400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
系统配置参数
SQL 参考
常见问题(FAQ)
新架构 FAQ
集群部署 FAQ
SQL 查询 FAQ
MatrixGate FAQ
运维 FAQ
监控告警 FAQ
PXF FAQ
PLPython FAQ
性能 FAQ
Apache Kafka 是一个开源分布式事件流平台,它可以被当作是一个消息系统,读写流式数据,帮助发布、订阅消息;也可以用于编写可扩展的流处理应用程序,来应付实时响应的场景;还可以与数据库对接,安全的将流式数据存储在一个分布式,有副本备份,可容错的集群中。可以说,它所生产的“事件流”是信息数据传输的“中枢神经”。
如果你正打算用 Kafka 将数据写入 YMatrix 集群,请不要错过这篇文档。YMatrix 数据库支持 Kafka 无缝连接功能,可将 Kafka 数据持续自动导入到 YMatrix 表中,并支持图形化界面操作。 目前接入的数据格式可以是 CSV 和 JSON。我们将以一个最简单的例子,来介绍如何用 YMatrix 管理平台接入 Kafka 数据。
首先你需要搭建一个健康的 Kafka 环境,参照官方指南 Kafka Quickstart 即可。
现在,你已经在服务器上搭建好了 Kafka 环境,你可以通过以下命令或其他方式进入。
$ cd packages/kafka_2.13-3.2.0然后启动 Kafka 服务并创建一个测试主题(Topic),端口号默认为 9092。
