
这几年 AI 快速革新,其中带来的一个显著变化是 —— 数据库所承载的分析任务越来越重。越来越多的场景不再局限于只跑几张固定报表,而是要处理更宽的明细表、更长的时间窗口、更多维度的特征数据。比如特征加工、用户行为分析、模型结果的二次分析,甚至向量召回之后再和业务属性、时间窗口、交易明细做关联。
日常我们在做 SQL 性能分析时,通常会先看几个熟悉的地方:
是不是表太大?
是不是没有合适的过滤条件?
关联顺序有没有问题?
聚合、排序是不是吃了太多内存?
...
这些确实都很重要。但在 MPP 架构中,有时真正拖慢查询的,往往是另一个不起眼的部分:数据传输。在 YMatrix 中,一条 SQL 会被分发到多台机器上并行执行,最后再由主节点进行汇总。在此期间,扫描、过滤、聚合、排序、关联等算子负责"算",执行真正的计算任务;而 Interconnect,顾名思义,节点之间的数据传输组件,则负责"送",将需要的数据送达至指定的节点。
如果说数据库执行器是发动机,Interconnect 就好比是数据高速公路。如果路太窄、收费站太多、拥堵频发,那么就算发动机再强,查询也快不起来。面对此种困境,YMatrix 围绕这条数据高速公路做了一次全面升级,实现了新一代的 ic-tunnel 传输协议,在此模式下,数据可以更稳定、更可靠地送达目的地,保障查询性能。在某真实大型集团财务共享类场景中,业务侧经常需要按账簿、年度、科目等维度做明细分析。有时查单账簿,有时查全账簿;有时只看单科目,有时要拉全年、全科目的明细数据,在 tunnel 模式下,原先 TCP 模式下的查询均有不同程度的性能提升:
单账簿、全年、全科目查询,从 23s 降到 4s,耗时下降约 82.6%,约提升 5.75 倍;
全账簿、全年、单科目查询,从 54s 降到 33s,耗时下降约 38.9%;
全账簿、全年、全科目查询,从 9.5min 降到 7min,少了约 2.5 分钟,耗时下降约 26.3%。
这组数据表明,ic-tunnel 能够显著减少传输链路带来的等待,数据交换越重,这条链路的改善就越容易被业务感知到。
在单机数据库中,一条 SQL 的主要矛盾比较集中,通常取决于 CPU 是否算得动,内存够不够用,磁盘读写是否跟得上。但到了 MPP 数据库中,情况相较于单机数据库变得略微复杂一些,我们还需要考虑到数据传输,因为数据不仅只在本地计算,还需要在不同计算节点之间进行重新分布、汇总和交换。比如多表关联时,数据可能要按关联键重新分发;做 group by 时,中间结果可能要跨节点汇总。
