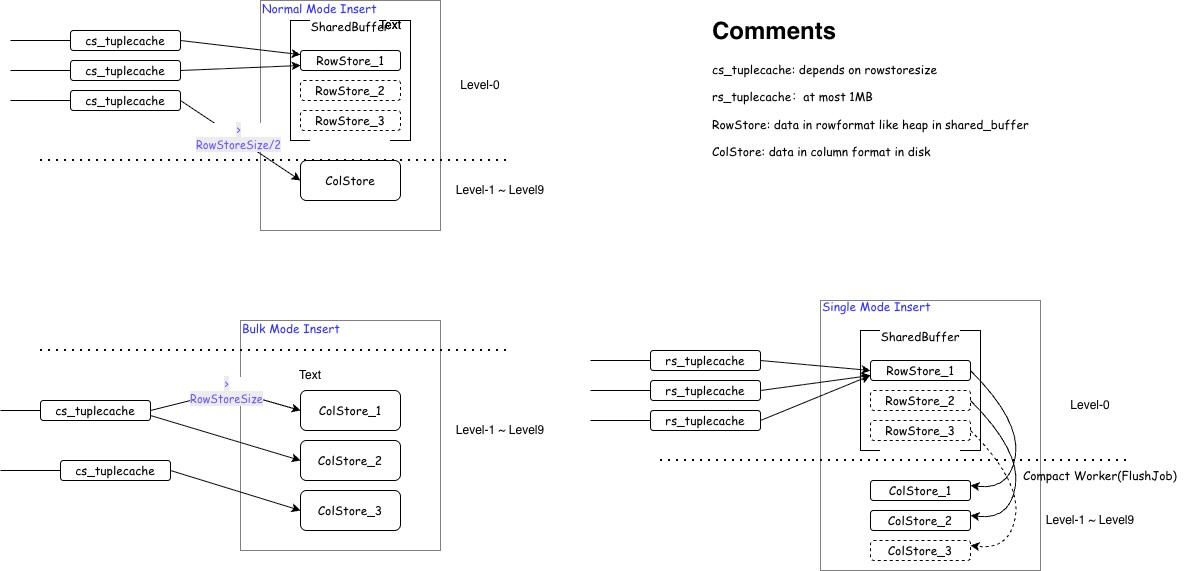
在 Single 模式下,数据会在本地内存中最多积攒 1MB,然后直接插入到 rowstore 中,整个写入过程和传统的 PostgreSQL Heap 写入类似,数据直接放置在 Shared Buffers 中,其大小由同名参数 shared_buffers 控制,在 Single 模式下,可以酌情调大此参数,否则也会发生内存置换。
Shared Buffers 的置换策略
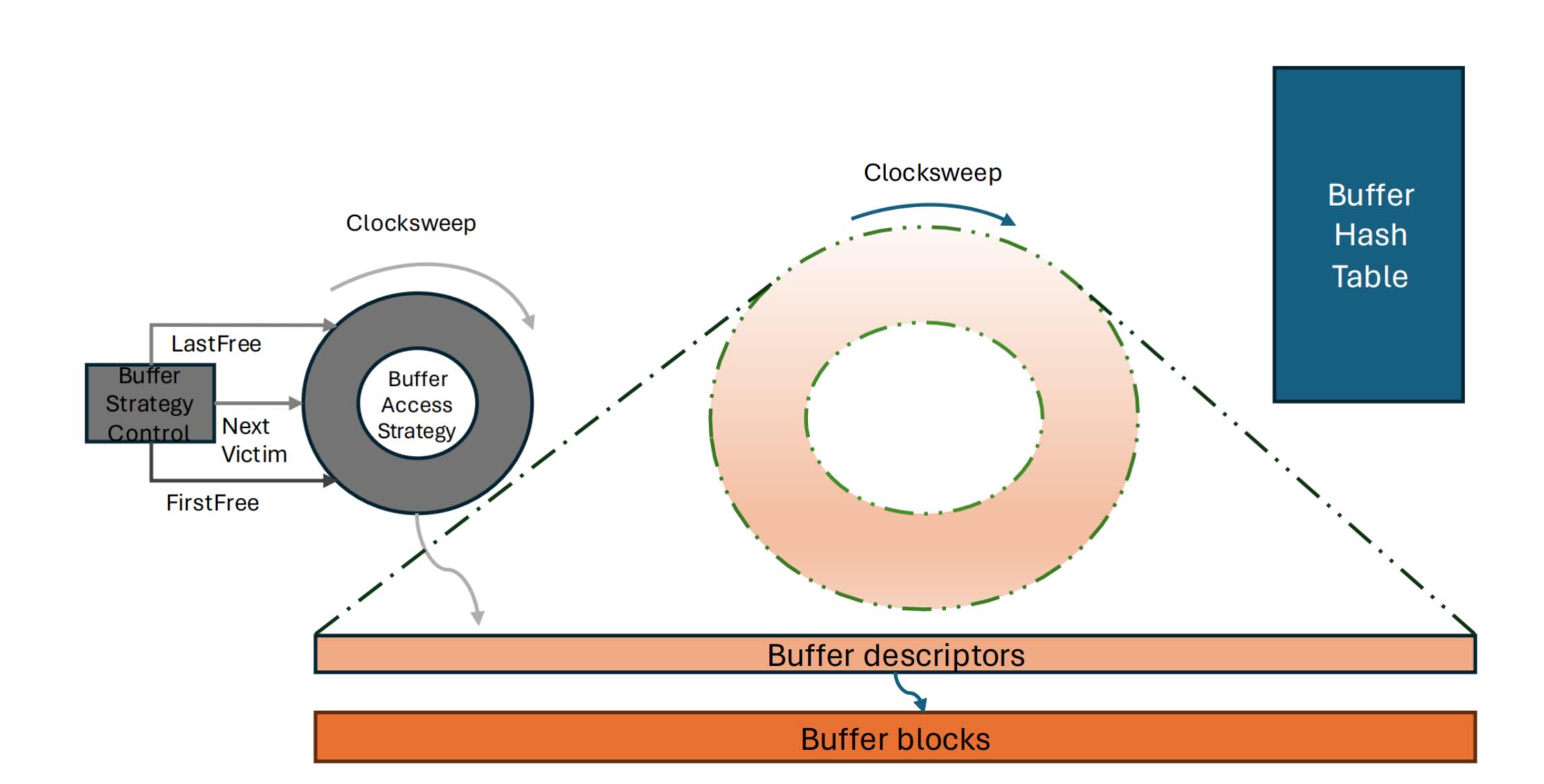
优点:插入延迟最小,内存消耗最小。
缺点:
对于大数据量插入, 数据由于先进入到 rowstore,多了一次合并的过程
数据进入 rowstore 后,假如不能尽快的转换成 columnstore,查看表大小 (\dt+) 会比较大,可以在查看前手动执行一次 vacuum + vacuum full
AP 查询 和 BRIN 查询效率均不如 columnstore
由于没有压缩,数据和 XLOG 大小均大于 columnstore 数倍,不适合 IO 很差的环境
在 Bulk 模式下,数据会先拷贝到本地内存,最多达到 rowstore_size 大小,当达到 rowstore_size 大小时,会被直接转换成 columnstore 刷新到磁盘,当插入结束,本地内存未达到 rowstoresize 大小时,仍然会转换成 columnstore 刷新到磁盘中。
优点:
数据经过压缩,对磁盘 IO 更加友好
AP 查询 和 BRIN 查询效率比 rowstore 好
少了一次写放大
缺点:
占用内存更多,数倍于 rowstore,尤其是分区表数量多的情况
插入延迟不如 rowstore
智能插入模式,数据会被拷贝到本地内存,当达到 rowstore_size 大小时,会被直接转换成 columnstore 刷新到磁盘,当插入结束,本地内存未达到 (rowstore_size / 2) 大小时,则会写入到当前的 rowstore 中,否则会转换成 columnstore 刷新到磁盘中,默认为 normal 模式。
| 测试类型 | 每客户端事务数 | 客户端数 | 线程数 | 平均延迟 (ms) | TPS (包括连接) | TPS (不包括连接) |
|---|---|---|---|---|---|---|
| single_insert.sql | 100,000 | 1 | 1 | 1.98 | 505.03 | 505.06 |
| bulk_insert.sql | 100,000 | 1 | 1 | 15.282 | 65.44 | 65.44 |
| normal_insert.sql | 100,000 | 1 | 1 | 1.968 | 508.02 | 508.05 |
| 模式 | 总耗时 | 总秒数 (s) | 每秒行数 (rows/s) |
|---|---|---|---|
| single | 2m27s | 147 | ≈ 680 |
| normal | 2m28s | 148 | ≈ 676 |
| bulk | 4m55s | 295 | ≈ 339 |
| 模式 | 行数 | 用时 (秒) |
|---|---|---|
| bulk | 50,000,000 | 69.287 |
| single | 50,000,000 | 50.868 |
| normal | 50,000,000 | 70.612 |
压缩比接近 10 倍,TPS 相较于 heap 约 25% 左右的损耗
| 表名 | 压缩比 | 存储节省 |
|---|---|---|
| fi_voucher | 7:01 | 86% |
| fi_voucher_b | 15:01 | 93% |
| aai_voucher | 4.5:1 | 78% |
| aai_voucher_record | 8.9:1 | 89% |
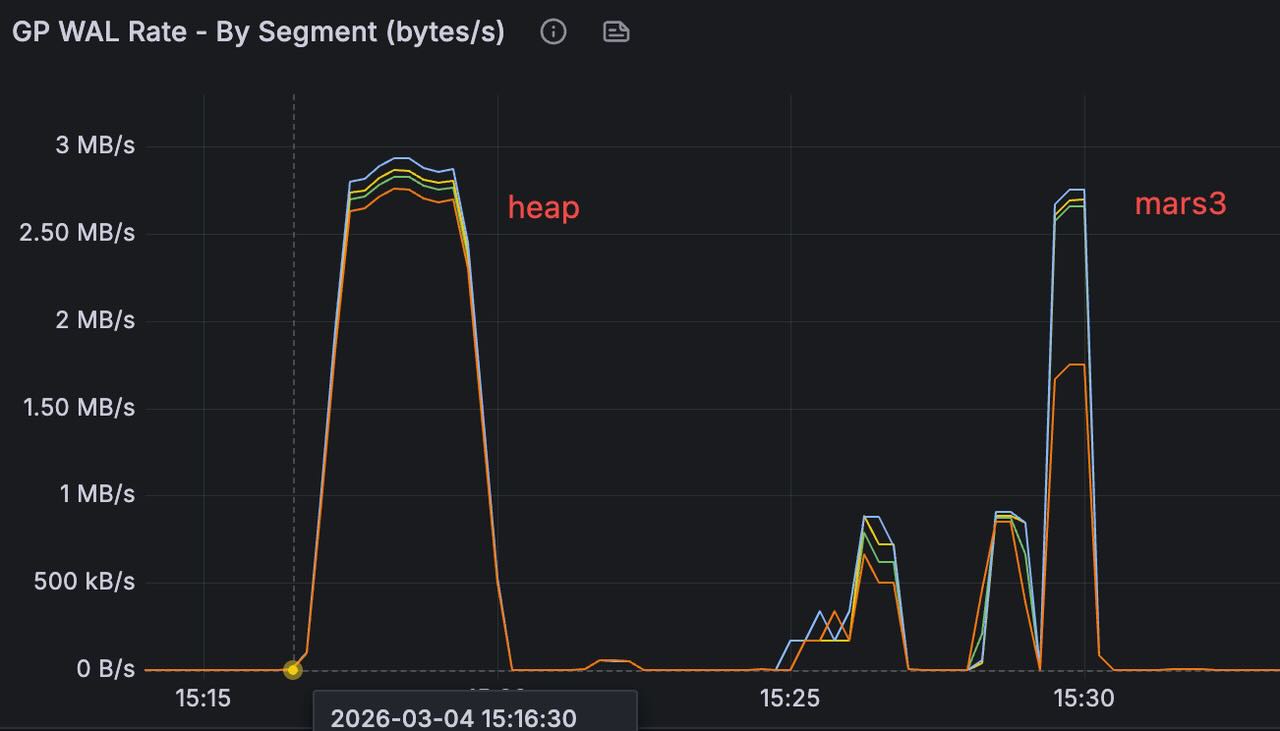
某实测场景中,插入相同大小的数据,可以看到产生 WAL 的速率相同,但是总体生成的 WAL 大约是 Heap 的 1/3,可以大幅减少 WAL 占用的存储空间。
由于 Range 压缩后是变长的,不能使用现成的 Shared Buffers 机制,因此设计了一个只读的支持变长数据的缓存,用于支持索引扫描路径进来的查询,索引扫描查询对延迟比较敏感,我们通过缓存的方式来缓解列存带来的读放大问题,同时缓存中存放的是对索引扫描更友好的格式,索引扫描准确的知道是哪一个元组,所以缓存里格式以及读取可以快速定位到某一行。由于 Range 压缩后是变长的,不能使用现成的 Shared Buffers 机制,因此设计了一个只读的支持变长数据的缓存,用于支持索引扫描路径进来的查询,索引扫描查询对延迟比较敏感,我们通过缓存的方式来缓解列存带来的读放大问题,同时缓存中存放的是对索引扫描更友好的格式,索引扫描准确的知道是哪一个元组,所以缓存里格式以及读取可以快速定位到某一行。
对于 MARS3,有一块和 Shared Buffers 类似的缓存,称之为 varbuffer,varbuffer 主要用于优化索引扫描,由于 columnstore 都是直接写直接读,varbuffer 用于缓存解压后的 stripe 数据,因为磁盘里存放的都是压缩后的数据。如果都是索引扫描,可以根据情况调整此参数(需要重启)
