
真实世界里,客户的数据系统很少是纯 OLTP 或纯 OLAP。在混合负载下,传统存储体系往往会自然分裂:有的引擎擅长扫描与压缩,却难以长期承受频繁的小写与更新;有的引擎写得快、点查稳,却在全表扫描与聚合上成本高、效率低;而当我们试图把多套系统拼装成所谓的 HTAP,又会引入数据新鲜度、资源隔离、运维复杂度与总体成本的问题。因此我们研发了 MARS3:一款面向 AP 核心混合负载的存储引擎,其目标不是万能替代一切,而是把客户最常见、最关键的混合工作负载放在同一套可治理的存储体系里,通过可解释的机制让性能与稳定性在高压下稳固可控。
如果你是做选型与方案的同学,建议优先阅读第 1–2 章把握适配边界;如果你是架构师或 DBA,建议重点关注第 3–6 章理解机制与代价;如果你负责交付与运维,第 7 章会提供从症状到处置的快速路径与模板。 MARS3 面向的是以 AP 为核心的混合负载 —— 优先保证扫描与聚合效率、持续写入下的稳定性,以及常见场景下的明细回查体验;但 MARS3 并不追求在所有维度都达到极致,例如对极端纯 TP、超高频大范围更新等负载。
在大多数客户系统里,“数据”不是先写完再分析,而是一边写、一边用,业务对于实时性的要求愈发严苛。业务侧希望数据尽可能新:生产线的设备数据写入后要立刻形成产线看板,车联网的车辆状态更新后要马上触发告警与分析,IoT 平台的传感器数据进入系统后要实时支撑趋势分析与异常检测;与此同时,运营与研发同学还需要随时做明细回查,比如定位某台设备、某辆车、某个工位在某个时间段的原始记录等,并在此基础上做聚合统计、相关性分析或多表关联。 这类场景的共同点是:负载是混合的,而且是分析为主、写入不断的混合场景。写入侧既可能是批量导入 (历史回溯、日批结算),也可能是持续微批 (T+0、分钟级聚合),甚至包含零散点写与修正;查询侧既有全局汇总报表,也有带条件过滤的扫描,还有对单实体的高频回查。 因此,这个矛盾的本质不是写得快或查得快二选一,而是在持续写入与持续分析并存时,系统能否既保持分析效率,又保持高效稳定的写入效率。
在混合负载里,问题往往不是某个系统好或坏,而是不同存储形态天生擅长的方向不同。
行存是传统数据库最经典的存储方式,比如 PostgreSQL、MySQL 等,它将每一行完整的数据打包放在一起,像一个个“整箱快递”。特点是一行数据,整体存放。以行存/事务路径为优势的系统对明细回查、按主键/条件取少量记录来说很合适;但一旦进入分析型查询 (只用到少数几列、需要扫大量数据做过滤/聚合),系统往往不得不把整行数据读出来,哪怕其中大部分列根本用不上。结果就是:
· 读了很多不需要的列,磁盘与缓存带宽被占用;
· 扫描与聚合变慢,同样的分析要耗更多资源;
· 数据量越大,这种无效 I/O 越明显,成本也越高。
列存为了获得高效扫描与高压缩比,通常需要更强的数据组织与元数据维护:数据被按列分块存放,并依赖编码、字典、统计信息等来提升处理效率,比如 Clickhouse、Hbase 等。在这种架构下,写入往往不仅是追加记录这么简单,还涉及更多结构化维护:
· 写放大:一次逻辑写入可能引入多处物理写 (多列块、元数据等),并在后台通过合并/重写来维持数据组织质量;