$ bin/kafka-topics.sh --create --topic csv_test --bootstrap-server localhost:9092然后分条写入几个测试数据,以 ctrl-c 结束:
$ bin/kafka-console-producer.sh --topic csv_test --bootstrap-server localhost:9092
>1,Beijing,123.05,true,1651043583,1651043583123,1651043583123456
>2,Shanghai,112.95,true,1651043583,1651043583123,1651043583123456
>3,Shenzhen,100.0,false,1651043583,1651043583123,1651043583123456
>4,Guangxi,88.5,false,1651043583,1651043583123,1651043583123456
>^C通过上面命令向新创建的 csv_test 写入了4条数据,分别为 4 条逗号分割的 CSV 行。 准备工作完毕,下面将介绍如何创建 Kafka 数据流来导入数据。
在浏览器里输入 MatrixGate 所在机器的 IP(默认是主节点的 IP)、端口号:
http://<IP>:8240成功登录之后进入主界面,选择 Kafka 数据源。首先以 CSV 文件为例说明步骤。
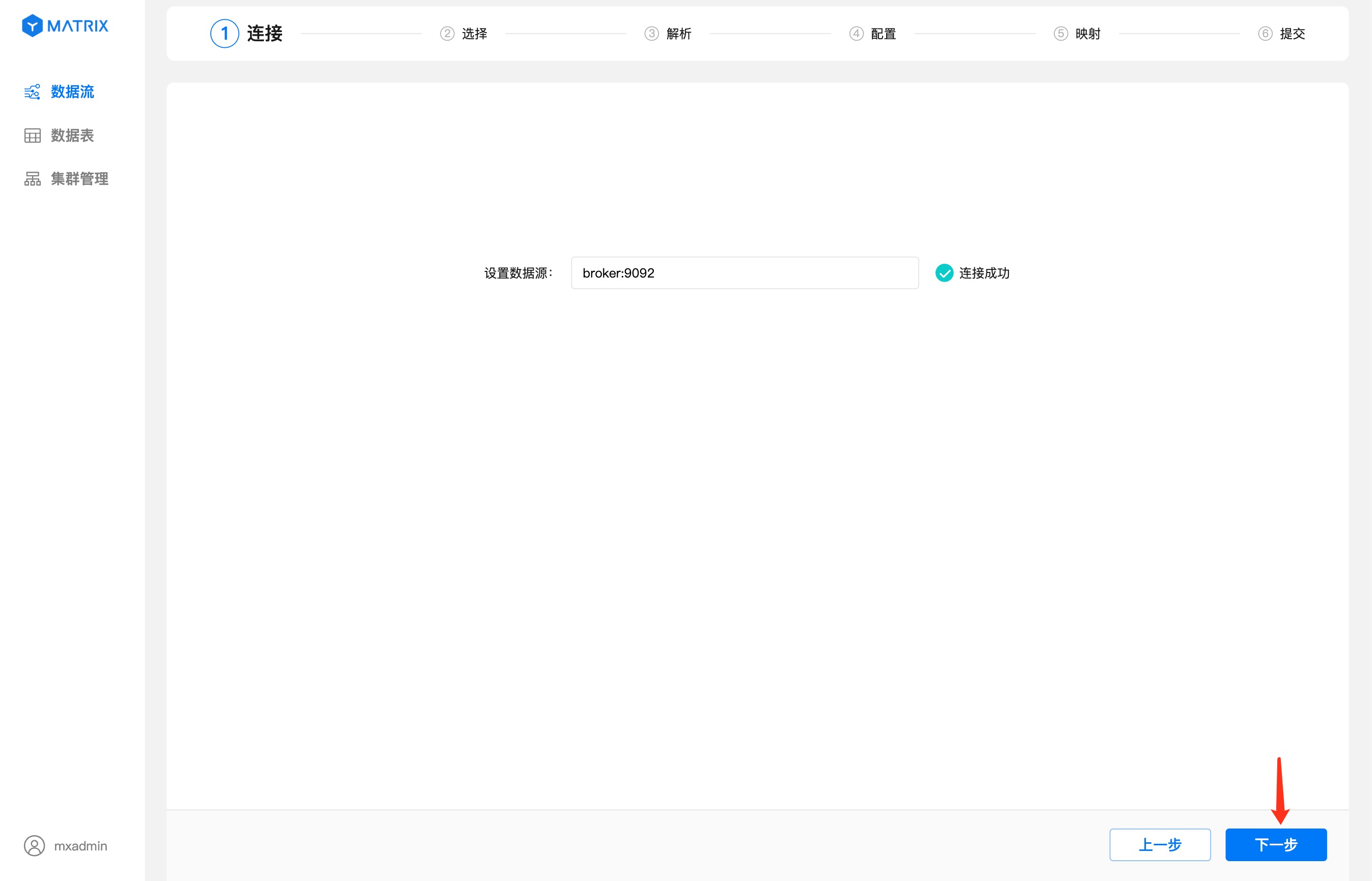
在数据源里输入 Kafka broker 地址,显示连接成功之后,点击“下一步”按钮。如果有多个 URL,需要用逗号分割。
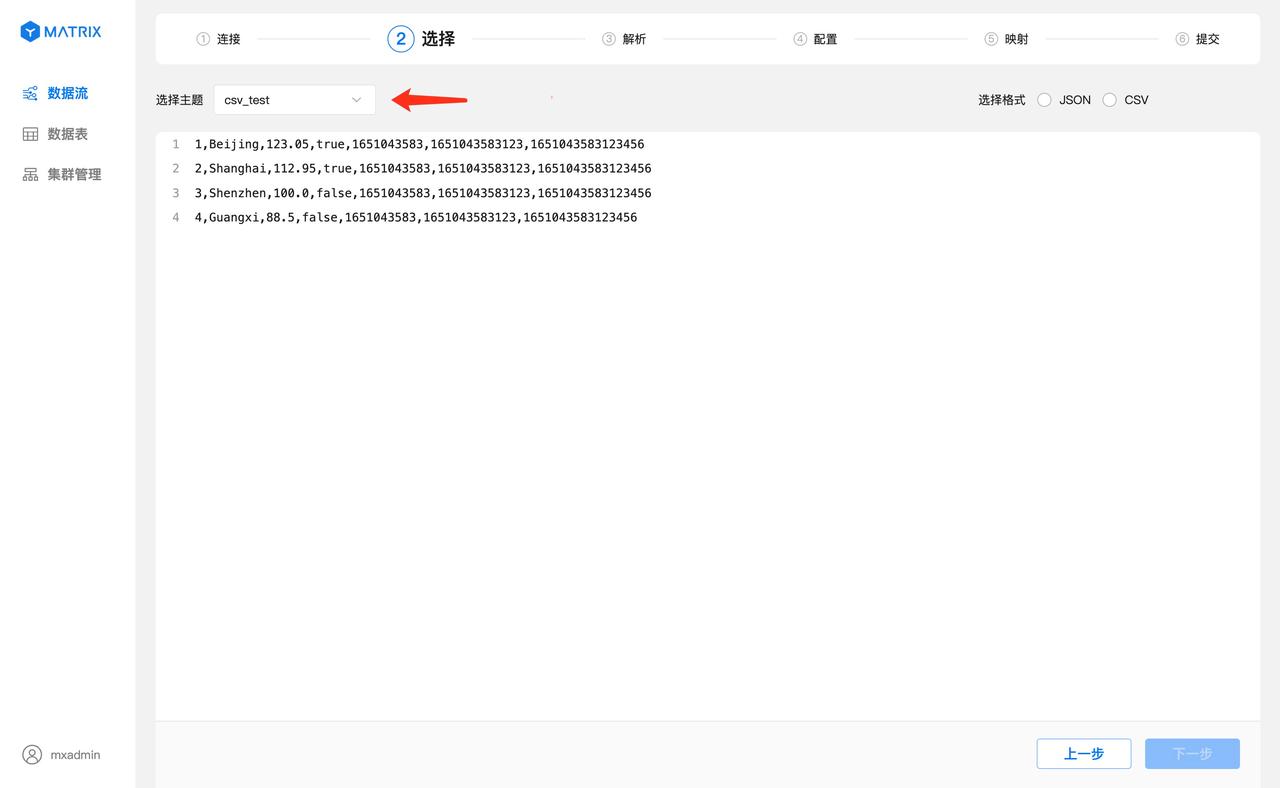
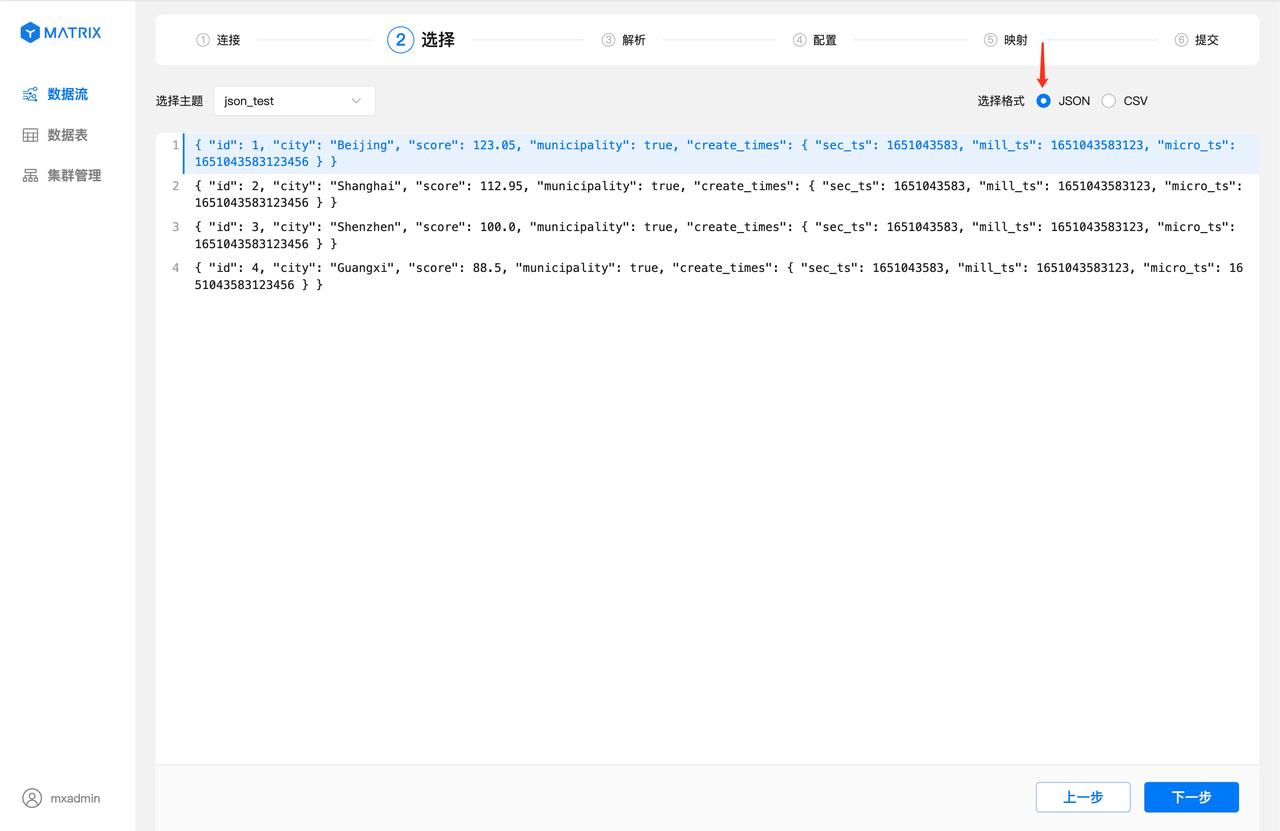
主题选择刚才创建的 csv_test,选择完之后会看到主题中的数据列表。
选中一条数据作为解析与映射的样例数据,再选择 CSV 数据格式,此时会自动根据该样例数据解析出数据使用的分隔符,点击“下一步”按钮。
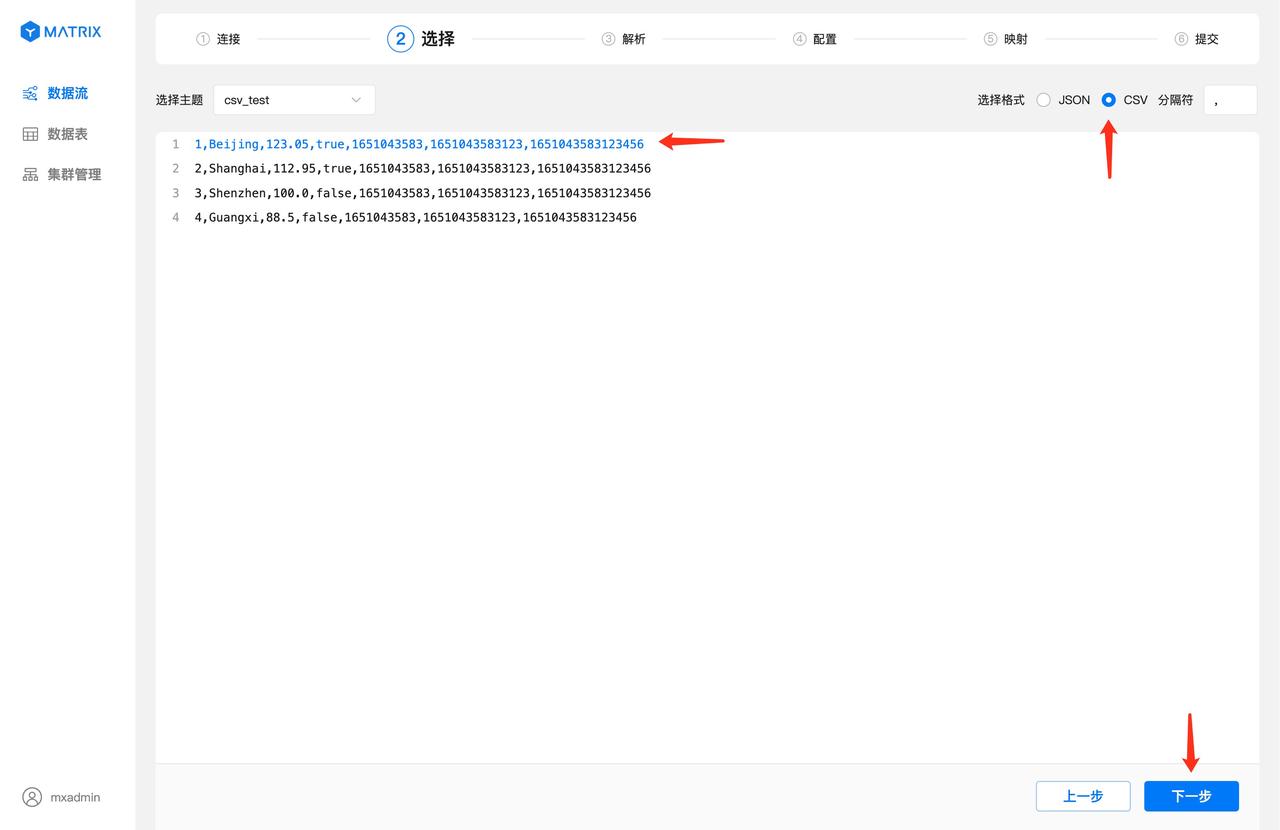
根据上一步选中的样例数据以及数据格式进行解析。字段列显示CSV数据通过分隔符分隔之后每个字段的索引号,值列显示每个索引号对应的值。 确认解析无误后,点击“下一步”按钮。

导入目标表会默认使用新建表,数据库默认使用 postgres,模式默认使用 public,表名默认与 Kafka 主题一致,这里默认为 csv_test。
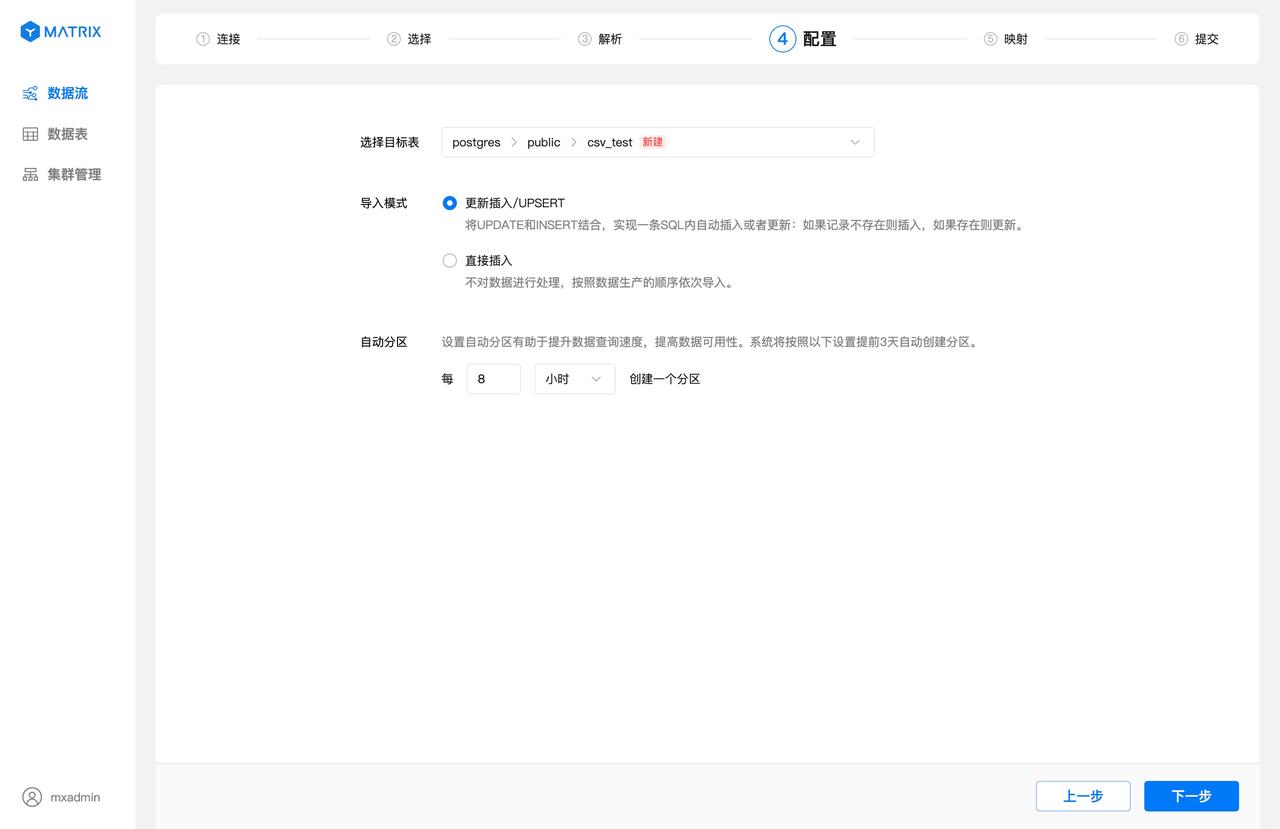
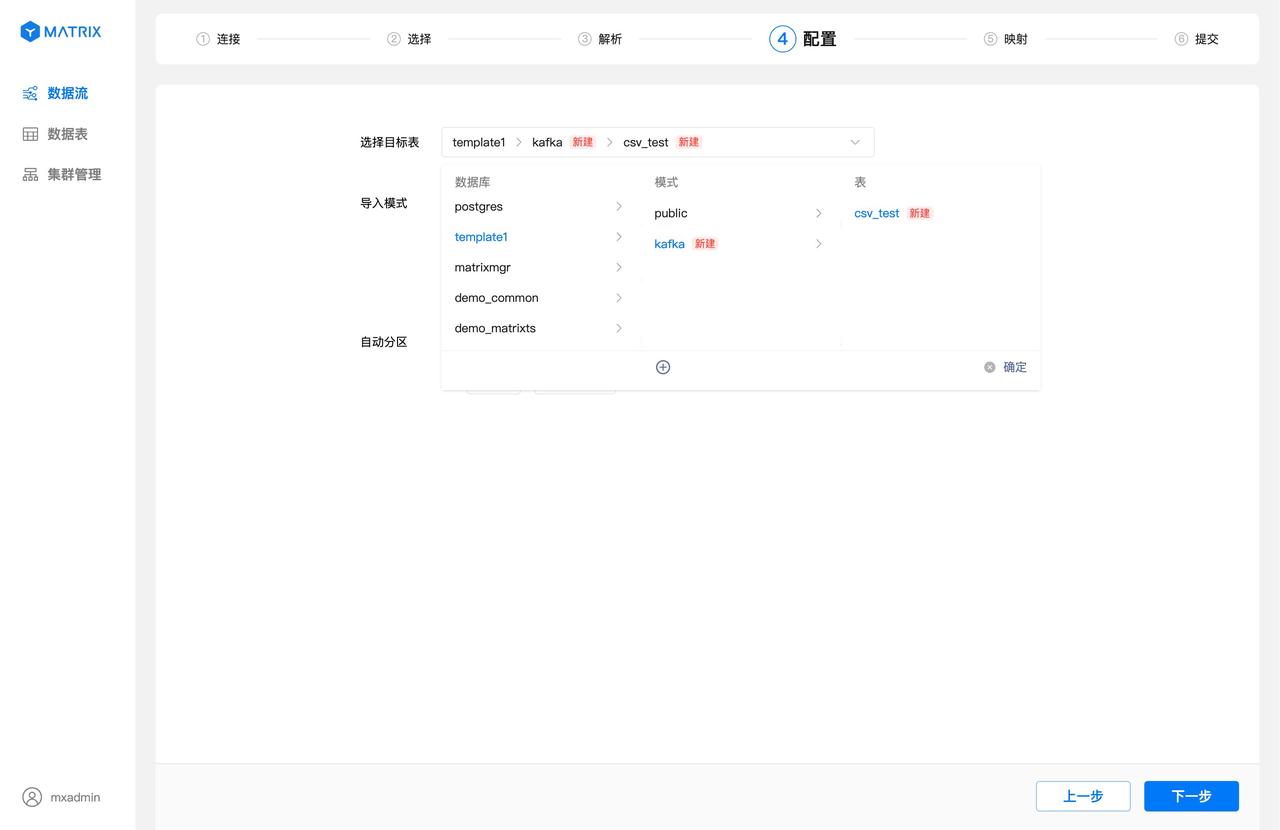
点击目标表选择框,可以选择数据库、模式、表名,也可以新建模式和表名。
选择完导入模式并配置自动分区策略之后,点击“下一步”按钮。
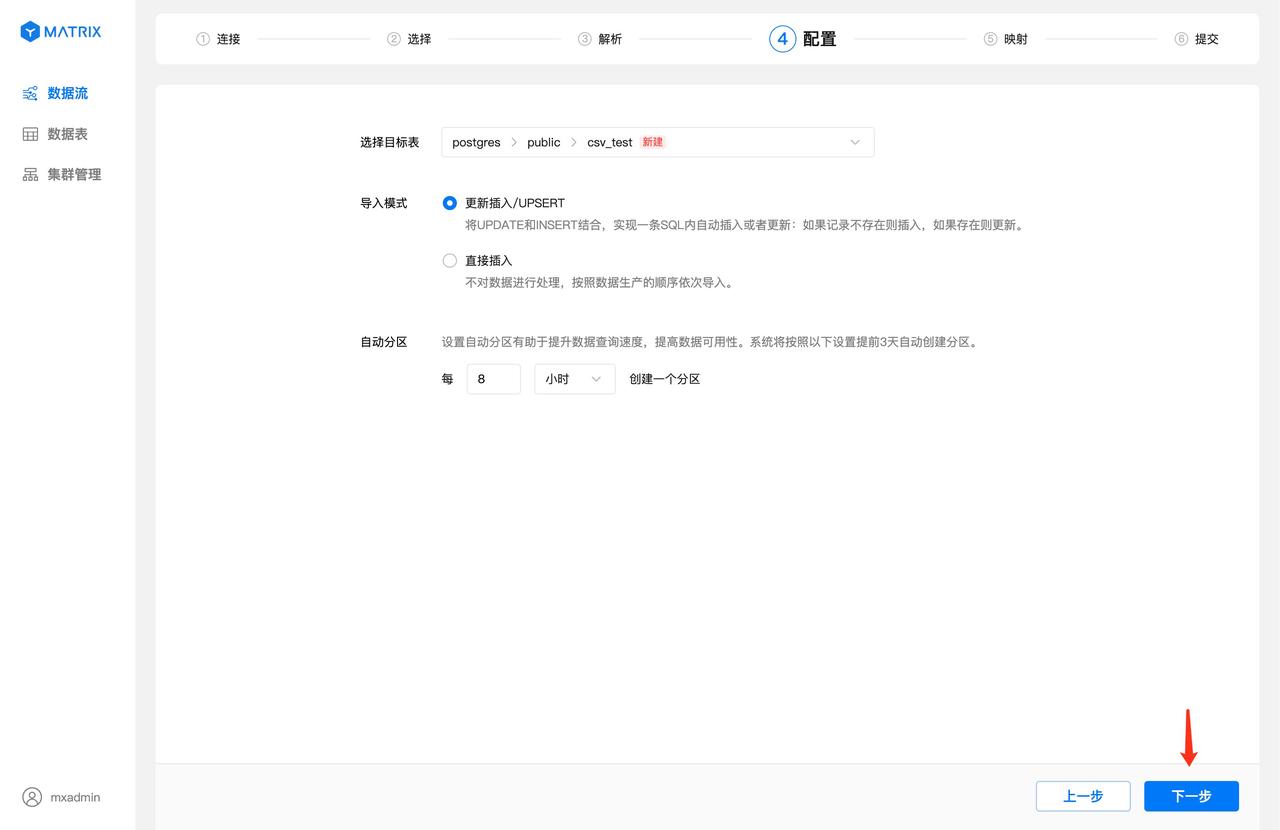
注意!