① 先查 varbuffer
命中 → 直接用解压后的stripe(看到的是压缩前的stripe)
② miss → 发起 buffer io
↓
OS cache 命中?
是 → 拿到压缩stripe(无磁盘IO)
否 → 真磁盘读
③ 拿到压缩stripe
→ 解压
→ 放入 varbufferpostgres=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
1GB
(1 row)根据理论,varbuffer 越大,索引扫描的效果越好,对于顺序扫描的影响弱。其次也要注意 OS cache 的影响,每次测试前删除 OS cache,并且重启数据库。构建数据集
CREATE TABLE t_m3 (
id bigint,
ts timestamptz,
v double precision,
pad int
)
USING MARS3
DISTRIBUTED BY (id);
INSERT INTO t_m3
SELECT
(g % 1000000)::bigint AS id,
'2026-01-01'::timestamptz + (g || ' seconds')::interval AS ts,
(random()*1000)::float8 AS v,
(g % 1000)::int AS pad
FROM generate_series(1, 20000000) g;
ANALYZE t_m3;
CREATE INDEX idx_t_m3_id_ts ON t_m3 (id, ts);
ANALYZE t_m3;验证结果
adw=# show mx_varbuffer_size;
mx_varbuffer_size
-------------------
64MB
(1 row)
adw=# \q
[mxadmin@sdw ~]$ /usr/bin/time -f "pass1: %e s" bash -c '
> for i in $(seq 1 20000); do
> psql -X -qAt -c "SELECT v FROM t_m3 WHERE id=$i AND ts='\''2026-01-02 00:00:00+00'\'';" >/dev/null
> done'
pass1: 238.07 s
adw=# show mx_varbuffer_size;
mx_varbuffer_size
-------------------
1GB
(1 row)
adw=# \q
[mxadmin@sdw ~]$ /usr/bin/time -f "pass2: %e s" bash -c '
> for i in $(seq 1 20000); do
> psql -X -qAt -c "SELECT v FROM t_m3 WHERE id=$i AND ts='\''2026-01-02 00:00:00+00'\'';" >/dev/null
> done'
pass2: 238.72 s
adw=# select * from t_m3 where ts = '2026-01-02 00:00:00+00';
id | ts | v | pad
--------+------------------------+-------------------+-----
115200 | 2026-01-02 08:00:00+08 | 681.0068987279756 | 200
(1 row) 因为查询每次最多只命中 0~1 行,且几乎不复用 stripe,没有形成可缓存的工作集,所以二者差异并不大。
重新设计需要满足 4 个条件:
索引扫描稳定触发
单次查询返回中等规模数据
重复查询会反复命中同一批 stripe,形成热点
热点工作集大小可以卡在 64MB 和 1GB 之间
由于 OS cache 的影响,每次验证之前需要 echo 3 > /proc/sys/vm/drop_caches 清空 OS cache 以及重启数据库
测试结论:在清空 OS page cache 且重启数据库的冷启动条件下,针对同一热点窗口执行 1000 次 MxVIndexScan 聚合查询,mx_varbuffer_size=1GB 相比 64MB 将总耗时从 87.986s 降低至 17.514s (约 5.02 倍加速,80.1% 耗时下降)。该结果表明,varbuffer 容量对 MARS3 索引扫描场景下的解压后列数据复用具有决定性影响;当容量不足时,会出现显著的重复解压与缓存淘汰开销。
DROP TABLE IF EXISTS t_m3_vb_test;
CREATE TABLE t_m3_vb_test (
device_id int, -- 查询主键之一(高基数)
ts timestamptz, -- 时间维度(索引第二列)
metric_id smallint, -- 指标编号(低基数)
v1 double precision, -- 常用数值列
v2 double precision, -- 常用数值列
v3 double precision, -- 常用数值列
status int, -- 状态列(低基数)
tag int -- 填充列(增加工作集大小)
)
USING MARS3