· 小批次写入的放大效应:当写入变成高频微批或持续小批量时,单位数据量分摊到每次写入的固定开销更高,合并/重写更频繁,容易在长期运行中形成更高的维护压力;
· 与更新删除的耦合:列存对 UPDATE/DELETE 往往通过版本/标记/重写来收敛碎片,若更新删除比例上升,后台治理不足时会出现空间放大与读路径变长 (需要处理更多无效版本/碎片块)。
因此,列存非常适合以读为主的大扫描分析,但在混合负载下,对写路径与后台治理的要求显著更高。
把写入放一套系统、分析放另一套系统,再通过同步/ETL 串起来,理论上能同时获得两边的优点;但现实里常见的代价是:数据要“搬家”,链路越长越难做到足够新;系统越多,口径一致、补数对账、故障恢复、权限与监控就越复杂,整体成本也会更高。
从客户需求表面看,“既要写得快、又要查得快、还要成本低”似乎是一个天然矛盾。但从工程角度,混合负载并不是平均分布的:在大多数业务里,系统的核心价值仍然体现在分析结果的产出 (报表、指标、诊断、洞察),而写入与明细回查更多是为了保证数据持续进入、随时可用。因此,MARS3 的设计取舍是明确的:面向混合负载,但将 AP 设为主战场,并围绕持续写入下的分析效率与稳定性建立一套可治理的存储体系:
1.在数据规模增长与并发上升时,系统应能以更少的无效 I/O、更好的跳读效果和更高的吞吐完成分析查询;在资源使用上追求“单位资源产出最大化”,让大盘类查询和周期性统计更可控。
2.支持从批量导入到持续微批 (T+0) 的多种写入形态,重点保障“写入不断、查询不断”的常态下系统依然可预测;后台整理 (如合并/回收等) 必须是可治理的,而不是把压力随机抛给线上查询。
3.面向真实业务里常见的单实体回查、时间范围查询、按条件过滤取数等需求,提供足够好的访问路径与体验,避免出现“分析很强但回查体验割裂”的系统落差。
MARS3 采用 LSM-Tree 风格的数据组织:写入侧快速吸收与顺序落盘,读取侧强调有序数据带来的跳读与扫描效率,中间由后台治理进程将写友好逐步演进为读友好。
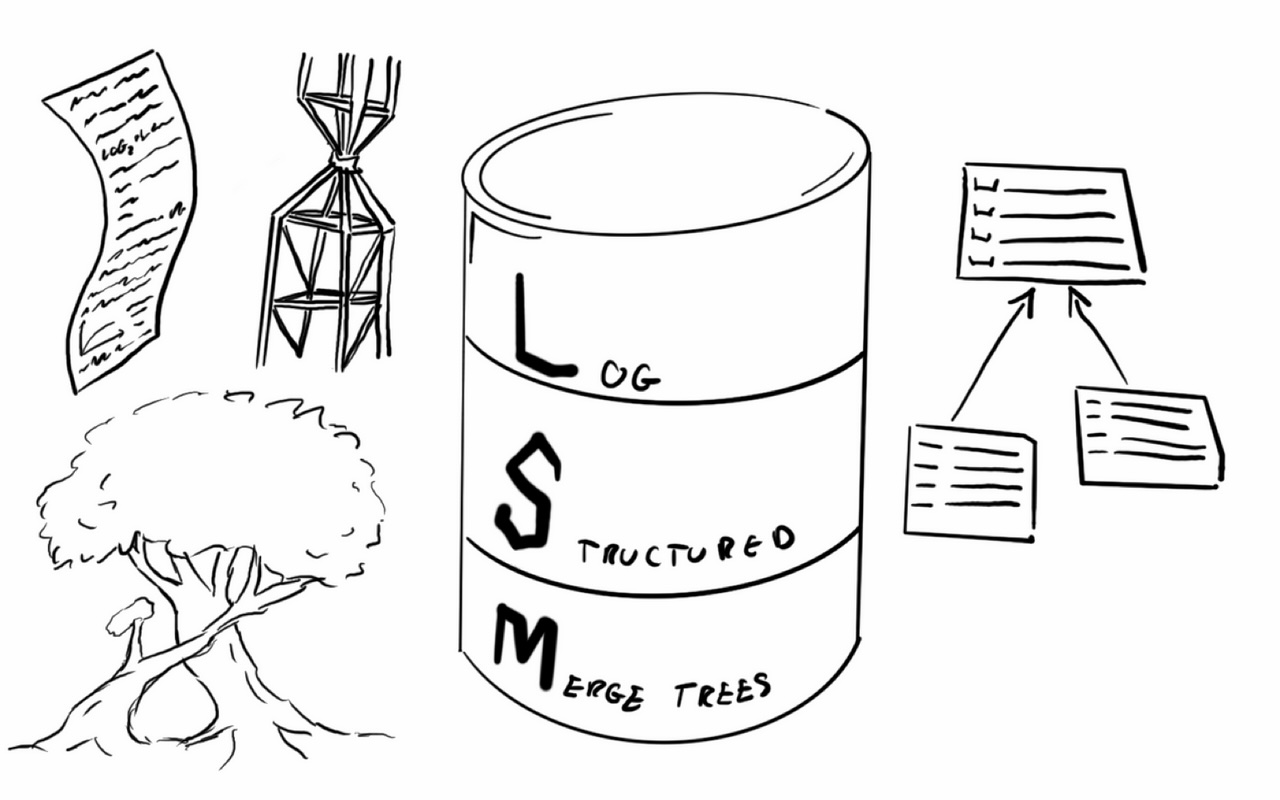
在这个体系里,有三个核心对象:Run 与 Level (决定数据如何分段与分层)、行存与列存 (数据的物理布局如何在写与读之间做平衡)、以及 Delta 与 MVCC (更新删除如何表达、为何会带来放大、如何被回收),接下来将依次进行介绍。
MARS3 中存储的数据是有序的,一段连续有序的数据我们称为 Run。
在 Rocksdb/ Leveldb 等产品对内部数据有序的文件称呼为 SST,在 YMatrix 中,RUN 是 SST 的另一种叫法在 Rocksdb/ Leveldb 等产品对内部数据有序的文件称呼为 SST,在 YMatrix 中,RUN 是 SST 的另一种叫法
Run 分成两种,为了能够高速写入,插入的数据会以行存 Run 的形式储存下来,之后为了方便读取和压缩,我们会把行存 Run 转换成列存 Run。单个 Run 有大小上限:
表级参数 max_runsize,在建表时用于指定单个 RUN 的最大大小,最大 16384 MB
默认为 4096 MB
我们可以使用 matrixts_internal.mars3_files 函数用来查看 MARS3 表的扩展文件和增量文件,主要包括 DATA、LINK、FSM、DELTA,如果表上有索引,还会有相应的 INDEX 文件:
