本文档介绍了 MatrixGate 的主要功能。
MatrixGate 对外提供 HTTP API,支持各种编程语言通过 HTTP 接口将数据导入到 MatrixDB 数据库中。MatrixGate HTTP 协议格式及响应码如下:
MatrixGate HTTP 协议格式
| 协议类型 | 协议格式 | 用法及示例 |
|---|---|---|
| URL | http://\ |
指定 mxgate 连接网址 |
| PATH | / | 当前支持 /,忽略 / 后面任何 PATH |
| HTTP Method | POST | 当前支持 POST 方式加载数据 |
| HTTP Header | Content-Encoding: gzip | 当前支持 gzip 对 HTTP Body 内容压缩 |
| Content-Type: text/plain | 当前支持 text / plain | |
| HTTP Body | SchemaName.TableName Timestamp|ID]|C1|C2|..|Cn |
Body 格式第一行为数据加载的目标表,SchemeName 可省略,默认为 Public,TableName 为必须项,第二行开始是时序数据行,每行对应目标表的一行,列之间使用 | 分隔符,行之间使用 \n 分隔符。每行第一个字段为时间戳,格式为 UNIX 时间戳精确到秒,参见 --time-format 的说明。每行第二个字段为 TagID,整型。每行第三个字段到最后一个字段为与目标表对应的列。 建议目标表的 DDL 定义也遵循( Timestamp,TagID,C1,C2,…,Cn)的列顺序 |
MatrixGate HTTP 响应码
| 响应码 | 响应码含义 | 备注 |
|---|---|---|
| 200 | StatusOK | 部分数据格式错误,响应 Body 里会包含错误的行以错误信息,如:At line: 2missing data for column "c3" |
| 204 | StatusNoContent | 数据成功加载到 MatrixGate |
| 400 | StatusBadRequest | 数据请求错误,如 POST BODY 格式错误、目标表不存在、数据压缩格式与 HTTP 请求头不符等 |
| 405 | StatusMethodNotAllowed | HTTP 非 POST 请求 |
| 408 | StatusTimeout | 请求超时 |
| 500 | StatusIntervalServerError | 数据库端错误,数据加载失败,响应 Body 内包含详细错误信息 |
| 503 | StatusServiceUnavailable | MatrixGate 拒绝请求,如超过最大连接数,或 MatrixGate 正在关闭等 |
首先,在 demo 数据库中创建表 testtable。
CREATE TABLE testtable (time TIMESTAMP WITH TIME ZONE, tagid INT, c1 INT, c2 INT, c3 INT)
DISTRIBUTED BY (tagid);生成 mxgate.conf 配置文件。
mxgate config --db-database testdb \
--db-master-host localhost \
--db-master-port 5432 \
--db-user mxadmin \
--db-password 123123 \
--target public.testtable \
--format csv \
--time-format unix-second \
--delimiter '|' \
--parallel 256 \
--stream-prepared 3 \
--interval 250 \
--transform plain \
> mxgate.conf编辑数据加载文件 data.txt,内容如下:
public.testtable
1603777821|1|101|201|301
1603777822|2|102|202|302
1603777823|3|103|203|303启动 mxgate,指定生成好的配置文件 mxgate.conf。
mxgate --config mxgate.conf发送 HTTP 请求加载数据。
curl http://localhost:8086/ -X POST -H 'Content-Type: text/plain' --data-binary "@data.txt"连接数据库查询数据是否加载成功。
demo=# SELECT extract(epoch FROM "time"), * FROM testtable;
date_part | time | tagid | c1 | c2 | c3
------------+------------------------+-------+-----+-----+-----
1603777821 | 2020-10-27 13:50:21+08 | 1 | 101 | 201 | 301
1603777822 | 2020-10-27 13:50:22+08 | 2 | 102 | 202 | 302
1603777823 | 2020-10-27 13:50:23+08 | 3 | 103 | 203 | 303
(3 rows)SDK(Software Development Kit)指软件开发工具包,它可将开发者从非业务逻辑的功能开发中解放出来,极大地提升开发效率和体验,增加易用性。
注意!
以上方式任选其一即可。推荐使用(1)或(2)直接从 Maven 或 Gradle 远程仓库引入 SDK,高效又便捷。(3)本地导入方式请见MatrixGate FAQ:19,推荐直接进行关键词JAVA SDK搜索,因不常用在此不做详述。
(1). 调用 Maven 远程仓库自动下载 SDK 包 在你的 JAVA 工程的 pom.xml 文件中配置如下依赖。
<dependencies>
<dependency>
<groupId>cn.ymatrix</groupId>
<artifactId>mxgate-sdk-java</artifactId>
<version>1.1.2</version>
</dependency>
</dependencies>(2). 使用 Gradle 远程仓库引入 SDK 依赖
repositories {
mavenCentral()
}
dependencies {
implementation 'cn.ymatrix:mxgate-sdk-java:1.0.20'
}注意!
需要使用支持 gRPC 的 MatrixDB 版本,即 4.6.1 及之后。
在 Master 上编写 mxgate 配置文件 mxgate_grpc.conf 并启动 mxgate。
注意!
在使用 mxgate 之前,你需要首先在数据库中创建表。示例中 Master 主机为 mdw,数据库为 demo,数据表为 test_table_transfer。
代码如下:
# 创建 mxgate config 文件
[mxadmin@mdw ~]$ mxgate config \
--source grpc \
--db-database demo \
--target public.test_table_transfer \
--time-format raw \
--grpc-port 8087 \
--format csv \
> mxgate_grpc.conf
# 启动 mxgate
[mxadmin@mdw ~]$ mxgate start --config mxgate_grpc.conf如示例代码所示,使用 SDK 向 mxgate 写入数据,需要指定 mxgate 的 source 参数为 grpc,format 为 csv。同时由于 SDK 需要知道将数据写入到哪里,需要在配置文件中指定 grpc-port 端口号,示例中为 8087。
注意!