DISTRIBUTED BY (device_id);
CREATE INDEX idx_t_m3_vb_test_dev_ts ON t_m3_vb_test (device_id, ts);
ANALYZE t_m3_vb_test;
-- 大约 3KW 数据
INSERT INTO t_m3_vb_test
SELECT
d.device_id,
t.ts,
m.metric_id,
(random() * 1000)::float8 AS v1,
(random() * 1000)::float8 AS v2,
(random() * 1000)::float8 AS v3,
(random() * 10)::int AS status,
(random() * 100000)::int AS tag
FROM generate_series(1, 100) AS d(device_id)
CROSS JOIN generate_series(
'2026-01-01 00:00:00+00'::timestamptz,
'2026-01-01 23:59:59+00'::timestamptz,
'1 second'::interval
) AS t(ts)
CROSS JOIN generate_series(1, 4) AS m(metric_id);64 MB varbuffer
每次 index scan 都会反复访问同一批 stripe / range,varbuffer 容量不足以容纳该热点窗口涉及的解压后列数据,因此每轮执行都发生大量:
stripe 再读取
重新解压
重新构造执行批次
导致 CPU/内存开销被放大。
adw=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
64MB
(1 row)
adw=# set enable_seqscan to off;
SET
adw=# set enable_bitmapscan to off;
SET
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts = '2026-01-01 10:00:00+00'
AND ts varbuffer 主要优化索引驱动的随机/热点访问,而不是顺序扫描主路径。
64 MB varbuffer
```sql
adw=# set enable_bitmapscan to off;
SET
adw=# set enable_indexscan to off;
SET
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts = '2026-01-01 10:00:00+00'
AND ts 同一批次压缩的数据多了,可能压缩效果更好,原理上重复的数据被压的更多了,要不然在两个批次里面就没压到一起。
### 4.3.1 compress_threshold 对于读取的性能影响
| id | compress_threshold=1200 | 3600 | 10000 | 50000 |
|----|------------------------|---------|---------|---------|
| 1 | 8.8032 | 7.7846 | 6.6471 | 6.6824 |
| 2 | 0.981 | 0.997 | 2.2284 | 2.2322 |
| 3 | 3.3512 | 3.3143 | 3.3184 | 3.3177 |
| 4 | 7.7059 | 7.7326 | 6.6034 | 5.5994 |
| 5 | 5.5732 | 5.5042 | 5.5939 | 6.633 |
| 6 | 0.478 | 0.38 | 0.545 | 0.545 |
| 7 | 1.1908 | 1.1917 | 2.2172 | 2.2222 |
| 8 | 3.3602 | 3.3129 | 3.3018 | 3.3227 |
| 9 | 8.8429 | 7.74 | 7.7751 | 7.7795 |
| 10 | 3.3835 | 4.4239 | 5.5496 | 5.5499 |
| 11 | 0.845 | 0.743 | 2.2307 | 2.2299 |
| 12 | 1.1998 | 1.1887 | 2.2164 | 2.2138 |
| 13 | 6.6514 | 6.6351 | 6.6784 | 6.6424 |
| 14 | 0.837 | 0.776 | 1.1364 | 1.1275 |
| 15 | 1.1436 | 1.1359 | 1.183 | 1.1783 |
| 16 | 1.1768 | 1.1787 | 2.2673 | 2.2757 |
| 17 | 9.9419 | 8.8705 | 8.8922 | 8.8771 |
| 18 | 11.11337 | 11.11522| 10.10384| 10.10647|
| 19 | 4.4792 | 3.3942 | 4.4918 | 4.467 |
| 20 | 2.2668 | 2.2389 | 3.3475 | 3.3346 |
| 21 | 11.11391 | 10.10633| 11.1119 | 10.10742|
| 22 | 3.3009 | 2.2864 | 3.372 | 3.3377 |