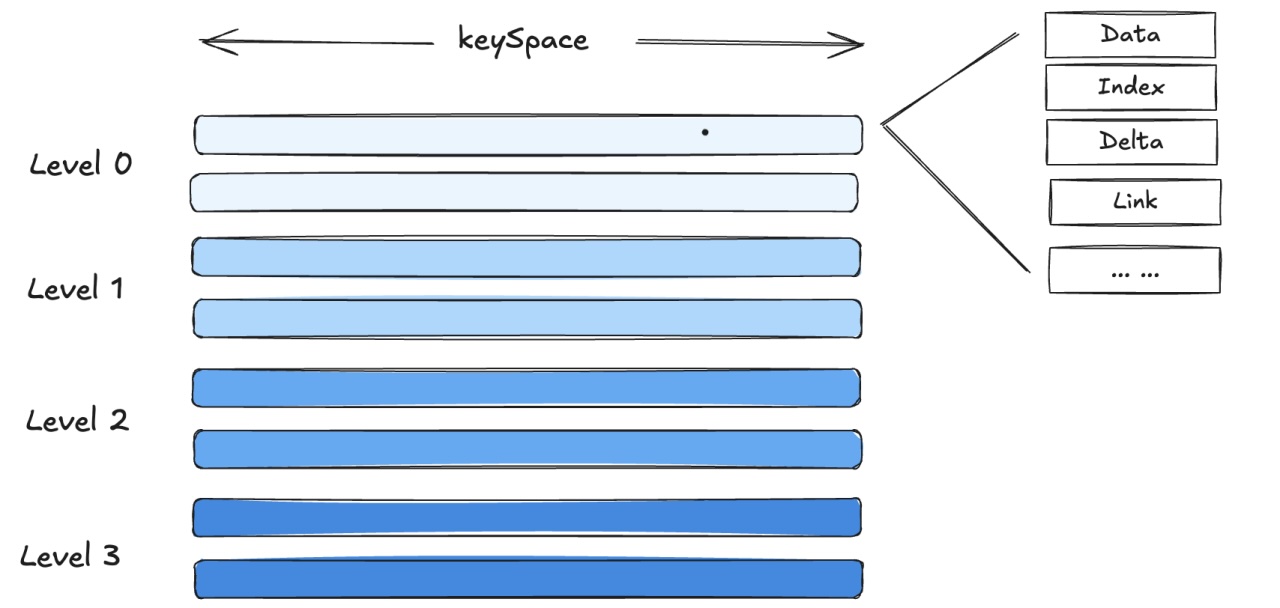
DATA:主要的数据文件,用于存储用户数据
FSM:Free Space Map 的缩写,在 YMatrix 中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组的多版本形式来实现的,因此会导致“过期数据”的问题,即当一个版本的元组对所有事物都不可见时,那么它就是过期的,此时其占用的空间是可以被释放的,FSM 文件用于追踪这些可用空间,并在需要的时候能够高效地分配出去
LINK:在更新和删除操作中,用于维护 compact 中元组版本上下游关系的信息
DELTA:用于存储删除信息,MARS3 的更新和删除操作都不是采用原地修改数据的方式,而是依靠 DELTA 文件 (XMAX 等删除信息) 和版本信息屏蔽掉了老数据,从而控制数据的可见性
INDEX 和 INDEX_1_TOAST:用于存储索引文件,当前 MARS3 支持 BRIN 和 BTREE 索引
postgres=# select * from matrixts_internal.mars3_files('test');
segid | level | run | file | seq | path | bytes
-------+-------+-----+---------------+-----+----------------------------+---------
1 | 0 | 1 | DATA | 0 | base/14011/235713_meta_1.2 | 1081344
1 | 0 | 1 | DELTA | 0 | base/14011/235713_meta_1 | 32768
1 | 0 | 1 | LINK | 0 | base/14011/235713_meta_1.1 | 0
1 | 0 | 1 | FSM | 0 | base/14011/235713_meta_1.3 | 131072
1 | 0 | 1 | INDEX_1 | 0 | base/14011/235713_meta_1.4 | 65536
1 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/235713_meta_1.5 | 0
2 | 0 | 1 | DATA | 0 | base/14011/253866_meta_1.2 | 1081344
2 | 0 | 1 | DELTA | 0 | base/14011/253866_meta_1 | 32768
2 | 0 | 1 | LINK | 0 | base/14011/253866_meta_1.1 | 0
2 | 0 | 1 | FSM | 0 | base/14011/253866_meta_1.3 | 131072
2 | 0 | 1 | INDEX_1 | 0 | base/14011/253866_meta_1.4 | 65536
2 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/253866_meta_1.5 | 0