使用图形化界面创建的表,默认使用 MARS3 存储引擎。更多相关信息请见 MARS3
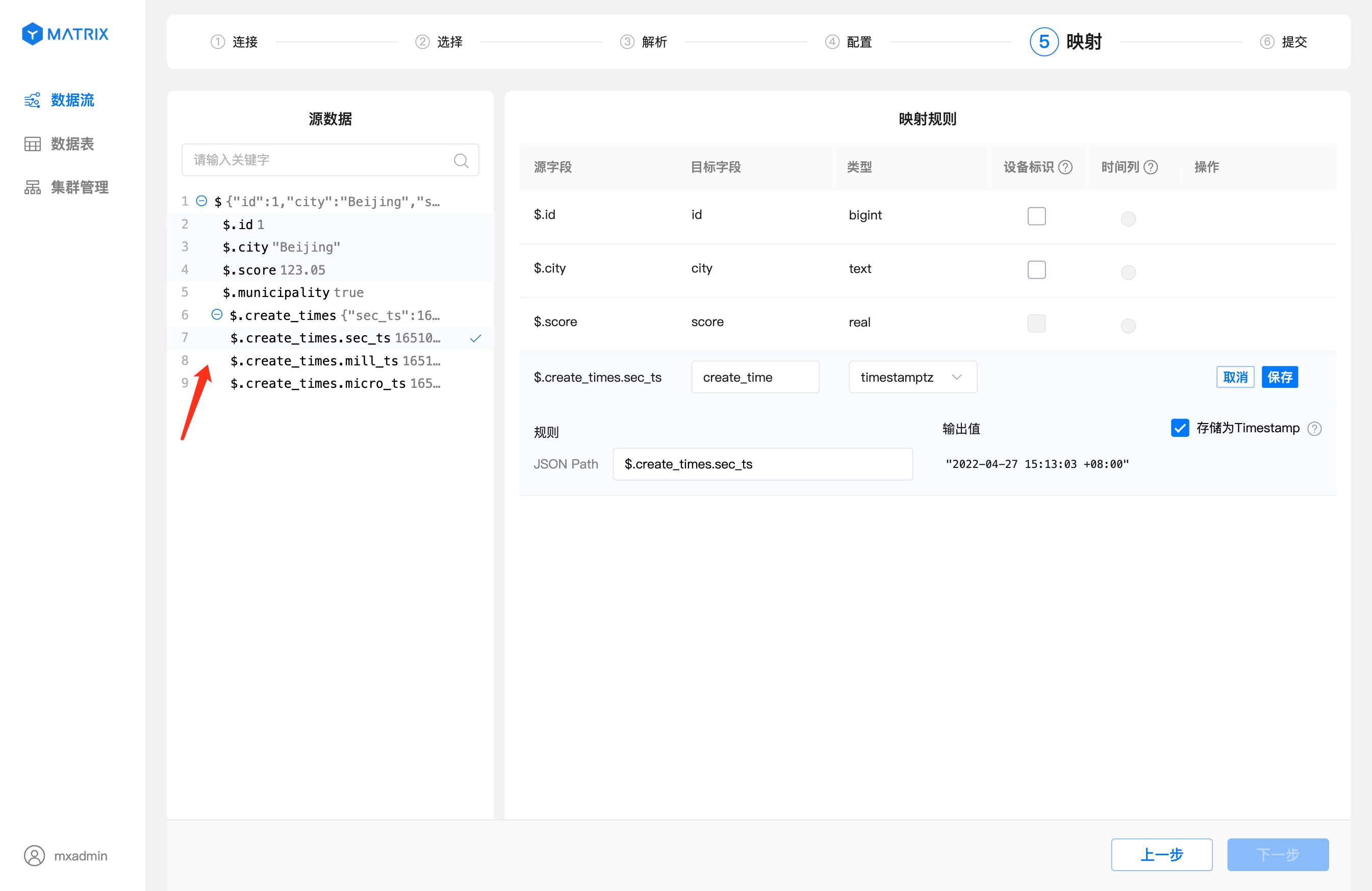
映射页面进行源数据字段与目标表字段的映射。首先选择源数据字段,再在映射规则中设置目标字段相关信息,设置好之后点击保存,即可建立一条映射规则。
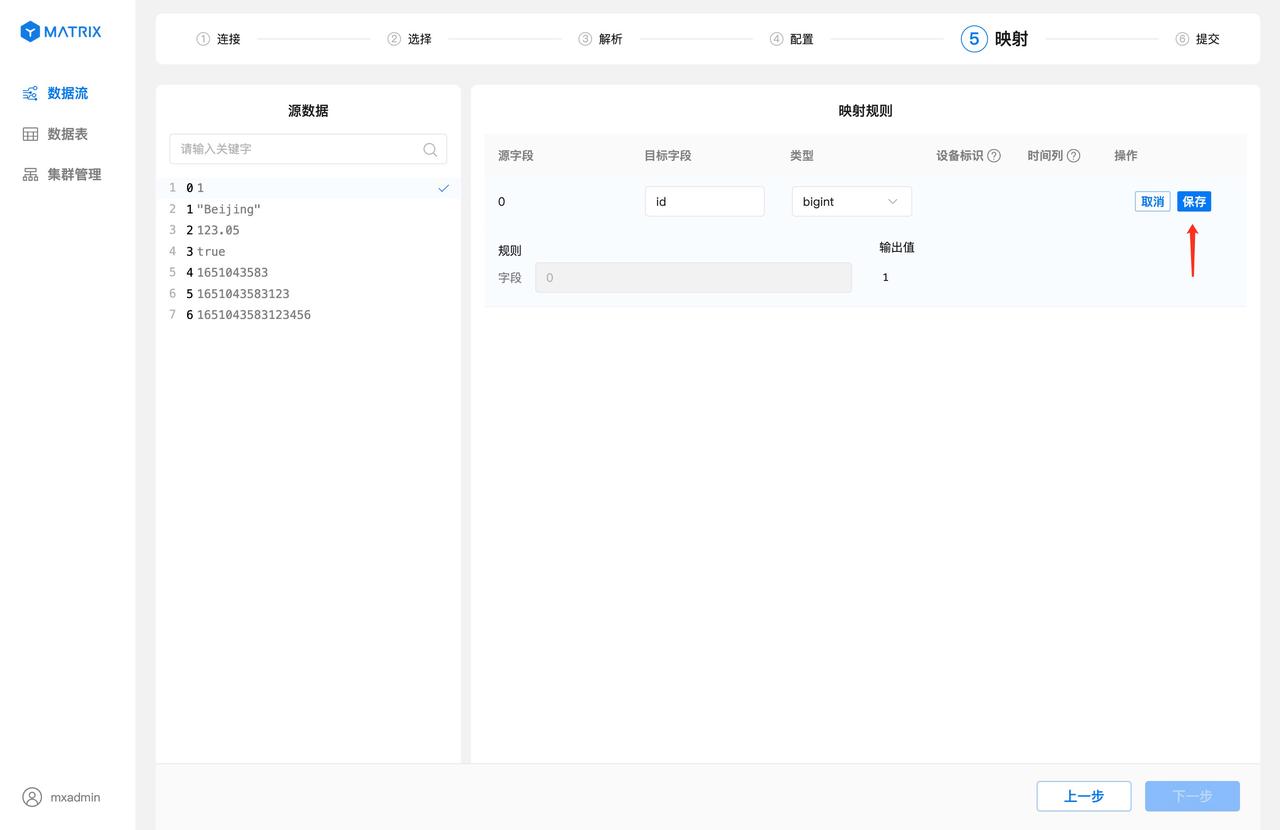
特别的,当源字段值为 UNIX 时间戳且目标字段类型选择为 timestamptz 时,输出值右侧会显示时间戳格式转换复选框,默认为选中状态,输出值结果自动转换为数据库的 timestamptz 格式。
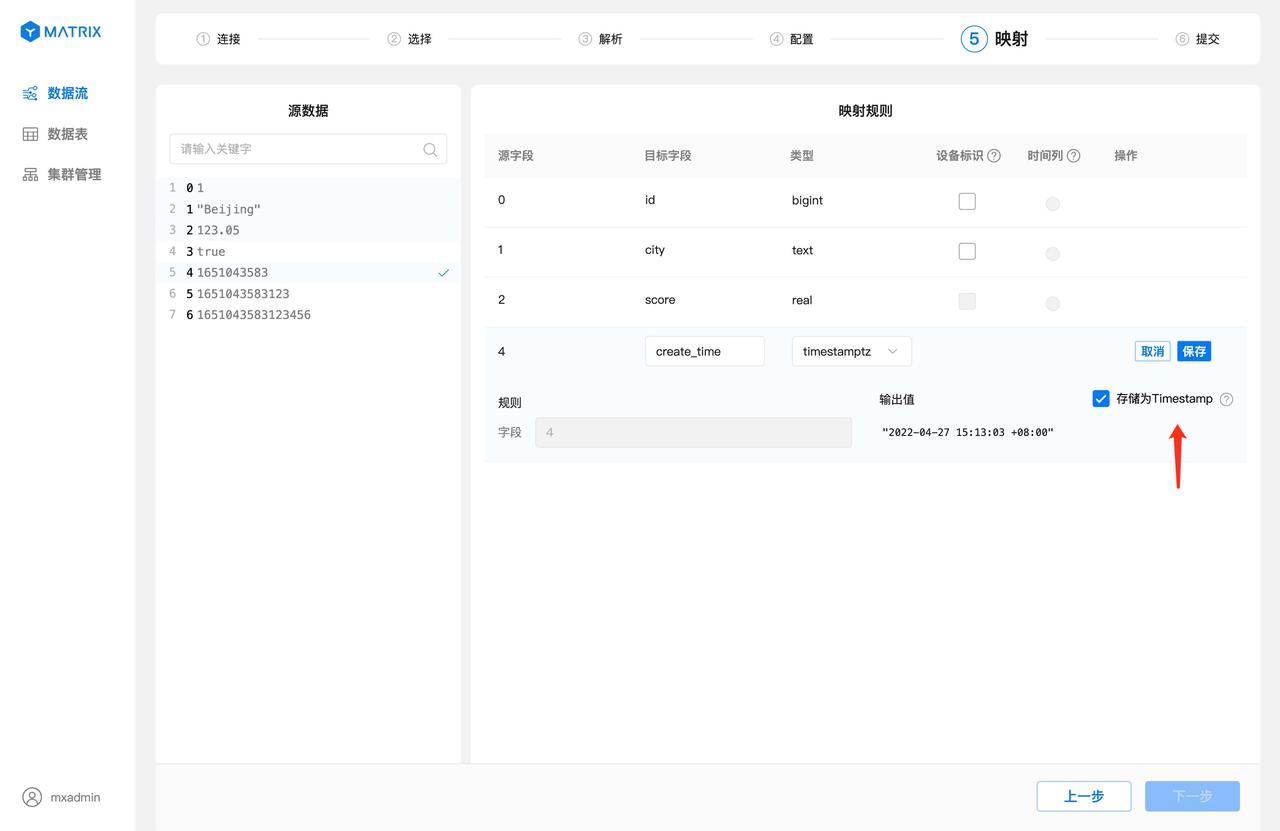