| sum| 97.73958 | 92.05015| 100.81134| 99.78189|
### 4.3.2 compress_threshold 对于写入的性能影响
| 测试场景 | compress_threshold | 1200 | 3600 | 10000 | 50000 |
|------------|---------------------|------------|-------------|--------------|--------------|
| 写入性能 | 分区表 (条/s) | 852,334 | 919,031 | 1,055,371 | 1,057,424 |
| 写入性能 | 非分区表 (条/s) | 991,463 | 1,033,751 | 1,054,292 | 1,076,714 |
| 查询性能 | time_bucket=1h (1天范围) | 357ms | 342ms | 333ms | 324ms |
| 查询性能 | time_bucket=1d (1月范围) | 7,384ms | 6,312ms | 6,008ms | 6,025ms |
| 查询性能 | time_bucket=30d (1年范围)| 94,278ms | 75,101ms | 68,184ms | 69,006ms |
| 查询性能 | 点查场景 | 19.416 ms | 20.043 ms | 23.692 ms | 37.844 ms |
### 4.3.3 索引压缩
索引压缩架构参照 mars3btree 章节
```sql
CREATE INDEX idx_name ON table_name
USING mars3btree (column_list)
WITH (
compresstype = 'lz4', -- 压缩算法
compresslevel = 1, -- 压缩级别
compressctid = true, -- 是否压缩CTID列
encodechain = '', -- 编码链
minmax = true -- 启用min/max优化
);compresstype (压缩算法):支持 lz4、zstd 和 mxcustom。默认为 lz4,lz4:压缩/解压速度快,压缩率中等;zstd:压缩率高,速度稍慢;mxcustom:需配合 encodechain 使用
compresslevel (压缩级别):支持 1 ~ 9,默认 1。对于查询密集型建议 1 ~ 3 (优先解压速度),存储敏感型建议 6 ~ 9 (优先压缩率)
compressctid (CTID 列是否压缩):默认为 true,建议保持为 true,CTID 列压缩率通常很高
在某客户场景中,使用索引压缩后:
对 TOB 集群影响较小,节点 CPU 与 MEM 变化不大,同时可节省 24% Ymatrix 分区存储空间; 对 TOC 集群效果显著,在牺牲一部分 CPU、MEM 的情况下,可节省 63% Ymatrix 分区存储空间。 50 辆车查询 1 天 GPS 数据,开启索引压缩的服务吞吐量是未开启索引压缩的 3.3 倍; 50 辆车查询 3 天 GPS 数据,开启索引压缩的服务吞吐量是未开启索引压缩的 1.1 倍。
前面提到,压缩 (不管是 zstd/lz4 还是 RLE/dict/bitpack 这些编码) 都依赖一个核心事实:同一块/同一 stripe 内的数据越规律,压缩越好。lz4/zstd 依赖重复子串/重复模式。排序后,同一块内字段组合更相似,尤其是宽表。当相近实体/相近时间的数据聚集在同一 stripe 内时,块内值域收敛、重复与成段重复增强,字典规模下降,delta/bitpacking 的 bit 宽度降低,从而提升编码与通用压缩的效果。
adw=# CREATE TABLE t_sort_good (
device_id int NOT NULL,
ts timestamptz NOT NULL,
site_id int NOT NULL,
status smallint NOT NULL,
v1 double precision NOT NULL,
v2 double precision NOT NULL,
attrs jsonb NOT NULL
)
USING MARS3
WITH (compresstype=zstd,compresslevel=3,mars3options='prefer_load_mode=bulk')
ORDER BY (device_id, ts);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'device_id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
adw=# CREATE TABLE t_sort_bad (
device_id int NOT NULL,
ts timestamptz NOT NULL,
site_id int NOT NULL,
status smallint NOT NULL,
v1 double precision NOT NULL,
v2 double precision NOT NULL,
attrs jsonb NOT NULL
)
USING MARS3