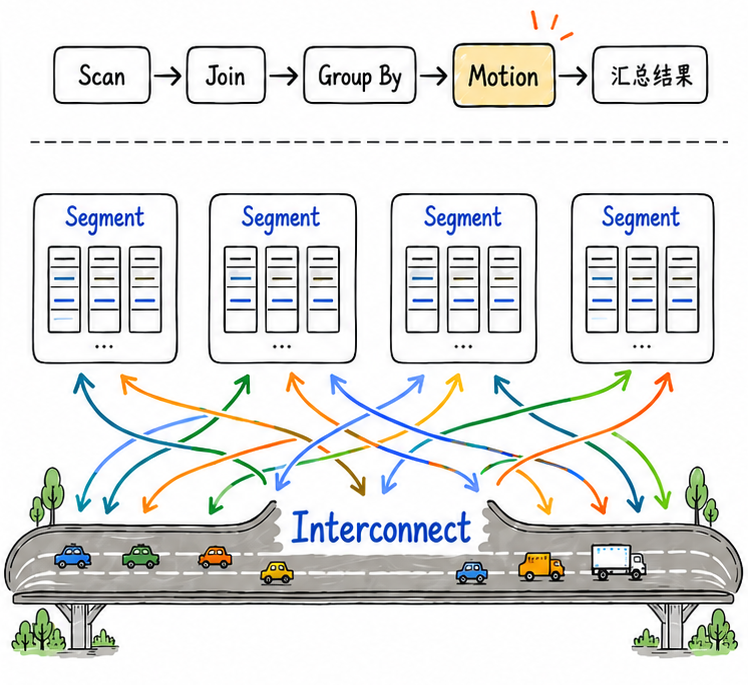
这些数据传输,在执行计划中表现为 Motion。Motion 看起来只是执行计划中的一个节点,但其背后并不简单。它还牵涉到节点之间如何建立连接、数据包怎么拆分和发送、网络抖动时要不要重传,以及集群拓扑变化后通信路径还能否正常工作等等。这些职责,最终都落到了 Interconnect头上。
所以在 MPP 数据库里,网络交换不是执行计划之外的附属动作,它本身就是查询执行的一部分,而且决定了一条查询能不能高效稳定地跑完。
传统 MPP 数据库通常有两类 Interconnect 实现:TCP 和 UDP:
TCP 模式成熟稳定,性能上限高。但受限于 TCP 模型,集群规模一大,整体连接数就很容易失控。假设一个集群有 100 节点,那么一次数据重分布就需要 100 ^ 2 = 10000 个 TCP 连接,如果有十个查询同时执行,那么就需要 (100 * 10) ^ 2 = 1000000 个 TCP 连接,连接规模会迅速膨胀。这就好比给每辆车都单独修了一条专用匝道,车一旦多起来,路会先堵死,极大限制了整个集群的吞吐量。
UDP 模式可以有效缓解连接数问题,适合大规模集群。但 UDP 本身并不提供完整的可靠传输能力,数据库需要自己处理 ACK、重传、乱序、流控等机制。一旦遇到网络延迟升高、MTU 较小、带宽受限等场景,或者需要传输大量明细数据时,性能就很容易出现波动。
因此,传统 Interconnect 各有其适用场景:TCP 性能好,但连接压力大;UDP 扩展性好,但对网络十分敏感。
YMatrix 不只是一个传统 MPP 数据库,在不断发展的同时,还在持续演进向量化执行能力。
向量化执行的核心思想,是让执行器不再逐行处理数据,而是批量化处理数据,这样便可以更好地利用 CPU cache、SIMD 和批量计算能力,让扫描、过滤、聚合、Join 等算子获得更高效率。
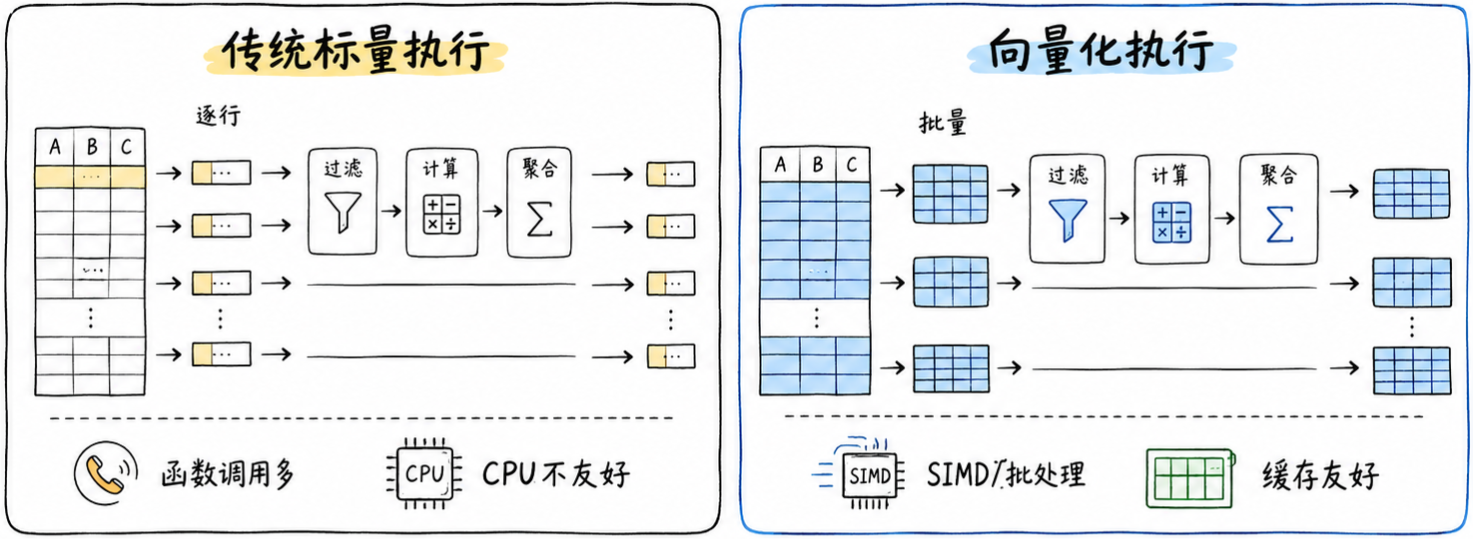
但此处有一个容易被忽视的问题:算子已经批量计算,数据交换与传输也必须跟得上批量化。否则执行器已经进入大块数据批量处理的时代,而 Interconnect 仍然止步不前,停留在小包拆分、拼接、重组、多次拷贝的模式,那么向量化的收益就会大打折扣。