3 | 0 | 1 | DATA | 0 | base/14011/243459_meta_1.2 | 1081344
3 | 0 | 1 | DELTA | 0 | base/14011/243459_meta_1 | 32768
3 | 0 | 1 | LINK | 0 | base/14011/243459_meta_1.1 | 0
3 | 0 | 1 | FSM | 0 | base/14011/243459_meta_1.3 | 131072
3 | 0 | 1 | INDEX_1 | 0 | base/14011/243459_meta_1.4 | 65536
3 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/243459_meta_1.5 | 0
0 | 0 | 1 | DATA | 0 | base/14011/238674_meta_1.2 | 1081344
0 | 0 | 1 | DELTA | 0 | base/14011/238674_meta_1 | 32768
0 | 0 | 1 | LINK | 0 | base/14011/238674_meta_1.1 | 0
0 | 0 | 1 | FSM | 0 | base/14011/238674_meta_1.3 | 131072
0 | 0 | 1 | INDEX_1 | 0 | base/14011/238674_meta_1.4 | 65536
0 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/238674_meta_1.5 | 0
(24 rows) MARS3 基于 LSM-TREE 组织数据,各个 Run 文件被组织到 Level 中,最大可有 10 层:L0,L1,L2......L9。每一层的 Run 个数达到一定数目,或者同一层多个 Run 的大小总和达到阈值都会触发合并,合成一个 Run 后升级到更高层去;并且为了加快 Run 的升级,允许同一层中同时进行多个合并任务。
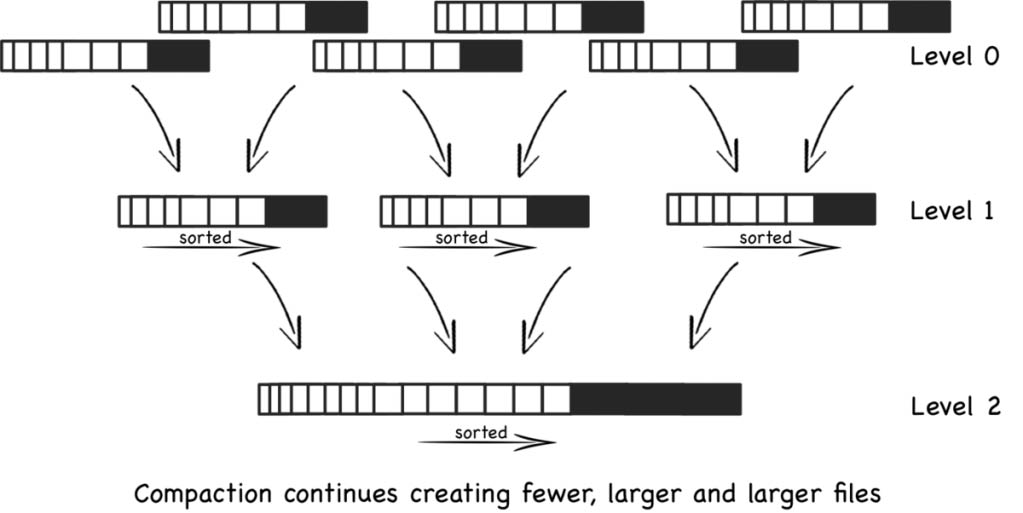
在 YMatrix 中,有一定数量的后台合并进程会周期性地检测各个表的状态,并执行合并操作。
YMatrix 提供了 matrixts_internal.mars3_level_stats 实用函数用于查看 MARS3 表中每个层级的状态。此操作对于评估表的健康状况非常有用,比如检查 Runs 是否按预期合并,是否有过多不可见的 Runs,以及运行次数 Run counts 是否在正常范围内。
postgres=# select * from matrixts_internal.mars3_level_stats('test') limit 10;
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
1 | 0 | 1 | 1 | 0 | 0 | 0 | 1280 kB