WITH (compresstype=zstd,compresslevel=3,mars3options='prefer_load_mode=bulk')
ORDER BY (ts, device_id);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'device_id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE 然后生成原始数据源,同时往两张表里插入数据
DROP TABLE IF EXISTS t_src;
CREATE UNLOGGED TABLE t_src AS
WITH
dev AS (
SELECT d AS device_id,
(d % 200) AS site_id,
(1000 + (d % 500))::double precision AS base
FROM generate_series(1, 10000) AS d
),
pts AS (
SELECT device_id, site_id, base,
g AS seq,
(timestamp '2026-01-01' + (g || ' seconds')::interval) AS ts
FROM dev
CROSS JOIN generate_series(1, 1000) AS g
)
SELECT
device_id,
ts,
site_id,
-- status:每 300 秒变一次段,形成长 run
((seq / 300) % 4)::smallint AS status,
-- v1/v2:设备基线 + 小波动
(base + (seq % 10) * 0.1)::double precision AS v1,
(base * 0.1 + (seq % 20) * 0.01)::double precision AS v2,
-- attrs:key 模式高度相似,但值随设备/时间变化
jsonb_build_object(
'fw', '1.2.' || (device_id % 10),
'model', 'm' || (device_id % 50),
'tag', 'S' || site_id,
'k', seq % 5
) AS attrs
FROM pts;
INSERT INTO t_sort_good SELECT * FROM t_src;
INSERT INTO t_sort_bad SELECT * FROM t_src;为了确保数据的准确性,插入完成后执行多次 vacuum full + vacuum
adw=# select segid,level,total_nruns,visible_nruns,invisible_nruns,level_size from matrixts_internal.mars3_level_stats('t_sort_good') where level_size '0 bytes';
segid | level | total_nruns | visible_nruns | invisible_nruns | level_size
-------+-------+-------------+---------------+-----------------+------------
0 | 1 | 1 | 1 | 0 | 8839 kB
1 | 1 | 1 | 1 | 0 | 8933 kB
3 | 1 | 1 | 1 | 0 | 8552 kB
2 | 1 | 1 | 1 | 0 | 8728 kB
(4 rows)
adw=# select segid,level,total_nruns,visible_nruns,invisible_nruns,level_size from matrixts_internal.mars3_level_stats('t_sort_bad') where level_size '0 bytes';
segid | level | total_nruns | visible_nruns | invisible_nruns | level_size
-------+-------+-------------+---------------+-----------------+------------
0 | 2 | 1 | 1 | 0 | 26 MB
1 | 2 | 1 | 1 | 0 | 26 MB
3 | 2 | 1 | 1 | 0 | 25 MB
2 | 2 | 1 | 1 | 0 | 25 MB
(4 rows)
adw=# \dt+ t_sort_bad
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+------------+-------+---------+---------+--------+-------------
public | t_sort_bad | table | mxadmin | mars3 | 103 MB |
(1 row)
adw=# \dt+ t_sort_good
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+-------------+-------+---------+---------+-------+-------------