通过 HTTP 启动 mxgate 依然需要指明 mxgate 的 gRPC 端口号,因为 SDK 从 mxgate 获取数据库表元信息的方式依然是 gRPC,只是写入数据的方式切换为 HTTP。
在 Master 上编写 mxgate 配置文件 mxgate_http.conf 并启动 mxgate.示例中 Master 主机名为 mdw,代码如下:
# 创建 mxgate config 文件。
[mxadmin@mdw ~]$ mxgate config \
--source http \
--db-database demo \
--target public.test_table_transfer \
--time-format raw \
--grpc-port 8087 \
--format csv \
> mxgate_http.conf
# 启动 mxgate
[mxadmin@mdw ~]$ mxgate start --config mxgate_http.conf Partitioned table "public.test_table_transfer"
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
ts | timestamp without time zone | | |
tag | integer | | not null |
c1 | double precision | | |
c2 | double precision | | |
c3 | double precision | | |
c4 | double precision | | |
c5 | text | | |
c6 | text | | |
c7 | text | | |
c8 | text | | |
Partition key: RANGE (ts)首先进行全局初始化设置:
// 设置日志级别,默认 INFO。
MxLogger.loggerLevel(LoggerLevel.INFO);
// 日志默认会输出到 stdout,如果不希望输出,可以在如下 API 中传入 false。
MxLogger.enableStdout(true);
// SDK 默认日志文件路径和命名格式是 /tmp/mxgate_sdk_java_2022-08-26_133403.log ,
// 用户可以自定义输出日志文件的文件路径和文件名。
MxLogger.writeToFile("/tmp/mxgate_sdk_java.log");注意!
在一个工程里只需要 Build 一次。 在初始化 MxBuilder 前可进行相关配置。
MxBuilder builder = MxBuilder.newBuilder()
.withDropAll(false) // 如果需用于测试,则可设置为 true,不发送数据给 mxgate,直接 drop;发送数据到 mxgate 需设置为 false
.withCacheCapacity(100000) // 用于暂存 tuples 微批的 queue的大小
.withCacheEnqueueTimeout(2000) // 若queue满,tuples 存入 queue 的等待超时时间。若超时,会抛出IllegalStateException
.withConcurrency(10) // 同时向 mxgate 写入数据的线程数量。
.withRequestTimeoutMillis(3000) // 每个线程每次数据写入请求的超时时间(毫秒)。
.withMaxRetryAttempts(3) // 每个线程每次写入请求遇到问题后的重试次数。
.withRetryWaitDurationMillis(3000) // 每次重试的时间间隔(当前的实现,每次重试的时间间隔是固定的)。
.withRequestType(RequestType.WithHTTP) // SDK 支持通过 HTTP 和 gRPC 两种方式向 mxgate post 数据,对应的配置为:RequestType.WithHTTP,RequestType.WithGRPC
.withCircuitBreaker() // 使用内置熔断器。若失败率或者慢请求率达到阈值,则会开启,开启后持续30秒,暂停向 mxgate 发送数据,亦无法 append tuple
.withMinimumNumberOfCalls(1) // 熔断器生效的最小请求数(要求 >= 1,默认 10)
.withSlidingWindowSize(10) // 用以计算失败率的滑动窗口大小(要求 >= 1,默认 100)
.withFailureRateThreshold(60.0f) // 失败率阈值(要求 >0 且 <= 100),若失败率达到阈值则会开启熔断器
.withSlowCallDurationThresholdMillis(1000) // 慢请求时长阈值(毫秒),超过该时长则认为是慢请求(注意该时长应小于请求超时时间)
.withSlowCallRateThreshold(80.0f)// 慢请求阈值,若慢请求率达到阈值则会开启熔断器
// .withRequestAsync(true)// 开启异步模式向 mxgate 发送数据的工作者线程(如使用此功能去掉此行注释内容即可)
// .withConcurrency(20)// 通常异步模式只需要几十的并发,就可以达到和同步模式同样甚至更高的吞吐(如使用此功能去掉此行注释内容即可)
// MxBuilder 的 builder 模式新增了如下 API 用于调整 CSV 并行转换的并发度(MxClient Group 级别)
// .withCSVConstructionParallel(100)//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)
.build();
// MxBuilder 新增单例 API,在 MxBuilder 被成功 build 之后,可通过如下 API 在任意位置获取 MxBuilder 的全局唯一单例的实例对象,不需要用户手动写代码维护 MxBuilder 的全局引用
// MxBuilder.instance();//(此功能从 v1.1.2 开始支持,如使用去掉此行注释内容即可)
// builder.getTupleCacheSize(); // 用于实时获取 SDK 内部 Tuple cache 中剩余 Tuple 的数量(如使用此功能去掉此行注释内容即可)Builder 的 connect 方法接收四个参数:
(1). mxgate 进程提供特定服务所在的 hostname (IP 地址)及端口号,用于接收数据及数据库表元信息。
例如,对于 HTTP 方式为 http://localhost:8086/;而对于 gRPC 方式,则为 localhost:8087
(2). schema。
(3). table name。
(4). callback,如果 builder 能够成功连接到 mxgate,则 onSuccess 方法会回调,同时会返回一个 MxClient 实例用于数据写入,如果连接失败,则 onFailure 会回调,failureMsg 会说明失败的原因。
具体代码如下,记得将端口号、模式名、表名替换为实际内容。
// 异步方法(此功能从 v1.0.13 开始支持)
builder.connect("http://localhost:8086/", "localhost:8087", "public", "test_table", new ConnectionListener() {
@Override
public void onSuccess(MxClient client) {
sendData(client);
}
@Override
public void onFailure(String failureMsg) {
}
});通过 ConnectionListener 的 onSuccess() 回调函数,你可以拿到 MxClient 实例,随后通过 MxClient 提供的 API,即可实现向 mxgate 写入数据的功能。
// 同步方法(此功能从 v1.0.13 开始支持)
MxClient client = builder.connect(httpHost, gRPCHost, schema, table);// v1.1.0 对 MxClient 进行了可扩展性的提升,MxBuilder 提供了若干新的 API
// 通过该 API 获取到的 MxClient 属于某个 MxClient Group
// 你可通过这些 API 自由定义 MxClient Group Number,Tuples cache capaticy 以及 TuplesConsumer 的并发度等等参数
// MxClient client = builder.connectWithGroup(dataSendingHost, metadataHost, schema, table, 10);//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)
// MxClient client = builder.connectWithGroup(dataSendingHost, metadataHost, schema, table, 1, 1000, 3000, 10);//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)
// 以 skip 开头的 API,调用的时候会跳过连接后端服务获取数据库表元信息的过程
// 此种 MxClient 只能通过 generateEmptyTupleLite() 获取轻量级的 Tuple
// MxClient client = mxBuilder.skipConnectWithGroup(dataSendingHost, metadataHost, schema, table, delimiter, 1);//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)
// MxClient client = mxBuilder.skipConnectWithGroup(dataSendingHost, metadataHost, schema, table, delimiter, 1, 1000, 3000, 1);//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)注意!