1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 6 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 7 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 8 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(10 rows) 按照经验法则:
当 level =0 时,若 runs 数大于 3,则状态不健康。
当 level = 1 时,若 runs 数大于 50,则状态不健康。
当 level > 1 时,若 runs 数大于 10,则状态不健康。
columnstore 都是直接写直接读,没有类似 Shared Buffers 这样的缓冲层,也没有页面刷新。
每 compress_threshold (默认为 1200) 行的数据,我们称为一个 Range;一个 Range 内的某一列数据 (包含 compress_threshold 行),称之为 stripe;这一列数据如果特别大,那么 stripe 会切成若干个 1MB 的 chunk,读的时候也不会一下读整个 compress_threshold 的数据出来。
RUN
└── range(按行切分,默认每 1200 行一个range)
├── column1 stripe(1200 个 datum)
├── column2 stripe(1200 个 datum)
├── column3 stripe(1200 个 datum)
└── ...range 是逻辑行窗口:每 1200 行组成一个 range,range 内部以列存格式存储,按列压缩
stripe 是物理列块:某一列在这个 1200 行范围内的连续存储块
datum 是最小值单元:一行某一列的值 (PG 内核原生单位)

混合负载的现实要求是:写入往往以小批次或持续微批发生,但分析查询又希望以列式方式高效扫描。MARS3 的思路是把这两类诉求放在同一套体系里,通过行存与列存的组合在不同阶段承担不同职责:
行存形态更偏写入与新鲜数据访问:它更容易快速接收新数据,也更适合小范围读取与明细回查 (尤其是数据刚写入、尚未完成整理时)。
列存形态更偏扫描与聚合:当数据经过整理,列存能显著提升扫描吞吐与压缩效率,使大范围聚合、过滤查询更省资源。
所谓“先行后列”,本质就是让数据在生命周期里先以更适合写入的形态进入系统,再在后台治理中逐步转为更适合分析的形态,从而实现“写入不断、分析不断”的常态运行。为了适应不同场景的需求,在 YMatrix 中支持三种写入模式,由表级参数 prefer_load_mode 和 rowstore_size 共同决定:
Normal:表示正常模式,新写入数据先写到 L0 层的行存 Run 中,积累到 rowstore_size 之后,落至 L1 层的列存 Run,相对于 bulk 模式会多一次 I/O,列存转换由同步变成了异步,但适用于 I/O 能力充足且对延迟敏感的高频次小批量写入场景;
Bulk:批量加载模式,适用于低频大批量写入场景,直接写至 L1 层的列存 Run,相对于 normal 模式,减少了一次 I/O,列存转换由异步变成了同步,适用于 I/O 能力不足且对延迟不敏感的低频大批量的数据写入