public | t_sort_good | table | mxadmin | mars3 | 35 MB |
(1 row)
adw=# select * from t_sort_good limit 10;
device_id | ts | site_id | status | v1 | v2 | attrs
-----------+------------------------+---------+--------+--------+--------------------+-----------------------------------------------------
3 | 2026-01-01 00:00:01+08 | 3 | 0 | 1003.1 | 100.31000000000002 | {"k": 1, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:02+08 | 3 | 0 | 1003.2 | 100.32000000000001 | {"k": 2, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:03+08 | 3 | 0 | 1003.3 | 100.33000000000001 | {"k": 3, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:04+08 | 3 | 0 | 1003.4 | 100.34000000000002 | {"k": 4, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:05+08 | 3 | 0 | 1003.5 | 100.35000000000001 | {"k": 0, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:06+08 | 3 | 0 | 1003.6 | 100.36000000000001 | {"k": 1, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:07+08 | 3 | 0 | 1003.7 | 100.37 | {"k": 2, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:08+08 | 3 | 0 | 1003.8 | 100.38000000000001 | {"k": 3, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:09+08 | 3 | 0 | 1003.9 | 100.39000000000001 | {"k": 4, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:10+08 | 3 | 0 | 1003 | 100.4 | {"k": 0, "fw": "1.2.3", "tag": "S3", "model": "m3"}
(10 rows)
adw=# select * from t_sort_bad limit 10;
device_id | ts | site_id | status | v1 | v2 | attrs
-----------+------------------------+---------+--------+--------+--------------------+-------------------------------------------------------
1 | 2026-01-01 00:00:01+08 | 1 | 0 | 1001.1 | 100.11000000000001 | {"k": 1, "fw": "1.2.1", "tag": "S1", "model": "m1"}
12 | 2026-01-01 00:00:01+08 | 12 | 0 | 1012.1 | 101.21000000000001 | {"k": 1, "fw": "1.2.2", "tag": "S12", "model": "m12"}
15 | 2026-01-01 00:00:01+08 | 15 | 0 | 1015.1 | 101.51 | {"k": 1, "fw": "1.2.5", "tag": "S15", "model": "m15"}
20 | 2026-01-01 00:00:01+08 | 20 | 0 | 1020.1 | 102.01 | {"k": 1, "fw": "1.2.0", "tag": "S20", "model": "m20"}
23 | 2026-01-01 00:00:01+08 | 23 | 0 | 1023.1 | 102.31000000000002 | {"k": 1, "fw": "1.2.3", "tag": "S23", "model": "m23"}
35 | 2026-01-01 00:00:01+08 | 35 | 0 | 1035.1 | 103.51 | {"k": 1, "fw": "1.2.5", "tag": "S35", "model": "m35"}