MxClient 是线程安全的,但是如果在多线程并发使用,为了确保最佳性能,最好是每一个线程中有一个单独的 MxClient,也就是通过 MxBuilder 多次 connect 返回多个 MxClient 实例。
private void sendData(MxClient client) {
if (client != null) {
// MxClient 会累积一批 Tuple 作为一个微批一并发送给 mxgate,
// 该 API 会设置每个微批累积的等待时间,默认 2000 millisecond,
// 也就是每个 2s 会尝试发送一批数据到 mxgate,如果该 2s 的时间段内
// 没有数据写入,则不会发送。
client.withIntervalToFlushMillis(5000);
// 设置累积多少个 Tuple 字节作为一个微批进行发送,即使时间没有达到
// 设置的 flush interval,累积的微批字节数达到了,也会发送。
// flush interval 的时间达到了,没有累积够设定的字节数,也会发送。
client.withEnoughBytesToFlush(500);
// 相比 withEnoughBytesToFlush,在 appendTuple 的时候
// 性能得到提升,因为这样避免了计算字节数
// 视具体使用的场景而定,如果 withEnoughBytesToFlush
// 同样能满足性能要求,那么每次 flush,数据量将会更加均匀。
// withEnoughLinesToFlush 的优先级会高于 withEnoughBytesToFlush
client.withEnoughLinesToFlush(10000);
// MxClient 新增如下 API,用来调整每个 CSV 转换子任务的 Tuple 数量
// 比如一次 Flush 总共有 10000 个 Tuple,通过如下 API 设置 BatchSize = 2000
// 那么这 10000 个 Tuple 的 CSV 转换就会被切分为 5 个子任务,每个子任务处理 2000 个 Tuple 并发执行
client.withCSVConstructionBatchSize(2000);//(此功能从 v1.1.0 开始支持)
// 每个 MxClient 独占一个私有的对象池
// 使用的时候,需要根据每次 MxClient flush 的 Tuple 数量合理的设置对象池的大小
// client.useTuplesPool(poolSize); //(如使用此功能去掉此行注释内容即可 )
// MxClient 支持压缩,需配合 mxgate v4.7.6 及更高版本一起使用
// client.withCompress(); //(如使用此功能去掉此行注释内容即可)
// 对于 HTTP 的请求,可以不使用 base64 encoding,gRPC 则需要进行 base64 encoding。
// client.withBase64Encode4Compress(); // (如使用此功能去掉此行注释内容即可)
// MxClient 可以注册一个 DataPostListener,每批数据发送的成功和失败
// 都会在 onSuccess 和 onFailure 中回调。你可以了解哪些 Tuple 写入成功,哪些 Tuple 写入失败
client.registerDataPostListener(new DataPostListener() {
@Override
public void onSuccess(Result result) {
System.out.println(CUSTOMER_LOG_TAG + "Send tuples success: " + result.getMsg());
System.out.println(CUSTOMER_LOG_TAG + "Succeed lines onSuccess callback " + result.getSucceedLines());
}
@Override
public void onFailure(Result result) {
// result.getErrorTuplesMap() 包含错误的行和错误原因的键值对 Tuple -> String
// Key 是错误的行, value 是错误的原因;
for (Map.Entry<Tuple, String> entry : result.getErrorTuplesMap().entrySet()) {
l.error(CUSTOMER_LOG_TAG + "error tuple of table={}, tuple={}, reason={}", entry.getKey().getTableName(), entry.getKey(), entry.getValue());
for (Column c : entry.getKey().getColumns()) {
l.error(CUSTOMER_LOG_TAG + "error entry columns {} = {}", c.getColumnName(), c.getValue());
}
}
System.out.println(result.getSuccessLines());
}
});通过 MxClinet 的 generateEmptyTuple API 来返回一个空的 Tuple 对象用于赋值。
Tuple tuple1 = client.generateEmptyTuple();
Tuple tuple2 = client.generateEmptyTuple();以 Key -> Value 的方式给空的 Tuple 赋值。Key 是对应数据库表的列名;Value 是该字段对应的值。如果有某些字段值允许为 null 或者有默认值,则可以不添加该字段的值,SDK 会自动填充默认值或者空值。
通过该 API 获取到的 Tuple 内部不再维护数据库表的元信息,是一种更轻量级的 Tuple,所以调用 MxClient.appendTuple() 将这种轻量级的 Tuple 到 append 到 MxClient 的时候,省去了基于数据库表元信息对 Tuple 内部数据合法性检查的工作,可以 Tuple 的数据能够以最快的速度被 flush。
// Tuple tuple = client.generateEmptyTupleLite();//(此功能从 v1.1.0 开始支持,如使用去掉此行注释内容即可)注意!