Single:数据直接插入到 rowstore,元组被直接放置在 Shared Buffers 中。
更多详细内容可以参照第4章写路径总览。
目前 MARS3 目前支持 BRIN 和 BTREE 索引,BTREE 适合以“精确查找”为核心的事务型系统,通过行级指针实现快速定位;而 BRIN 适合以“范围扫描”为主的大规模分析型系统,通过块级摘要显著减少无效 IO。值得注意的是,对于 MARS3 表,当前一个表上最多允许 16 个索引 (不管是否是同一个列,不管是 BRIN 还是 BTREE),超过就会提示:ERROR: IndexBuild error: too many indexes (index_am.h:162)。
BRIN 是一种面向超大规模数据表的轻量级范围摘要索引,它不直接指向具体行,而是为连续的数据块范围维护最小值、最大值等统计信息,用于在查询阶段快速裁剪不可能命中的数据块区域,从而显著减少扫描 IO。
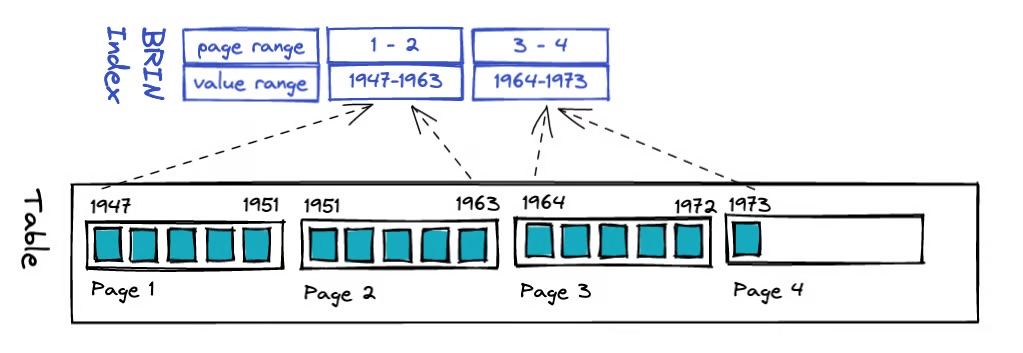
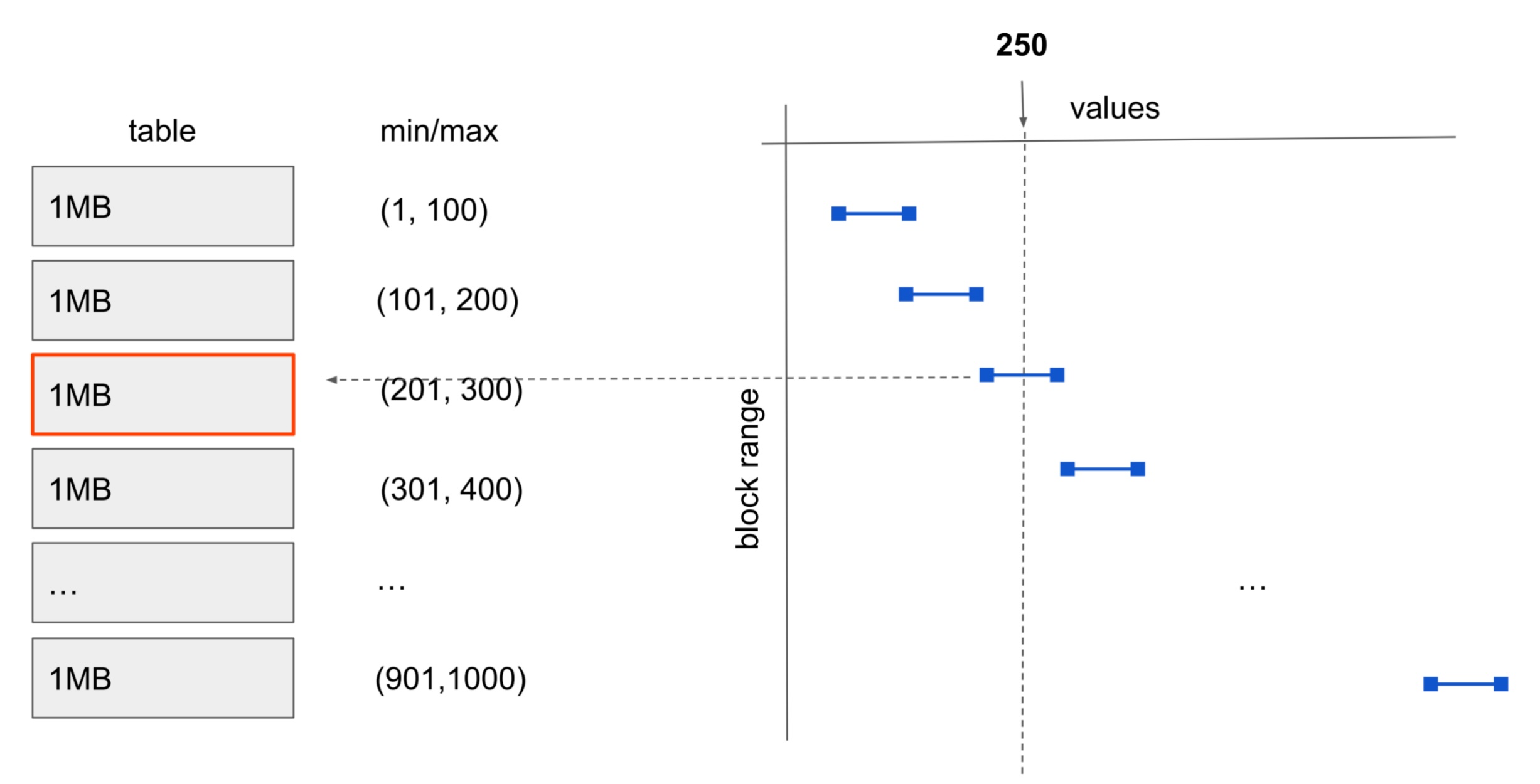
BRIN 的空间占用极小、构建和维护成本极低,但查询效果强依赖数据在物理层面的有序性,当数据按时间戳或递增键顺序写入时,可在时序分析和日志类场景中获得接近分区裁剪级别的扫描效率,是分析型大表的重要索引补充方案,比如如下条件,检索 250 这条数据可以快速定位到位于第三个数据块中:
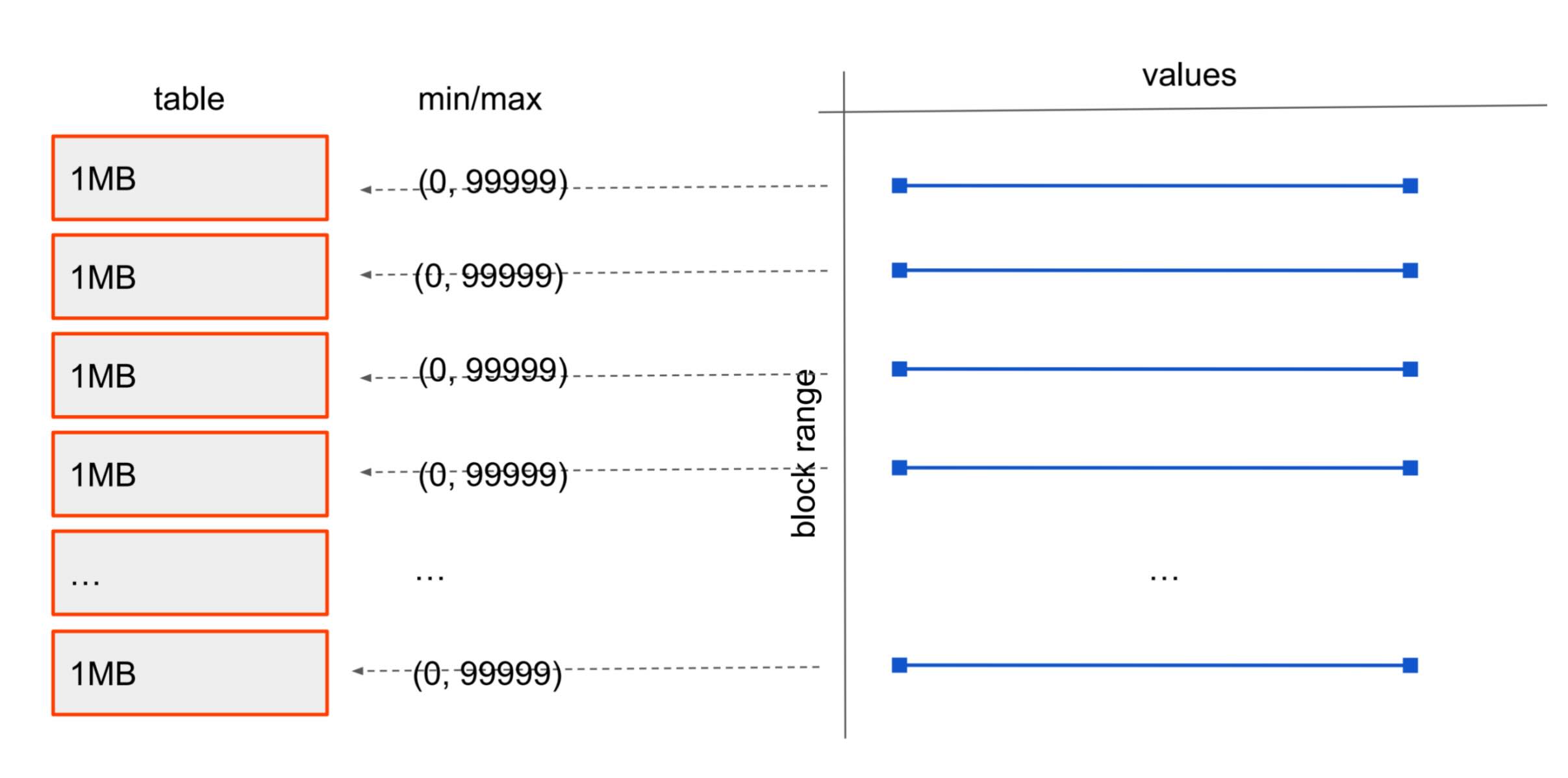
由于 BRIN 这种数据结构的特殊性,核心思想不是“给每一行建索引”,而是:给一段连续数据块维护摘要信息,因此 BRIN 不适用于随机物理分布的数据,以及高更新、频繁乱序更新的场景,在这种情况下,会退化为顺序扫描,每个数据块都需要进行扫描。
在 YMatrix 中,还支持 Default BRIN。
BTREE 索引是一种基于平衡多叉树结构的通用型索引,通过按键值有序组织索引节点,实现对单行或小范围数据的快速精确定位,查询复杂度稳定在 O(logN),既支持等值查询,也高效支持范围扫描与排序操作。由于其不依赖数据物理分布特性,BTREE 在高并发事务处理场景下具备极强的稳定性,是主键、唯一约束及高选择性查询的默认首选索引类型,但是不适用于低选择性列和大表的宽范围扫描。
mars3btree 是 MARS3 存储引擎里专用的 B-tree 实现,索引的内部页仍是标准 B-tree 页面,mars3btree 支持两种类型:
NORMAL:标准行式 B-tree (用于RowStore),不压缩
COMPRESSED:列式压缩 B-tree (用于ColumnStore),压缩
对于列式压缩 BTREE,整体架构如下:
Min/Max 元信息:构建时维护 min/max,并写入 metapage;作用是:在真正下探 btree 之前,可以先用查询条件做全局剪枝:相当于给索引再加一层超轻量目录,如果查询条件落在 min/max 之外,直接判定索引不可能命中。
Bloom Filter:仅对唯一/主键索引构建,并且限制在 1000 万条以内,对唯一/主键索引的点查或是否存在类查询:Bloom 能快速判定不可能命中,减少不必要的 leaf 读取与解压。