38 | 2026-01-01 00:00:01+08 | 38 | 0 | 1038.1 | 103.81000000000002 | {"k": 1, "fw": "1.2.8", "tag": "S38", "model": "m38"}
40 | 2026-01-01 00:00:01+08 | 40 | 0 | 1040.1 | 104.01 | {"k": 1, "fw": "1.2.0", "tag": "S40", "model": "m40"}
44 | 2026-01-01 00:00:01+08 | 44 | 0 | 1044.1 | 104.41000000000001 | {"k": 1, "fw": "1.2.4", "tag": "S44", "model": "m44"}
47 | 2026-01-01 00:00:01+08 | 47 | 0 | 1047.1 | 104.71000000000001 | {"k": 1, "fw": "1.2.7", "tag": "S47", "model": "m47"}
(10 rows) 简而言之
t_sort_good 把相似的数据放在一起,于是同一批落盘的数据更规律、更重复,压缩器更容易工作; t_sort_bad 把完全不同的数据混在一起,于是每一批落盘的数据更杂、更随机,压缩器很难压缩。
同样的数据量,只是排序键不同:
t_sort_good 总大小 35 MB,
t_sort_bad 总大小 103 MB (约 3 倍)
从 run/level 统计看:每个 seg 都只有一个 run,但:
t_sort_good 的 run 在 level 1,每 seg 大约 8.5–8.9 MB
t_sort_bad 的 run 在 level 2,每 seg 大约 25–26 MB
对于 t_sort_good 来说,按 (device_id, ts) 排序 → 相似聚集 → 压缩友好,这样在同一个 stripe/块里,往往是“同一个设备的一段连续时间”。这会带来:
device_id/site_id/status 这些列会出现长段重复 (很适合 RLE/字典编码)
ts 和 v1/v2 这种随时间缓慢变化的列,块内增量很小 (很适合 delta/bitpacking)
attrs(jsonb) 的 key 模式在同设备内高度相似(对 zstd/lz4 也更友好)
因此,同样的行数,物理字节会明显更小。
对于 t_sort_bad 来说,按 (ts, device_id) 排序 → 设备混杂 → 压缩不友好,同一个时间点会混进大量设备,导致同一块里:
device_id 几乎每行都变化 (字典更大、RLE 段长度接近 1)
site_id/status 也会被打散 (run-length 被破坏)
attrs 的组合模式更杂 (重复片段减少)
即使 ts 是递增的,但其它列的“随机性”把整体压缩收益吃掉了
所以压缩比显著变差,物理大小变成 3 倍非常正常。
换句话说:坏排序不仅更大,还更难治理,到了更高层才稳定下来。
在 MARS3 中,排序键决定了数据在落盘单元 (run/stripe) 内的相似性。相似数据聚集时,块内的值域更窄、重复更集中,字典/RLE/delta 以及通用压缩都能充分发挥,最终得到更小的物理占用;相反,排序键导致数据混杂时,块内分布更散、重复被打碎,压缩与编码效率显著下降,甚至会增加后台整理的难度与成本。
Unique Mode 是 MARS3 为特定写入模型提供的一种模式:把“更新某条记录”的需求,转换为“按唯一键再次插入一条新记录”,由引擎自动完成同一键值下的新旧版本替换。它的核心价值是让业务在高频写入场景中,用更简单、更统一的写入方式 (INSERT) 表达更新语义,减少显式 UPDATE 的使用与代价,并保持数据组织在持续写入下更可控。
适用场景:
按实体键持续写入最新状态:实体 (设备/车/用户/订单) 维度强、反复写同一键的最新值
写入高频、小批次:希望写路径简单、稳定、可持续
查询以最新值/最新快照为主:例如最新状态看板、最新告警态、最新指标面板
不依赖物理删除语义:业务侧不需要频繁 DELETE (或可以用其他方式表达无效/过期)
在 Unique Mode 下,唯一键由建表时的排序键 ORDER BY (...) 定义:当你插入一条与已有记录 相同 Unique Key 的新数据时,引擎会将其视为对该键对应数据的更新,无需显式执行 UPDATE,直接 INSERT 即可完成更新语义。与传统的 upsert (insert .. on conflict) 不同,Unique Mode 是读时合并,数据在写入的时候依旧会写入到存储中,读取的时候通过一定的版本链和可见性规则确保读取的是最新的数据,并通过 compact 移除重复数据;upsert 则是写时合并,在写入时,即检查是否可能会重复,有额外的写入开销。
这种预检查可以避免将元组插入堆中,在元组重复的情况下再将其删除的开销。
HEAP_INSERT_IS_SPECULATIVE 即所谓的“speculative insertion” —— 推测性插入,如果发现冲突,直接撤消,而无需取消整个事务。其他会话可以等待推测性插入得到确认,将其变成常规元组,或者取消。
因此,Unique Mode 的写入效率会远高于传统 upsert 的方式,根据测试表明,Unique Mode 的性能大约是传统 upsert 的 1.5 倍。