在向该轻量级 Tuple 执行添加列操作时需要手动维护addColumn() key -> value对的先后顺序,确保该顺序和数据库表的列的先后顺序一一对应。
例如,数据表列顺序如下:
Column | Type | Collation | Nullable | Default
--------+-----------------------------+-----------+----------+---------
ts | timestamp without time zone | | |
tag | integer | | not null |
c1 | double precision | | |
c2 | double precision | | |
c3 | double precision | | |
c4 | double precision | | |
c5 | text | | |
c6 | text | | |
c7 | text | | |
c8 | text | | |那么添加列的顺序必须与数据库表中列的先后顺序保持一致,此示例中如下:
tuple1.addColumn("ts", "2022-05-18 16:30:06");
tuple1.addColumn("tag", 102020030);
tuple1.addColumn("c1", 1.1);
tuple1.addColumn("c2", 2.2);
tuple1.addColumn("c3", 3.3);
tuple1.addColumn("c4", 4.4);
tuple1.addColumn("c5", "中文字符测试-1");
tuple1.addColumn("c6", "lTxFCVLwcDTKbNbjau_c6");
tuple1.addColumn("c7", "lTxFCVLwcDTKbNbjau_c7");
tuple1.addColumn("c8", "lTxFCVLwcDTKbNbjau_c8");
tuple2.addColumn("ts", "2022-05-18 16:30:06");
tuple2.addColumn("tag", 102020030);
tuple2.addColumn("c1", 1.1);
tuple2.addColumn("c2", 2.2);
tuple2.addColumn("c3", 3.3);
tuple2.addColumn("c4", 4.4);
tuple2.addColumn("c5", "中文字符测试-2");
tuple2.addColumn("c6", "lTxFCVLwcDTKbNbjau_c26");
tuple2.addColumn("c7", "lTxFCVLwcDTKbNbjau_c27");
tuple2.addColumn("c8", "lTxFCVLwcDTKbNbjau_c28");最后,将赋值完毕的 Tuple append 到 MxClient。
client.appendTuples(tuple1, tuple2);注意!
MxClient 提供多个 API,可以一次 Append 一个 Tuple,也可以一次 Append 多个 Tuple,或者一个 Tuples List。如:client.appendTuple();,client.appendTupleList();;也可以调用 MxClient 的 flush() 方法,手动发送数据,无论此时写入了多少个 Tuple 的数据,如client.flush();。
Tuple tuple1 = client.generateEmptyTuple();
tuple1.addColumn("ts", "2022-05-18 16:30:06");
tuple1.addColumn("tag", 102020030);
tuple1.addColumn("c1", 1.1);
tuple1.addColumn("c2", 2.2);
tuple1.addColumn("c3", 3.3);
tuple1.addColumn("c4", 4.4);
tuple1.addColumn("c5", "lTxFCVLwcDTKbNbjau_c5");
tuple1.addColumn("c6", "lTxFCVLwcDTKbNbjau_c6");
tuple1.addColumn("c7", "lTxFCVLwcDTKbNbjau_c7");
tuple1.addColumn("c8", "lTxFCVLwcDTKbNbjau_c8");
// appendTupleBlocking 会返回 boolean 类型的返回值
// true:MxClient 中已经写满了设定的 bytes size,可以发送请求
// false:设定的 bytes size 还没写满
try {
if (client.appendTupleBlocking(tuple1)) {
l.info("append tuples enough");
// 手动 trigger tuples flush
client.flushBlocking();
}
// 如果如下 flushBlocking 抛出异常,说明整批 Tuple 都没能写入到 mxgate,调用方可以针对该异常做相应的处理
} catch (AllTuplesFailException e) {
l.error("Tuples fail and catch the exception return.", e);
for (Map.Entry<Tuple, String> entry : result.getErrorTuplesMap().entrySet()) {
l.error(CUSTOMER_LOG_TAG + "error tuple of table={}, tuple={}, reason={}", entry.getKey().getTableName(), entry.getKey(), entry.getValue());
for (Column c : entry.getKey().getColumns()) {
l.error(CUSTOMER_LOG_TAG + "error entry columns {} = {}", c.getColumnName(), c.getValue());
}
}
// 如果如下 flushBlocking 抛出异常,则说明有部分 Tuple 没能写入到 mxgate,调用方可以针对该异常做相应的处理
} catch (PartiallyTuplesFailException e) {
for (Map.Entry<Tuple, String> entry : result.getErrorTuplesMap().entrySet()) {
l.error(CUSTOMER_LOG_TAG + "error tuple of table={}, tuple={}, reason={}", entry.getKey().getTableName(), entry.getKey(), entry.getValue());
for (Column c : entry.getKey().getColumns()) {
l.error(CUSTOMER_LOG_TAG + "error entry columns {} = {}", c.getColumnName(), c.getValue());
}
}
}import java.io.BufferedReader;
import java.io.DataOutputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class MxgateExample {
public static void main(String[] args) throws Exception {
MxgateExample http = new MxgateExample();
http.sendingPostRequest();
}
// HTTP Post request
private void sendingPostRequest() throws Exception {
// mxgate监听在localhost的8086端口
String url = "http://localhost:8086/";
URL obj = new URL(url);
HttpURLConnection con = (HttpURLConnection) obj.openConnection();
// Setting basic post request
con.setRequestMethod("POST");
con.setRequestProperty("Content-Type","text/plain");
String postJsonData = "public.testtable\n1603777821|1|101|201|301\n1603777822|2|102|202|302\n1603777823|3|103|203|303";
con.setDoOutput(true);
DataOutputStream wr = new DataOutputStream(con.getOutputStream());
// 数据有中文时,可以通过postJsonData.getBytes("UTF-8")编码
wr.write(postJsonData.toString().getBytes("UTF-8"));
wr.flush();
wr.close();
int responseCode = con.getResponseCode();
System.out.println("Sending 'POST' request to URL : " + url);
System.out.println("Post Data : " + postJsonData);
System.out.println("Response Code : " + responseCode);
BufferedReader in = new BufferedReader(new InputStreamReader(con.getInputStream()));
String output;
StringBuffer response = new StringBuffer();
while ((output = in.readLine()) != null) {
response.append(output);
}
in.close();
System.out.println(response.toString());
}
}import http.client
class MxgateExample(object):
def __init__(self):
# mxgate监听在localhost的8086端口
self.url = "localhost:8086"
self.postData = "public.testtable\n/" \
"1603777821|1|101|201|301\n/" \
"1603777822|2|102|202|302\n/" \
"1603777823|3|103|203|303"
self.headers = {"Content-Type": "text/plain"}
# HTTP Post request
def sending_post_request(self):
conn = http.client.HTTPConnection(self.url)
conn.request("POST", "/", self.postData, self.headers)
response = conn.getresponse()
response_code = response.getcode()
print(f"Sending 'POST' request to URL : {self.url}")
print(f"Post Data : {self.postData}")
print(f"Response Code : {response_code}")
output = response.read()
print(output)
if __name__ == '__main__':
gate_post = MxgateExample()
gate_post.sending_post_request()
建议开发代码使用 C# Core 开发环境
using System;
using System.IO;
using System.Net;
using System.Text;
namespace HttpPostTest
{
class Program
{
static void Main(string[] args)
{
var url = "http://10.13.2.177:8086/";
var txt = "public.dest\n2021-01-01 00:00:00,1,a1\n2021-01-01 00:00:00,2,a2\n2021-01-01 00:00:00,3,a3";
HttpPost(url,txt);
}
public static string HttpPost(string url, string content){
string result = "";
HttpWebRequest req = (HttpWebRequest)WebRequest.Create(url);
req.Method = "POST";
req.ContentType = "text/plain";
#region 添加Post 参数
byte[] data = Encoding.UTF8.GetBytes(content);
req.ContentLength = data.Length;
using (Stream reqStream = req.GetRequestStream()){
reqStream.Write(data, 0, data.Length);
reqStream.Close();
}
#endregion
HttpWebResponse resp = (HttpWebResponse)req.GetResponse();
Stream stream = resp.GetResponseStream();
//获取响应内容
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8)){
result = reader.ReadToEnd();
}
return result;
}
}
}如果遇到 error when serving connection ***** body size exceeds the given limit 这个问题,调大 mxgate.conf 下的 max-body-bytes
package main
import (
"bytes"
"net/http"
)
func PostDataToServer(URL string) error {
data := `public.testtable
1603777821|1|101|201|301
1603777822|2|102|202|302
1603777823|3|103|203|303
`
resp, err := http.Post(URL, "application/text", bytes.NewBuffer([]byte(data)))
if err != nil {
return err
}
if resp.StatusCode != 200 {
// Deal with the response body.