这也正是 ic-tunnel 设计初衷之一:当 YMatrix 的执行引擎越来越快,底层的数据交换机制是否也应该随之升级?答案显然是肯定的。向量化执行需要的不只是更快的算子,还需要更适合大块数据流动的通信底座。只有计算和传输同时进化,分布式查询的整体性能才能被真正释放出来。
简单来说,ic-tunnel 是 YMatrix 新一代 Interconnect 实现。
如前文所述,在传统模式下,节点之间可能需要建立大量连接。集群越大、并发越高、查询越复杂,连接数量和数据交换路径就越难控制。ic-tunnel 选择了不同的实现方式,类似代理架构:每个 segment 上有一个专职的 tunnel server 进程,查询进程不再与所有远端节点逐一建立大量连接,而是先与本地 tunnel server 建立连接,再由 tunnel server 完成数据转发。二者的差异如下:
传统模式:执行进程 ↔ 执行进程
ic-tunnel:执行进程 → 本地 tunnel server → 远端 tunnel server → 远端执行进程
对上层执行逻辑来说,Motion 仍然表达的是数据从哪里流向哪里;但底层连接管理、拓扑感知、流量控制、传输粒度、压缩等工作,则交由 tunnel 层统一处理。也就是说,tunnel 层把原本分散在大量执行进程之间的连接和转发收敛起来,让上层继续按 Motion 的逻辑处理数据流,而底层负责把连接、流控和传输过程管理好。
ic-tunnel 的优势可以概括为三点:按需建立拓扑、主动流控以及自动调整传输粒度。
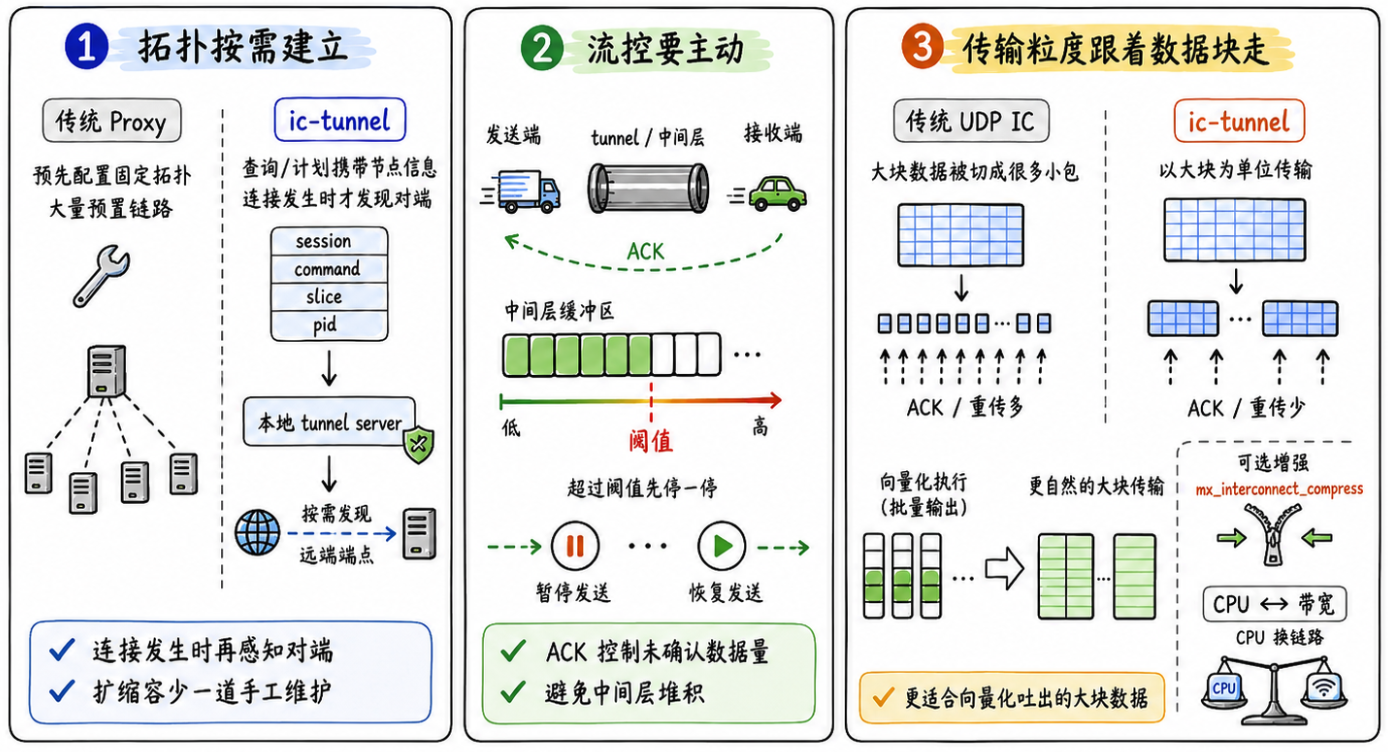
在 MPP 数据库中,集群扩缩容、主从切换之后,拓扑信息可能发生变化,ic-tunnel 的思路是:连接由实际查询驱动。主节点在分发查询计划时,会把执行所需的 slice、节点和连接信息一并发给计算节点,这样计算节点知晓自己要和哪个对端通信之后,再把这些信息告诉本地 tunnel server。
这样一来,tunnel server 便不需要从一开始就维护一份全局拓扑,而是在真实连接发生时,再按需获取对端信息,这样实现的好处很明显:
集群扩容后,查询执行路径会附带新节点信息;
主从切换后,新的查询执行路径会基于新的节点信息建立通信;
tunnel server 也不需要维护一份容易过期的全局配置。
简而言之,ic-tunnel 并不是提前将所有路都铺好,而是在数据真正需要传输时,再根据此次查询的实际执行关系找到该走的路。