Fast Path Check:ColumnStore 才启用,失败则立即返回 nullptr,把是否值得解压叶子变成一个极轻的检查 (min/max + bloom),不命中则零解压、零 leaf 读取
关于 mars3btree 索引压缩语法参照索引压缩章节。
和 PostgreSQL 类似,在 YMatrix 中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组的多版本形式来实现的:
MARS3 的更新和删除操作都不是采用原地修改数据的方式,而是依靠 DELTA 文件和版本信息屏蔽掉了老数据,从而控制数据的可见性
MARS3 通过 DELETE 进行删除,删除会在对应 Run 的 Delta 文件中进行记录,在进行 Run 合并的时候真正把数据删除
MARS3 通过 UPDATE 进行更新,更新会先删除原本数据,再重新插入一条新数据
在 MARS3 中,排序键是决定引擎能否发挥扫描效率、能否长期稳定运行的核心设计点。有序数据 + 可靠的块级元数据可以大幅提升扫描效率,排序键选得好,数据在 Run 内以及更高层级中会呈现更强的局部性,查询的过滤条件更容易命中连续范围,跳读更有效;排序键选得不合理,数据分布会更“散”,过滤条件无法收敛扫描范围,系统会表现为“看似有索引/有元数据,但读起来还是像全扫”。
排序键带来的核心收益可以拆成五类
1、提升过滤与范围查询效率:当 WHERE 条件与排序键高度相关 (例如时间范围、设备 ID 范围等),数据在存储层呈现更强的聚集性,查询可以更早、更精准地跳过无关数据块,从而减少 I/O 和 CPU 处理量。
2、提升统计信息的“可靠性”与“可跳读性”:块级 min/max、BRIN 等元数据的价值依赖于数据分布。如果同一块里包含的键值跨度很大、或者分布被打散,min/max 覆盖范围会变宽,跳读会变“保守” (不得不读更多块)。良好的排序键能让每个块的值域更集中,从而让元数据更有判别力。
3、影响后台合并与长期运行成本:排序键也会影响 Run 的形态与合并效果:数据越有序、越聚集,合并后的 Run 越规整,空间与读路径更容易收敛;如果排序键导致数据“天然离散”,即使合并也难以形成良好的局部性,长期运行会更依赖更多的治理成本来维持体验。
4、影响压缩:压缩 (不管是 zstd/lz4 还是 RLE/dict/bitpack 这些编码) 都依赖一个核心事实:同一块/同一 stripe 内的数据越规律,压缩越好。当相近实体/相近时间的数据聚集在同一 stripe 内时,块内值域收敛、重复与成段重复增强,字典规模下降,delta/bitpacking 的 bit 宽度降低,从而提升编码与通用压缩的效果,具体验证效果可以参照排序键对于压缩的影响章节。
5、影响写入性能:参照排序键对于写入性能的影响章节。
用最常见、过滤效果最强的查询维度来组织数据。实践中,排序键的选择通常来自两个维度的组合:
时间维度 (Time):时序/日志/指标类负载几乎都会有时间范围过滤;
实体维度 (Entity):设备、车辆、用户、工位、站点等“单实体回查”的主键或高频过滤字段。
在排序键中,过滤条件中频繁使用的列应置于更靠前的位置。
法则 1:将 WHERE 过滤条件中出现频率最高的列作为排序键的最左前缀