在 Unique Mode 的同键再次写入场景中,标量列采用新值覆盖旧值的默认行为;但当某列为 JSONB 类型时,引擎支持增量合并语义:新版本的 JSONB 值不是直接写入,而是按以下规则得到:new_jsonb = jsonb_concat(old_jsonb, incoming_jsonb),数据库内部会直接调用 jsonb_concat 实现合并,比如:
postgres=# SELECT jsonb_concat('[1,2]'::jsonb, '[2,3]'::jsonb);
jsonb_concat
--------------
[1, 2, 2, 3]
(1 row)
postgres=# SELECT jsonb_concat('{"k":1,"x":2}'::jsonb, '{"k":null}'::jsonb);
jsonb_concat
---------------------
{"k": null, "x": 2}
(1 row)
postgres=# SELECT jsonb_concat('{"a":1,"b":2}'::jsonb, '{"b":99,"c":3}'::jsonb);
jsonb_concat
---------------------------
{"a": 1, "b": 99, "c": 3}
(1 row) 这样当业务使用 JSONB 承载动态属性/扩展字段/标签等信息时,可以只写入增量 JSONB,由引擎完成合并,避免应用层读旧值合并然后写回的额外复杂度与并发冲突。
数组合并的幂等性风险:JSONB array 追加且不去重,若写入有重试/重放可能导致重复元素累积。建议避免把事件明细长期追加在 array 中;需要幂等时可引入 event_id 并在上层保证不重复,或改用 object/map 结构按 key 覆盖。
JSONB 增长治理:JSONB 合并会让字段逐步变大,可能推高读取成本与后台治理压力。建议对 JSONB 做容量治理 (裁剪、拆表、分桶、只保留最近 N 条等)。
null 不等于删除:{"k": null} 会把 k 设置为 null,不会删除该 key;如需删除语义需另行设计 (例如专用标记字段/单独删除表/业务侧约定)。
为什么要做 UpdateChain:解决并发更新同一行时的正确性。对于 PG Heap 的更新不是原地改一行,而是旧 tuple 标记删除 + 插入新 tuple,并用 ctid 把旧版本指向新版本,形成一条 update chain。
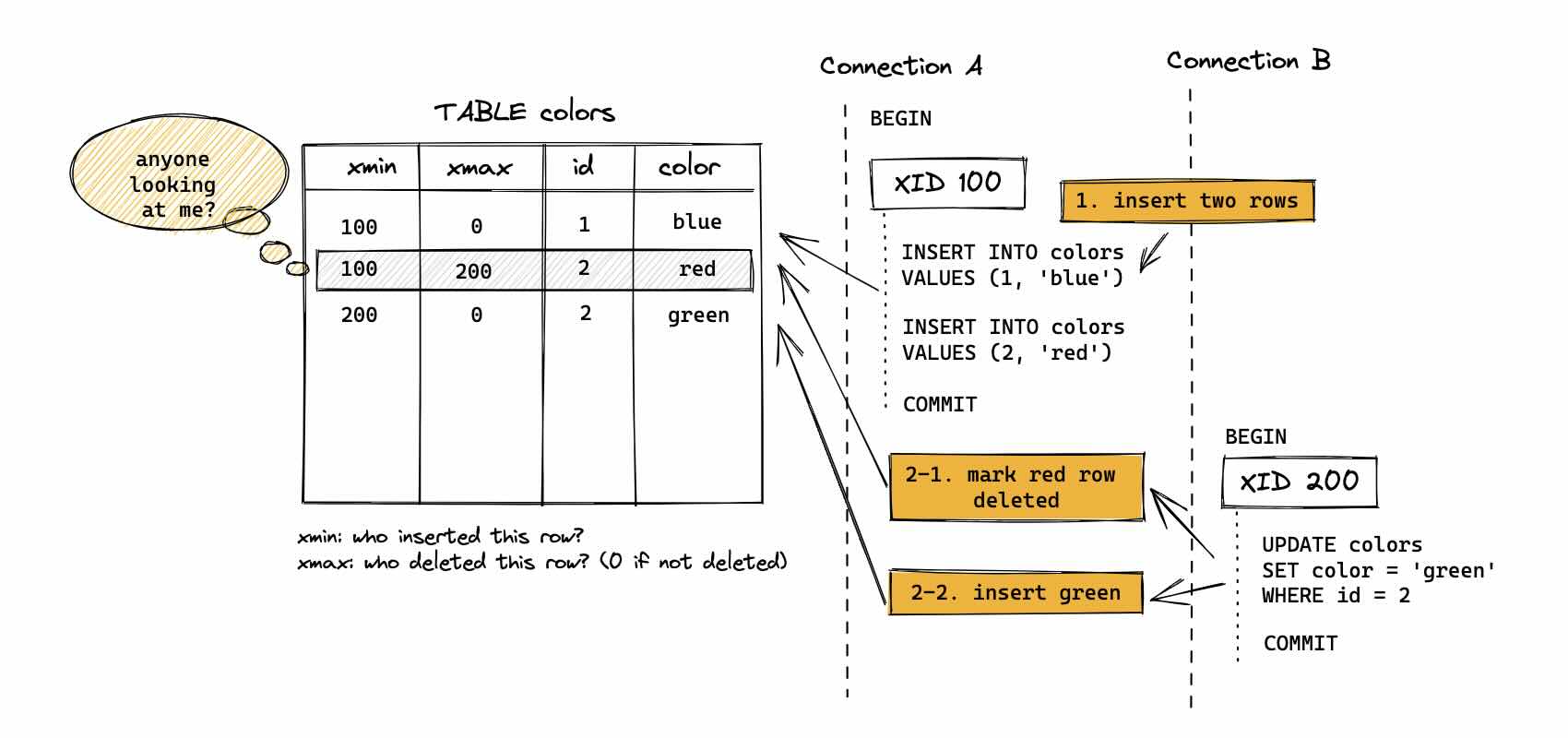
而对于 MARS3,MARS3 的删除/更新不是像 Heap 那样把 xmax 写在 tuple header,而是把类似的“删除/更新标记”写到 Delta 文件;同时为了保证 compaction/flush 后这些信息不丢,还需要 Link 文件。Heap 的 xmax/删除信息在 MARS3 里存 Delta,Link 确保 compaction 过程中 delete 信息不丢失。
因此,
Heap:版本链主要靠 tuple header + ctid 链 (数据本体里就带着版本指针)
MARS3:版本/删除语义被外置到 Delta + Link 这种旁路结构里,因此正确性依赖的不只是数据文件,还依赖Delta/Link 在 flush/compaction/vacuum 中不丢、不乱、不破链。
早期 MARS3 在同一行并发更新场景下会直接报错退出,没有 UpdateChain 的支持,无法确保结果的并发正确性;引入 UpdateChain 后,通过 TupleLock 对逻辑行加锁,并沿 update-chain 定位最新版本,使并发更新按顺序推进,从而保证 Update 语义正确性。
和 PostgreSQL 类似,在 YMatrix 中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组的多版本形式来实现的:
MARS3 的更新和删除操作都不是采用原地修改数据的方式,而是依靠 DELTA 文件和版本信息屏蔽掉了老数据,从而控制数据的可见性
MARS3 通过 DELETE 进行删除,删除会在对应 Run 的 Delta 文件中进行记录,在进行 Run 合并的时候真正把数据删除
MARS3 通过 UPDATE 进行更新,更新会先删除原本数据,再重新插入一条新数据
更新和删除过程中产生的死元组 (invisible runs) 会由后台进程 autovacuum 定时清理,也可以手动执行 vacuum 进行清理,另外在 compact 的过程中,随着小的 Run 合并为一个新的更大的 Run,invisible runs 也会被清理掉。vacuum full 则更进一步,它会将多个小的 Run 合并成一个大的 Run。如果没有新的写入操作发生,运行一次 vacuum full 通常会尽可能地合并这些批次,直到无法再进行合并为止。最终,剩余的每个批次的大小将约等于 max_runsize 的设定值 (注意,vacuum full 的过程中也可能会产生 invisible runs)。
简而言之:
vacuum 是 flush + 移除 invisible runs,并且会把 rowstore 刷下去
vacuum full 在 vacuum 的基础上还会做合并