return nil
}
// Deal with the response body.
return nil
}
func main() {
err := PostDataToServer("http://127.0.0.1:8086")
if err != nil{
panic(err)
}
}在 demo 数据库中创建表 csvtable。
demo=# CREATE TABLE csvtable (time TIMESTAMP WITH TIME ZONE, tagid INT, c1 INT, c2 INT, c3 INT)
DISTRIBUTED BY (tagid);编辑数据加载文件 data.csv,内容如下:
1603777821|1|101|201|301
1603777822|2|102|202|302
1603777823|3|103|203|303启动 mxgate,指定 source 参数为 stdin,目标表为已经存在的 csvtable,加载并行度为 2。示例中主机为 mdw。
[mxadmin@mdw ~]$ mxgate \
--source stdin \
--db-database demo \
--db-master-host 127.0.0.1 \
--db-master-port 5432 \
--db-user mxadmin \
--time-format unix-second \
--delimiter "|" \
--target csvtable \
--parallel 2 < data.csv连接数据库查询数据是否加载成功。
demo=# SELECT * FROM csvtable ;
time | tagid | c1 | c2 | c3
------------------------+-------+-----+-----+-----
2020-10-27 05:50:23+08 | 3 | 103 | 203 | 303
2020-10-27 05:50:22+08 | 2 | 102 | 202 | 302
2020-10-27 05:50:21+08 | 1 | 101 | 201 | 301
(3 rows)创建表。
demo=# CREATE TABLE json_test(id int, j json);创建数据文件。
~/json.csv
1|"{""a"":10, ""b"":""xyz""}"加载
这里使用 stdin 模式为例,其他模式都一样。
关键在 --format csv。
[mxadmin@mdw ~]$ mxgate \
--source stdin \
--db-database postgres \
--db-master-host 127.0.0.1 \
--db-master-port 7000 \
--db-user mxadmin \
--time-format raw \
--format csv \
--delimiter "|" \
--target json_test < ~/json.csv查看加载数据。
demo=# SELECT * FROM json_test;
id | j
----+-----------------------
1 | {"a":10, "b":"xyz"}
(1 row)创建表。
demo=# CREATE TABLE json_array_test(id int, j _json);创建数据文件
~/json_array.csv。
1|"{""{\""a\"":10, \""b\"":\""xyz\""}"",""{\""c\"": 10}""}"加载 mxgate。
[mxadmin@mdw ~]$ mxgate \
--source stdin \
--db-database postgres \
--db-master-host 127.0.0.1 \
--db-master-port 7000 \
--db-user mxadmin \
--time-format raw \
--format csv \
--delimiter "|" \
--target json_array_test < ~/json_array.csv验证。
demo=# SELECT * FROM json_array_test ;
id | j
----+---------------------------------------------
1 | {"{\"a\":10, \"b\":\"xyz\"}","{\"c\": 10}"}
(1 row)注意!
因为 JSON 列包含引号等特殊字符,所以 mxgate 的 --format 参数必须为 CSV。
watch 是 mxgate 的一个子命令,用一系列指标描述 mxgate daemon 运行情况。
watch 有两种模式:
[mxadmin@mdw ~]$ mxgate watch会每三秒收集 mxgate 的运行指标,输出结果如下
Time WCount ICount WSpeed/s ISpeed/s WBandWidth MB/S BlocakItems
2022-04-28 15:20:58 14478858 14527011 2598081 2627887 2395 0
2022-04-28 15:21:01 22231035 22633254 2584059 2702081 2222 0
2022-04-28 15:21:04 30494310 30500874 2754425 2622540 3551 0
2022-04-28 15:21:07 38004210 38032956 2503300 2510694 2862 0
2022-04-28 15:21:10 46188696 46298223 2728162 2755089 2227 0
...可通过 --info 参数来获取上述各个指标的说明
[mxadmin@mdw ~]$ mxgate watch --info默认情况下只会输出速度指标,可通过 --watch-latency 参数来观测时间指标用于分析问题
[mxadmin@mdw ~]$ mxgate watch --watch-latency[mxadmin@mdw ~]$ mxgate watch --history会计算截至当前时间为止,24小时内的每小时的平均速度,输出结果如下
TIME RANGE | SPEED/S | BANDWIDTH MB/S | BLOCK ITEMS
2022-04-28 16:00:00-2022-04-28 17:00:00 | 2208010 | 1254.48 | 0
2022-04-28 17:00:00-2022-04-28 18:00:00 | 1157920 | 1327.00 | 0
2022-04-28 18:00:00-2022-04-28 19:00:00 | 2228666 | 2162.32 | 0
2022-04-28 19:00:00-2022-04-28 20:00:00 | 1371092 | 2881.30 | 0
2022-04-28 20:00:00-2022-04-28 21:00:00 | 1575320 | 2608.20 | 0其中 SPEED/S,BANDWIDTH MB/S 代表导入的条目速度与导入带宽(MB/s 为单位), BLOCK ITEMS 代表阻塞在 mxgate 的数据量,当数据库消费速度跟不上数据源(http,kafka 等)生产速度时,这个值会上升
可以添加 --watch-start,--watch-end,--watch-duration 参数来控制观测历史数据的时间区间与周期
例如
[mxadmin@mdw ~]$ mxgate watch --history --watch-start '2022-03-27 00:00:00' --watch-end '2022-04-27 00:00:00' --watch-duration '168h'可以获得从 3 月 27 日到 4 月 27 日每周(每 168h)平均导入速度
其中 --watch-duration 支持 h m s 三种单位。
注意!