法则 2:将高基数且高选择性的列置于排序键前端
法则 3:若使用 BRIN 索引,排序键中列的出现位置越靠前,其重要性越高 —— 因为该列对索引跳过无关数据的能力影响越大。
简而言之,让最常见的查询条件能够尽可能把扫描范围收敛到连续的、有聚集性的区间。
如下是一个真实的客户案例 —— 时序场景,查询样例如下:
SELECT time_bucket_gapfill ('5 min', time) AS bucket_time,
locf (LAST (value, time)) AS last_value,
locf (LAST (quality, time)) AS last_quality,
locf (LAST (flags, time)) AS last_flags
FROM
xxx
WHERE
id = '116812373032966284'
AND type = 'ANA'
AND time >= '2025-11-16 00:00:00.000'
AND time 、= 操作符的列创建 default_brin 索引;
- N :系统会自动为前N列中支持 、= 操作符的列创建 default_brin 索引。
```sql
postgres=# \d+ t_default
Table "public.t_default"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+--------+-----------+----------+---------+---------+--------------+-------------
c1 | bigint | | | | plain | |
c2 | bigint | | | | plain | |
c3 | bigint | | | | plain | |
Distributed by: (c1)
Access method: mars3
Options: mars3options=default_brinkeys=30, compresslevel=1, compresstype=zstd 我们可以使用 UDF 来检验哪些列有 Default Brin
CREATE FUNCTION matrixts_internal.mars3_brinkeys (IN r1 regclass, OUT nbrinkeys int, OUT brinkeys text)
RETURNS SETOF RECORD
AS '$ libdir / matrixts;', 'mars3_brinkeys'
LANGUAGE C
VOLATILE PARALLEL UNSAFE STRICT EXECUTE ON ALL SEGMENTS;
postgres=# select * from matrixts_internal.mars3_brinkeys('t_default'::regclass);
nbrinkeys | brinkeys
-----------+------------
3 | (c1,c2,c3)
3 | (c1,c2,c3)
3 | (c1,c2,c3)
3 | (c1,c2,c3)
(4 rows)