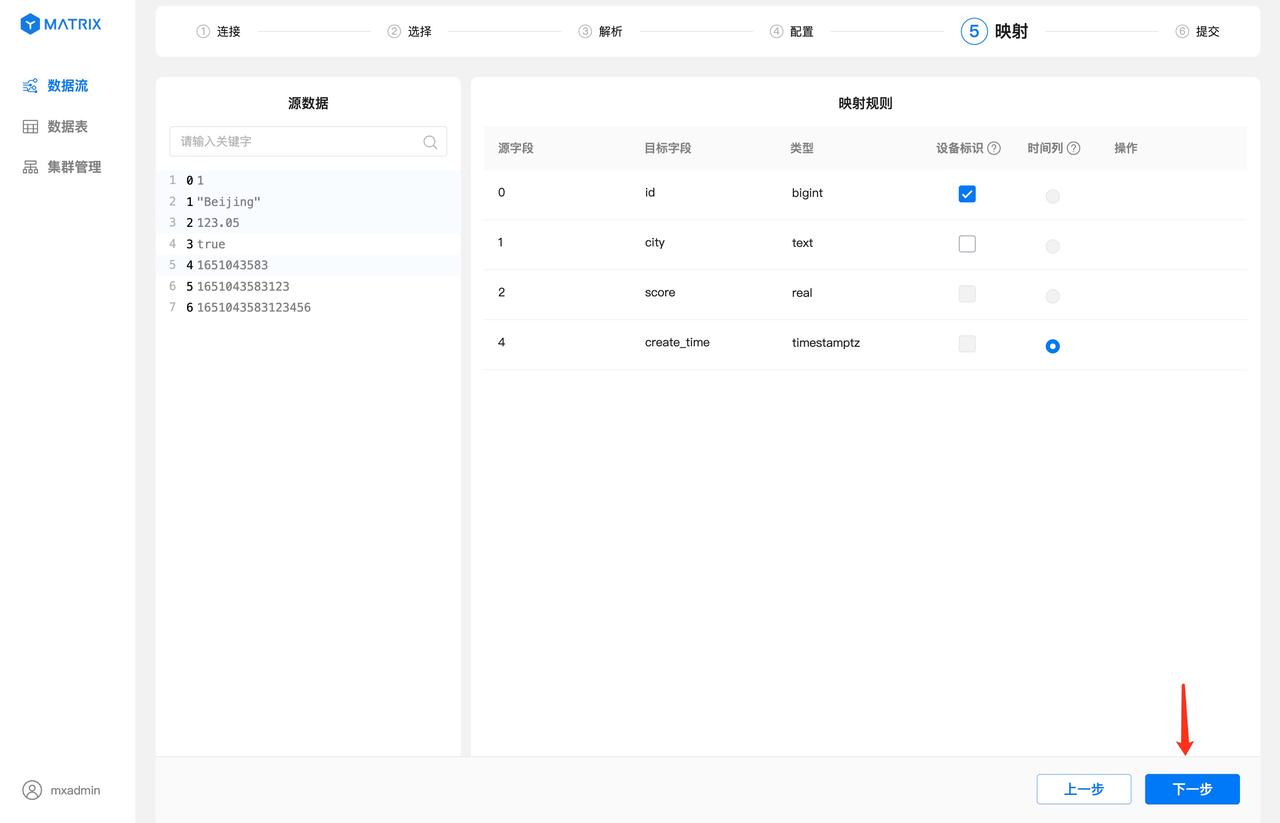
映射规则保存完之后,还需要选择“设备标识”以及“时间列”。“设备标识”选择目标表具有唯一约束的字段或者字段组合,“时间列”选择目标表类型为 timestamptz 的字段。选择完毕后,点击“下一步”按钮。
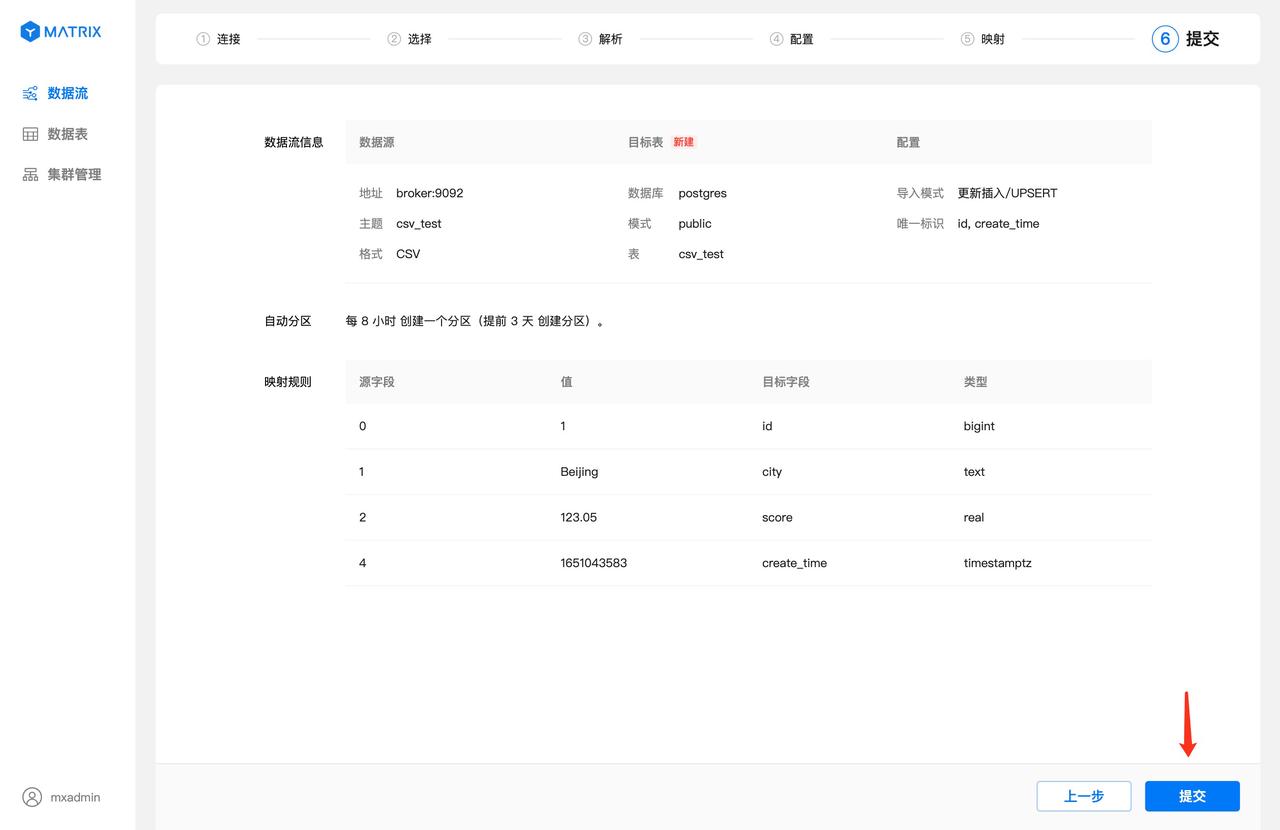
页面展示了数据流所有的配置信息,目标表的唯一标识由“设备标识 + 时间列”组合而成。确认信息后点击“提交”按钮。
提交成功后进入到创建成功提示页面,到此 Kafka 数据流已成功创建。
JSON 格式的数据流,创建过程与 CSV 格式数据流有一些小的差异。