实验特性(Experimental)是某特定版本中存在但未正式发布的特性,会在未事先通知的情况下发生语法或实现上的变化或直接删除,请慎用。
YMatrix 支持使用 --instrumentation (-I) 参数来更便捷地定位数据写入的问题或者性能瓶颈。此参数开启后会在 mxgate 的日志中打印从插入开始到任务提交整个流程每个阶段的耗时。
一次插入的完整的 instrumentation 大致如下:
2023-04-26:02:51:43.679 xxx-[INFO]:-[Writer.Instrumentation] start_insert_txn [slotid:7] [insert_seq:123]
2023-04-26:02:51:43.683 xxx-[INFO]:-[Writer.Instrumentation] wait_singleconn [slotid:7] [insert_seq:123] [cost: 4ms] [seg:0] [ssid:13346] [seg_cnt:2]
2023-04-26:02:51:43.683 xxx-[INFO]:-[Writer.Instrumentation] wait_singleconn [slotid:7] [insert_seq:123] [cost: 4ms] [seg:1] [ssid:13346] [seg_cnt:2]
2023-04-26:02:51:44.730 xxx-[INFO]:-[Writer.Instrumentation] wait_allconn [slotid:7] [insert_seq:123] [cost:1051ms]
2023-04-26:02:51:44.747 xxx-[INFO]:-[Writer.Instrumentation] wait_flow [slotid:7] [insert_seq:123] [cost: 17ms] [seg:1] [ssid:13346] [seg_cnt:2]
2023-04-26:02:51:44.747 xxx-[INFO]:-[Writer.Instrumentation] write_header [slotid:7] [insert_seq:123] [cost: 0ms] [seg:1] [ssid:13346] [seg_cnt:2] [bytes:5]
2023-04-26:02:51:44.747 xxx-[INFO]:-[Writer.Instrumentation] write_body [slotid:7] [insert_seq:123] [cost: 0ms] [seg:1] [ssid:13346] [seg_cnt:2] [bytes:45]
2023-04-26:02:51:44.831 xxx-[INFO]:-[Writer.Instrumentation] write_eof [slotid:7] [insert_seq:123] [cost: 0ms] [seg:1] [ssid:13346] [seg_cnt:2]
2023-04-26:02:51:44.831 xxx-[INFO]:-[Writer.Instrumentation] write_eof [slotid:7] [insert_seq:123] [cost: 0ms] [seg:0] [ssid:13346] [seg_cnt:2]
2023-04-26:02:51:44.832 xxx-[INFO]:-[Writer.Instrumentation] wait_insertdone [slotid:7] [insert_seq:123] [cost: 1ms] [rows:17]
2023-04-26:02:51:44.836 xxx-[INFO]:-[Writer.Instrumentation] commit [slotid:7] [insert_seq:123] [cost: 3ms] [rows:17]
2023-04-26:02:51:44.836 xxx-[INFO]:-[Writer.Instrumentation] complete_insert_txn [slotid:7] [insert_seq:123]此日志包含以下关键信息:
INSERT 开始时间:start_insert_txnwait_singleconnwait_allconnwait_flowwrite_header(写入数据头) / write_body(写入数据实际内容) / write_eof(写入数据结尾)wait_insertdonecommitcomplete_insert_txn可以在 mxgate 启动参数上添加(或者在配置文件中修改此参数)。示例如下:
关闭插入流程的观测。
$ mxgate start --instrumentation disable开启 0 号槽(Slot)的观测。
$ mxgate start --instrumentation single开启所有 Slot 的观测。
$ mxgate start --instrumentation all注意!