代理模型还有一个常见风险:发送端太快,接收端太慢。
如果中间层只是不间断接收数据和转发数据,而没有足够好的流控机制,那么数据可能堆在中间层。堆得少或许只是内存上涨,但是一旦堆积过多,就可能影响整个实例的稳定性。
ic-tunnel 在这块做了主动式流控,主动式流控可细分为发端流控与收端流控:发端流控发生在发端的 tunnel server 中,如果它迟迟无法把数据发送到收端 server,那么便会进行流控。而收端流控则发生在收端的 tunnel server 中,类似地,如果迟迟无法将数据转发给收端 client,那么也会通知发端暂停发送。
对代理模型来说,这一步很关键。因为 tunnel server 一旦成为中间层,就不能只负责转发,还必须负责控制数据在中间层的停留量。
传统 UDP interconnect 在传输粒度上受包大小和 MTU 的影响比较明显。数据块一大,就需要切分成很多小包;在明细查询或大块数据传输场景下,ACK 和重传开销也会变得愈发明显。
ic-tunnel 可以自己控传输粒度,不再受传统 gp_max_packet_size 那套逻辑限制。这对于向量化执行来说很重要,因为向量化执行器本来就是批量处理数据。如果 interconnect 也能更自然地处理大块数据,就可以减少中间层的拆分、拼接和额外拷贝。其次,在带宽不足的时候还可以开启 mx_interconnect_compress,对网络通信进行压缩,在网络带宽成为瓶颈时十分有价值。
ic-tunnel 让 YMatrix 的 Interconnect 从传统的 TCP/UDP 连接模型,升级为更适合现代化的通信模型:
从 DBA 的角度看,它减少的是 Interconnect 选型和排障上的不确定性;
从架构设计的角度看,它提升的是大规模集群、高并发和复杂网络环境下的可控性;
从业务用户的角度看,查询延迟更为稳定,数据迁移少一些阻塞,复杂关联和明细查询的表现也更可预期;
对于 YMatrix 自身来说,它让向量化执行不只停留在算子层,而是延伸到底层数据交换链路,提升整个系统的可用性。
当数据规模越来越大,集群越来越复杂,真正决定数据库能力边界的,不仅仅是某个单独算子,还取决于整个系统是否能在复杂环境下持续、稳定、高效地完成数据流动。ic-tunnel,就是 YMatrix 为这条数据流动之路铺下的新一代高速通道。
推荐阅读