$ 符号开始,. 加列名来索引,索引规则参照 JSONPath。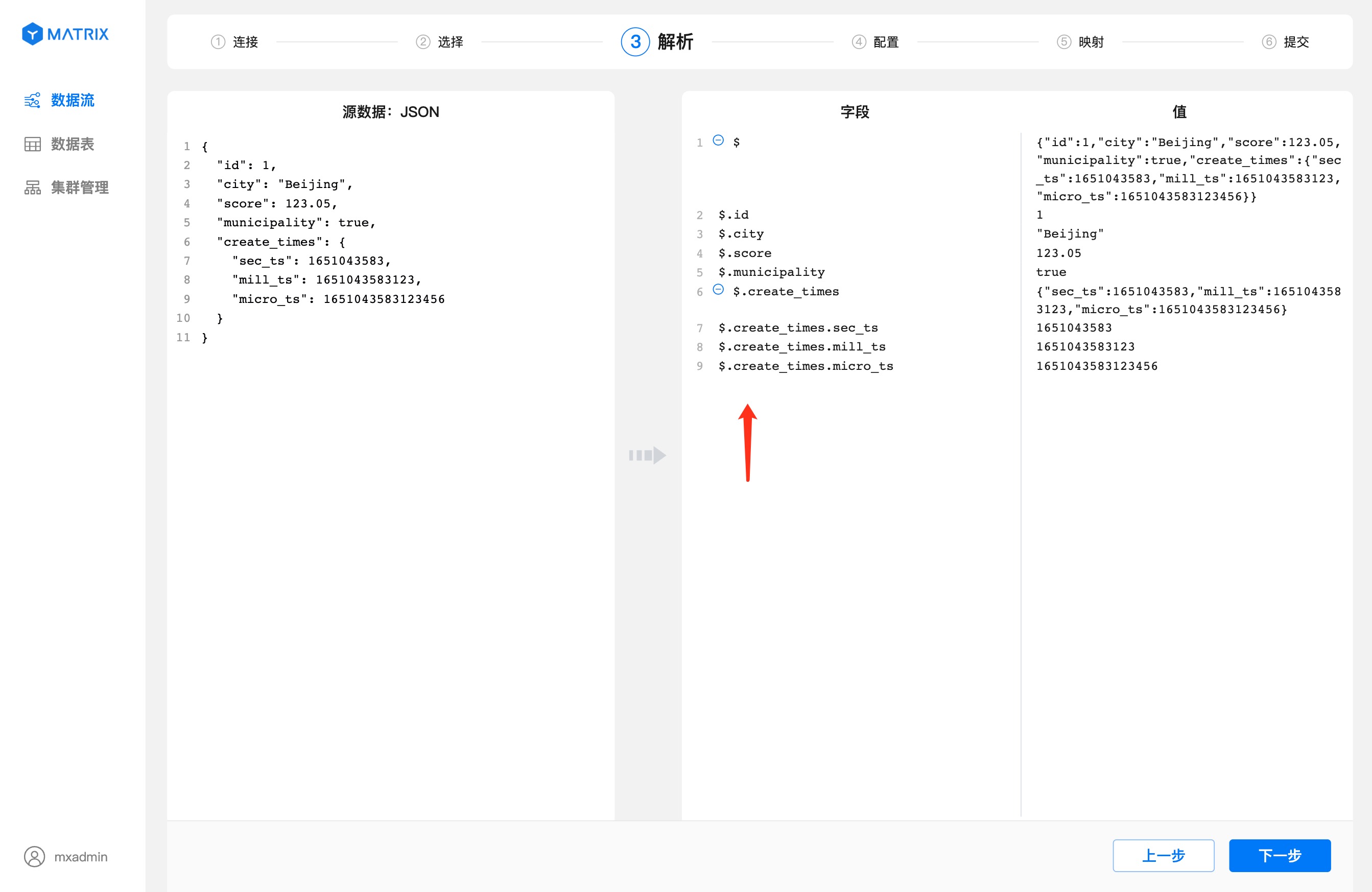
Kafka 数据流列表显示在“数据流”菜单栏的首页,点击右侧的“数据流”菜单项即可回到数据流首页。
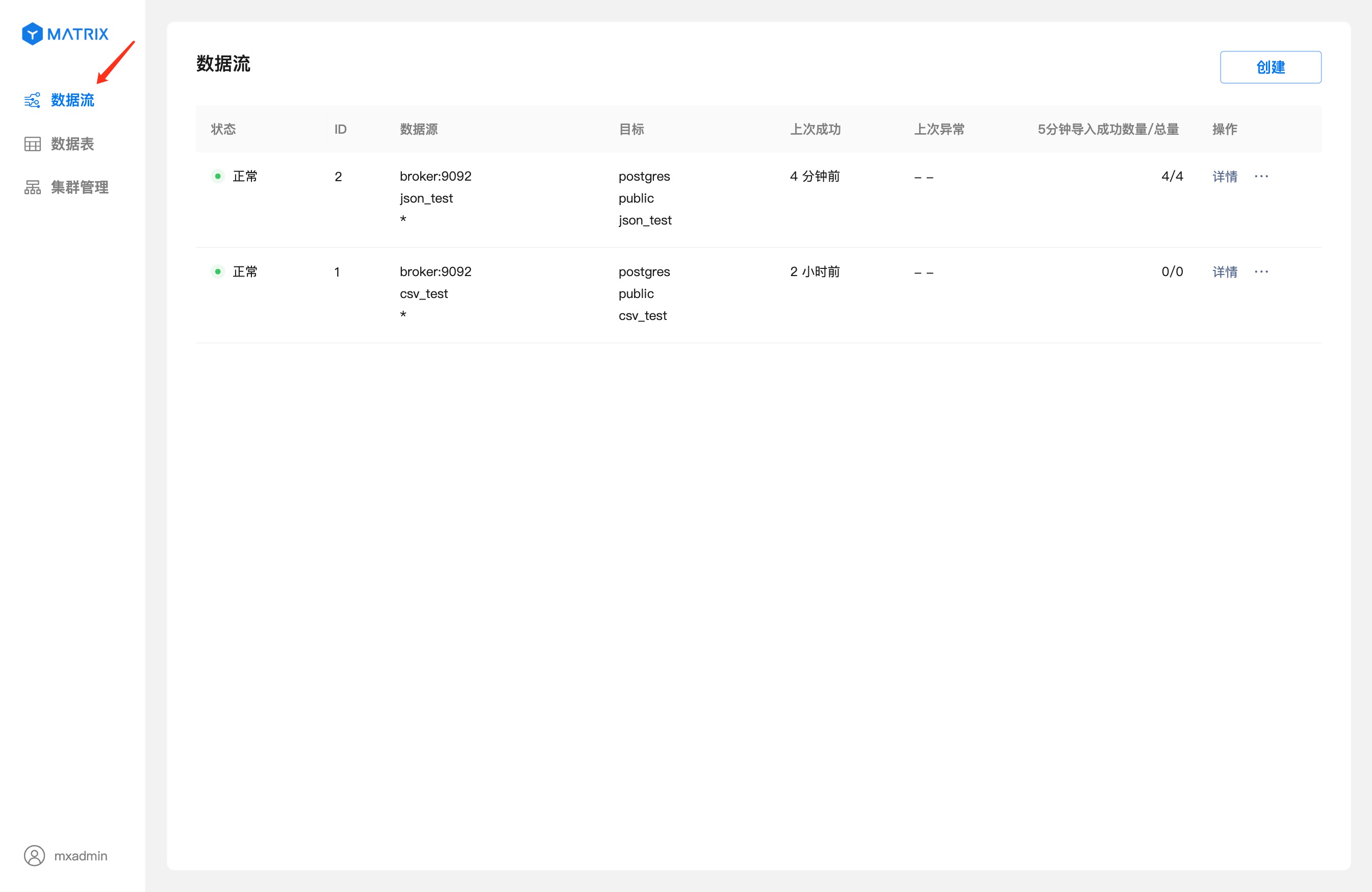
点击“详情”进入到数据流详细信息页。
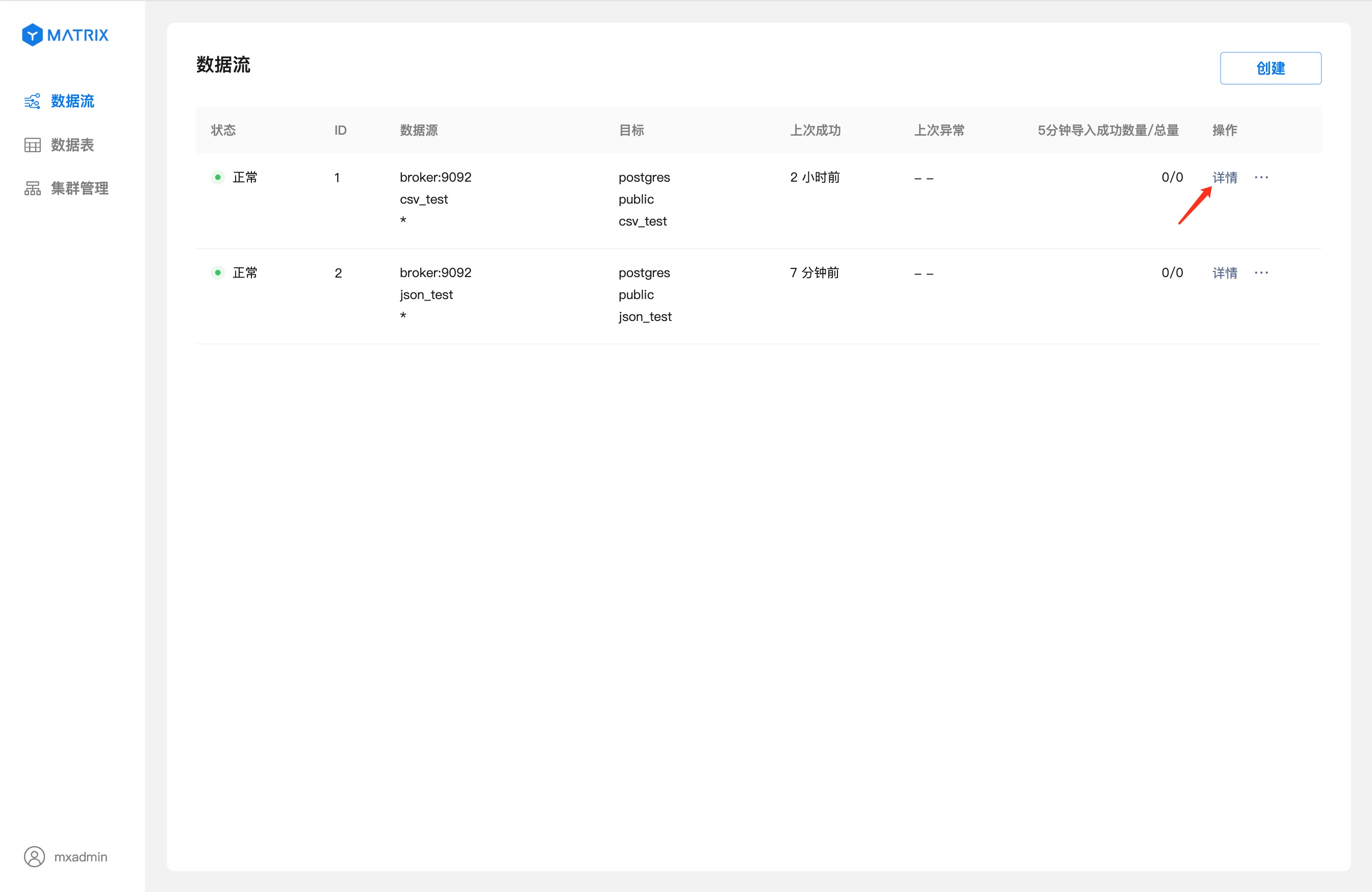
详情页展示数据流的运行状态相关的详细信息。
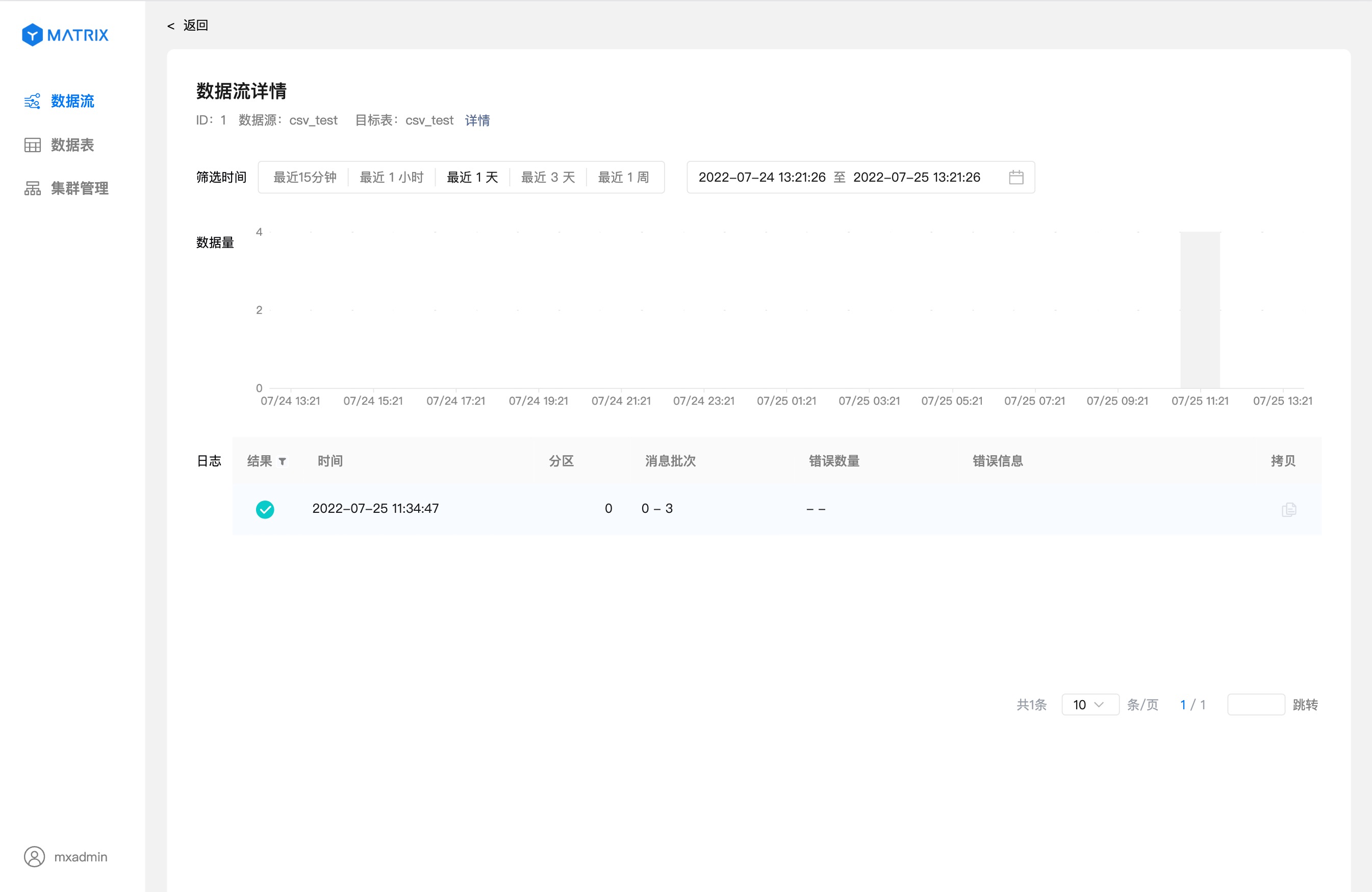