--instrumentation详细子参数信息请见 命令行参数。
mxgate 支持在不停止运行的情况下,修改并行加载的相关参数:"interval"、“stream-prepared”。 "interval" 代表的是完成从 mxgate 写入数据到数据库表的每个写入连接的工作时间,“stream-prepared” 代表的是活跃的写入连接的数量。在 mxgate 逻辑中,同一个数据库表同一时间只有一个写入连接执行写入数据的任务,因此每个数据库表都需要有多个连接在不同时间区间去不停地执行它自身的写入任务,从而保证高速率、高效率地写入数据。在此过程中,你可以通过 “interval” 这个参数来实现对于每个写入连接的工作时间的调整,从而改善数据的写入速率,针对性提高加载性能。具体用法示例如下:
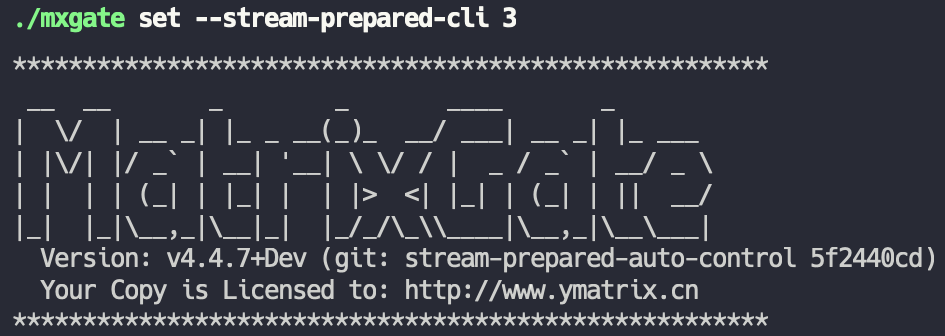
mxgate set --stream-prepared-cli 3 设置每个表的写入连接数量为 3
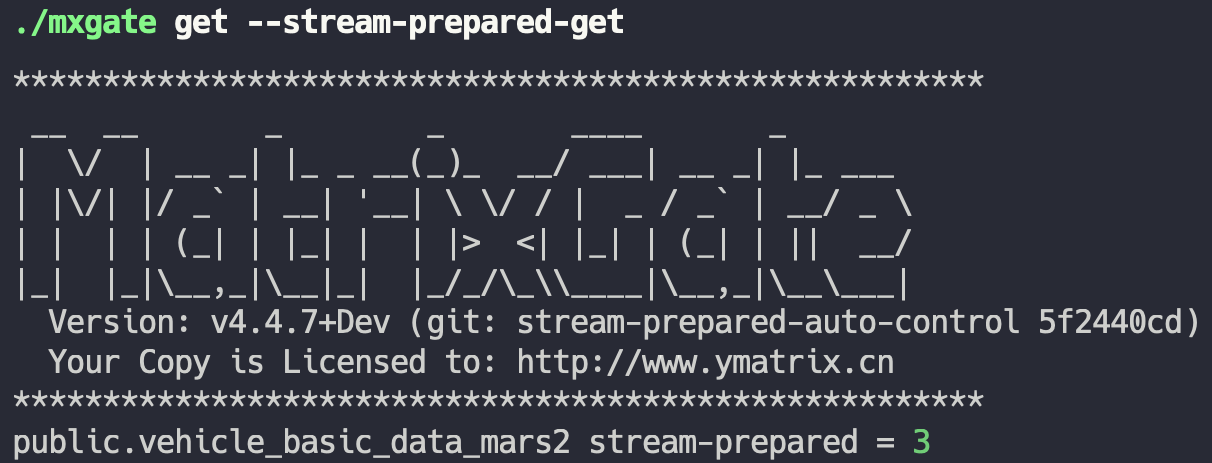
mxgate get --stream-prepared-get 获取每个表活跃的写入连接数量
mxgate set --job-interval 200 设置所有表的写入连接的时间间隔为 200ms

mxgate get --job-interval-get 获取所有表的写入连接当前的时间间隔

注意!
对于以上参数,如果你想设置或获取某个特定表的写入连接数量或工作时间,那么在上述命令后加--job <名称>即可。每个任务(job)对应一张数据库表,job 参数结构由模式名与表名组成,意思就是如果你的特定表叫做 test_table,模式名为 public,那么完成指定就需要在已有命令后加上--job public.test_table就是对的。
在数据加载的过程中,你可能会突然发现在变化的时序数据源驱动下,之前设定的表结构对于现在场景不再适用了,然后就有了修改表结构的需求,这是 mxgate 可以满足的。此节将会说明,mxgate 如何在不停机的情况下,执行暂停数据写入,重载修改后的数据库表元信息,恢复数据写入等系列操作。具体步骤如下:
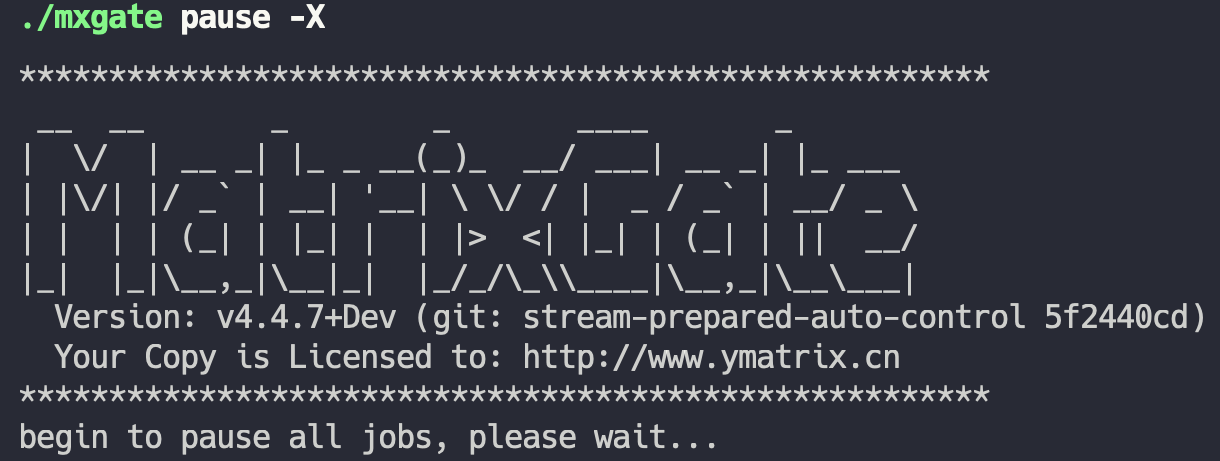
首先,使用命令 mxgate pause -X 中断所有表的写入连接,为修改数据库表结构作准备。其中 -X 参数是必要的,它会帮助中断 mxgate 和数据库之间的连接。如果不中断连接,是无法对数据库表进行修改的。除了 -X 之外,运用 -S 参数可以令 pause 命会同步等待所有连接中断完成再返回。
其次,中断对应表的所有写入连接之后,即可以对数据库对应的数据库表执行修改结构的操作,如增加若干列,删除若干列,删除已有表,重新创建“同名”的新表。
注意! 重建的表结构可以不同,但“表名”必须保持一致。
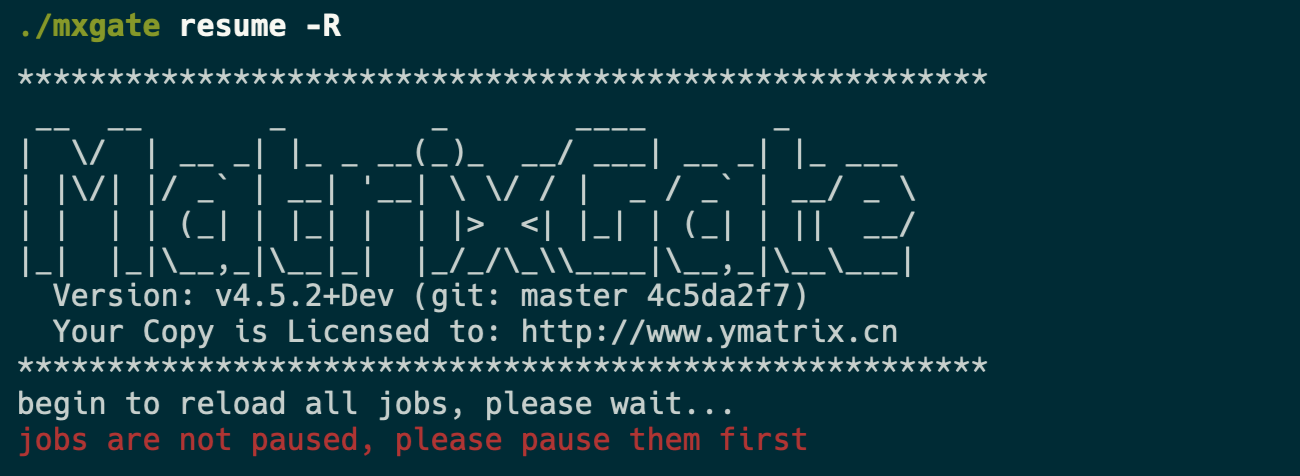
最后,使用命令 mxgate resume -R 恢复所有表的写入连接,重载数据表的元信息。其中 -R 参数是必需的,resume 与 -R 将组合完成重载操作。
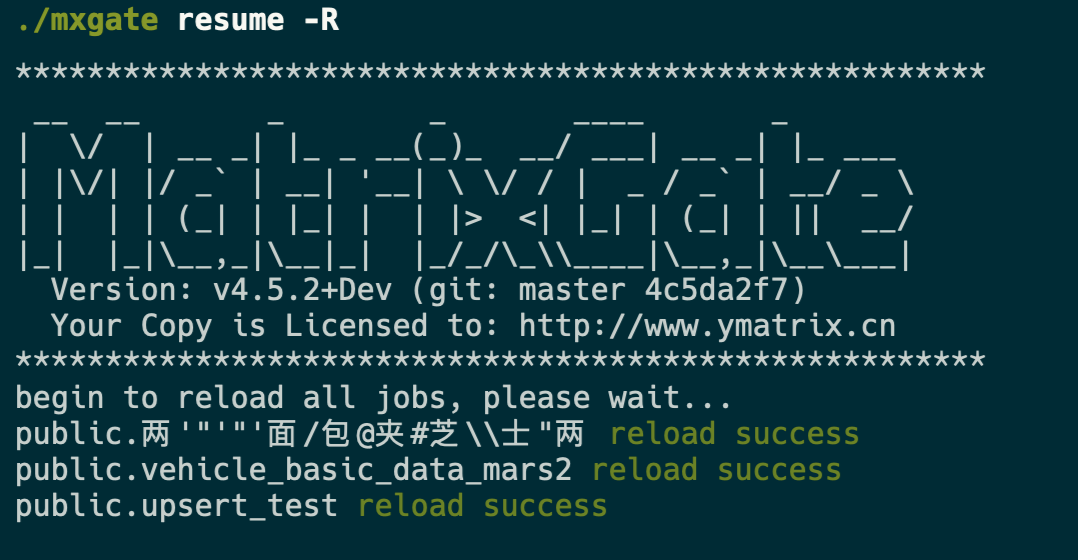
特别地,多个 mxgate 进程同时运行的情况,需要 -p 参数表示对应 mxgate 进程的进程号,上述所有命令都是同理。
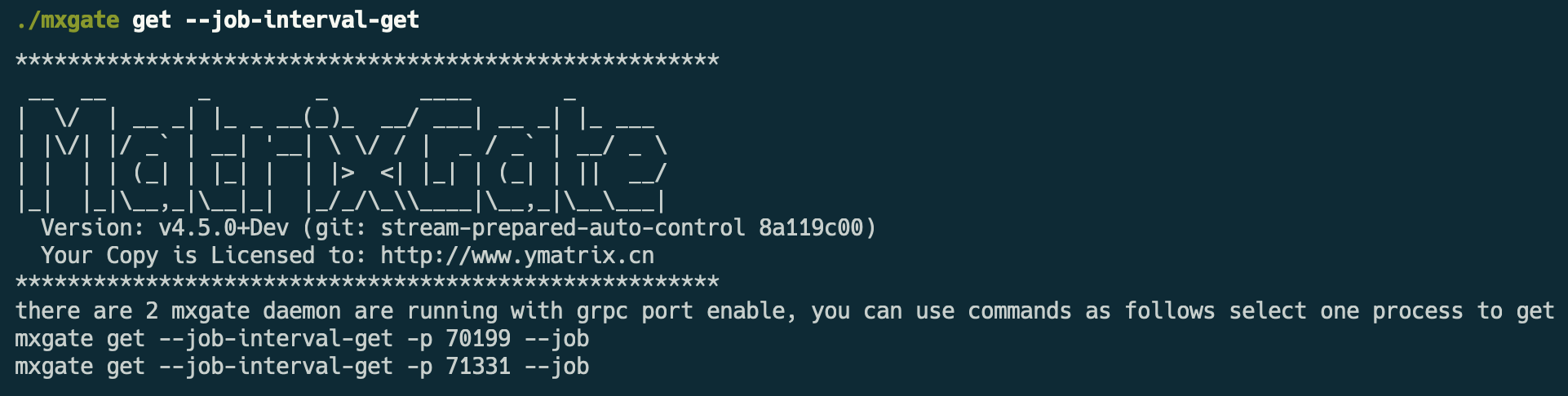
注意!
执行重载命令的前提是 mxgate 的对应的表的所有写入连接必须先被暂停,否则会出现如下报错:
我们有时需要打开 mxgate 的 debug 日志来观测一些关键信息,但是打开或者关闭 debug 日志都需要重启 mxgate,并不利于定位问题。因此, YMatrix 提供了动态变更 mxgate 日志级别的功能:
mxgate set --log-level VERBOSE 开启信息比较完整的 VERBOSE 级别的日志或者 mxgate set --log-level DEBUG 开启信息最完整的 DEBUG 级别的日志,等不需要在观察 debug 日志的时候,可以通过 mxgate set --log-level INFO,恢复日志级别为 INFO。