如果想要验证数据流是否正确把数据导入到数据库中,可以通过命令行登录数据库,输入下面的 SQL 进行验证。
postgres=# SELECT * FROM csv_test ORDER BY id;
id | city | score | create_time
----+----------+--------+------------------------
1 | Beijing | 123.05 | 2022-04-27 07:13:03+00
2 | Shanghai | 112.95 | 2022-04-27 07:13:03+00
3 | Shenzhen | 100 | 2022-04-27 07:13:03+00
4 | Guangxi | 88.5 | 2022-04-27 07:13:03+00
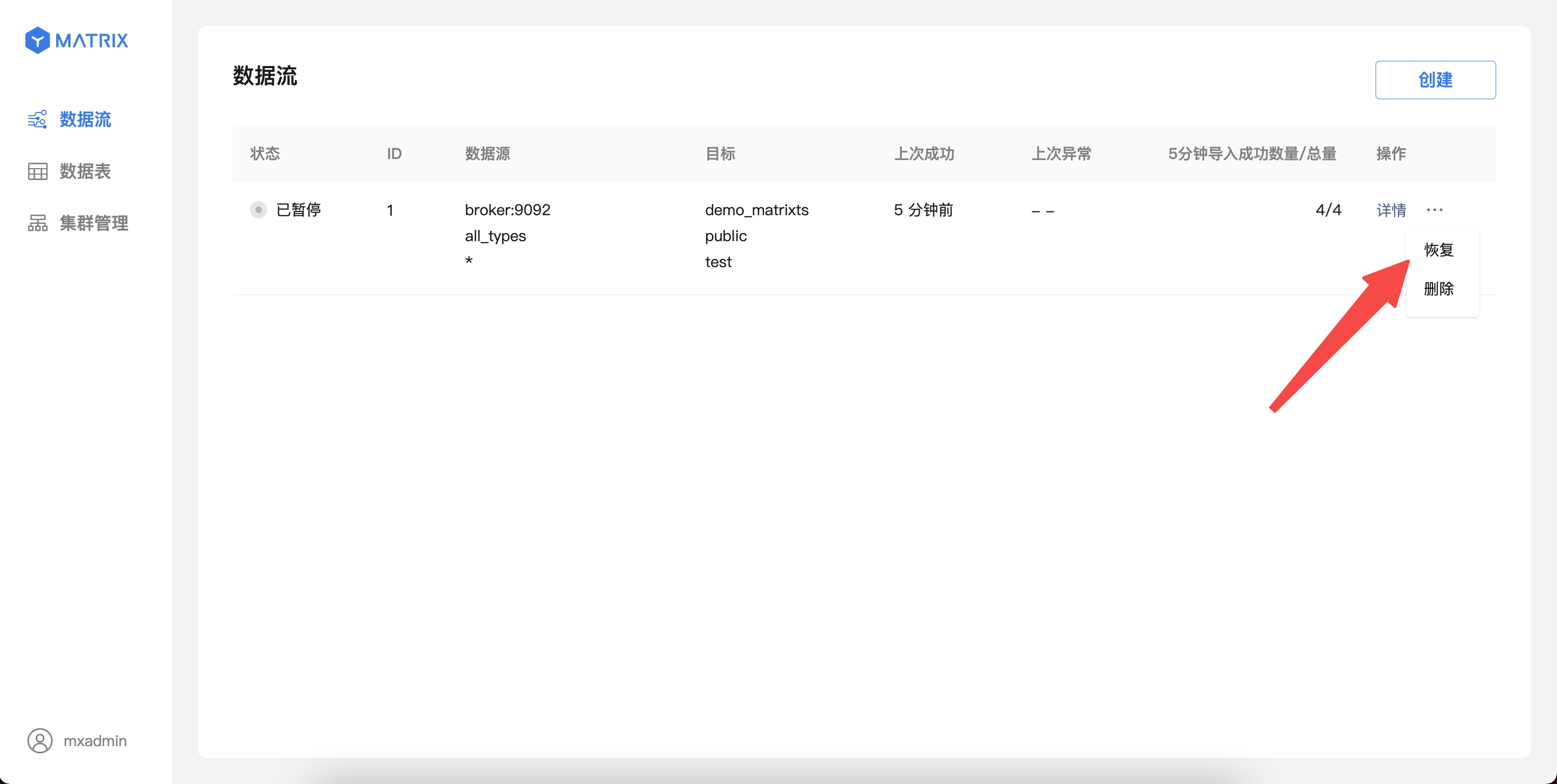
(4 rows)当你使用 YMatrix 图形化界面创建 Kafka 数据流后,数据会持续导入 YMatrix。此时,如因服务调试等原因,你想要临时暂停 Kafka 数据的导入,也可以直接在图形化界面进行操作。
对于运行中的 Kafka 数据流,可以从列表页操作入口暂停数据导入。
注意!
暂停操作可能需要 1-10 秒生效,期间不能对该数据流进行其他操作;暂停操作完成后,Kafka 数据将停止导入,同时状态切换至“已暂停”。
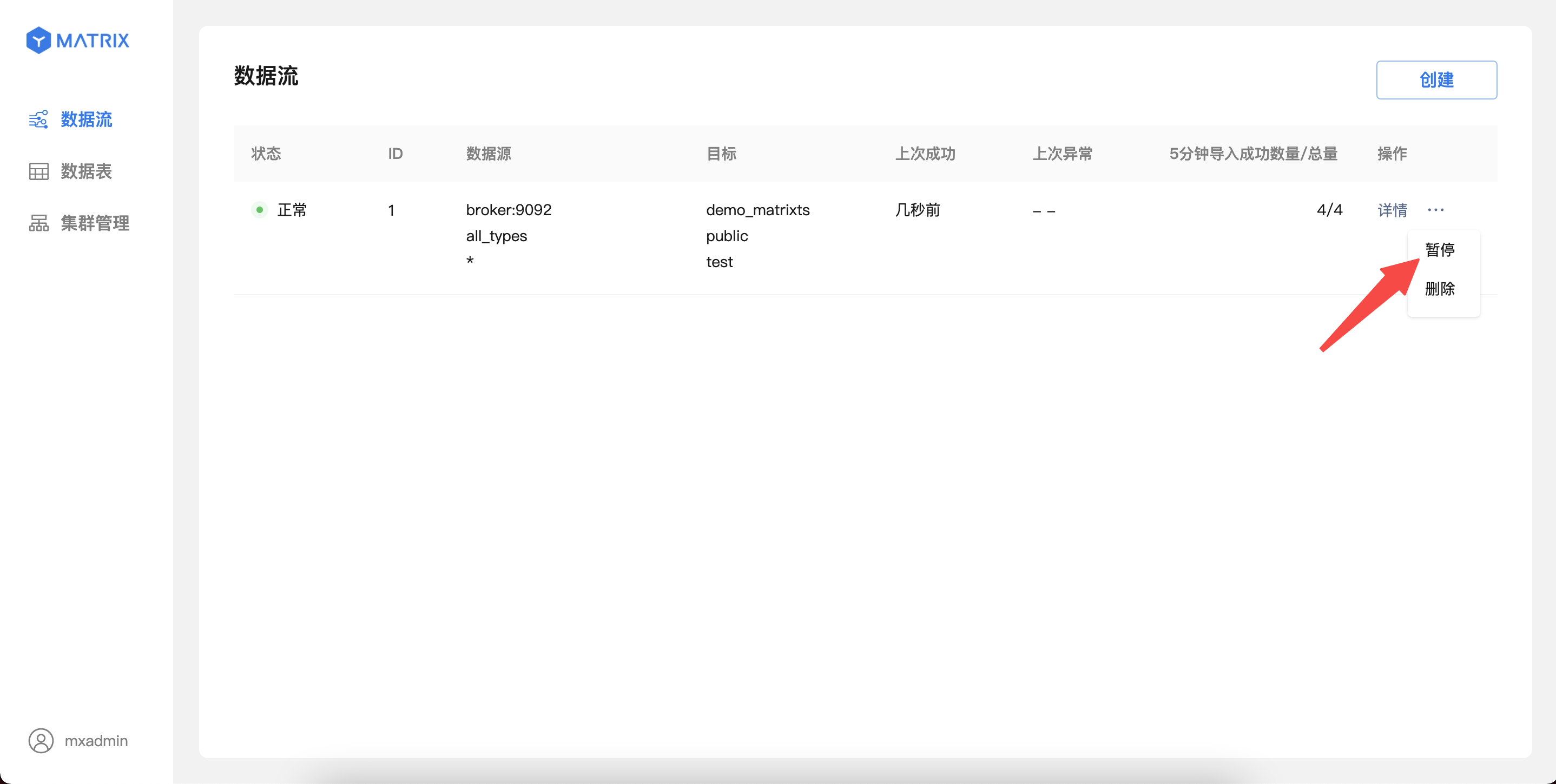
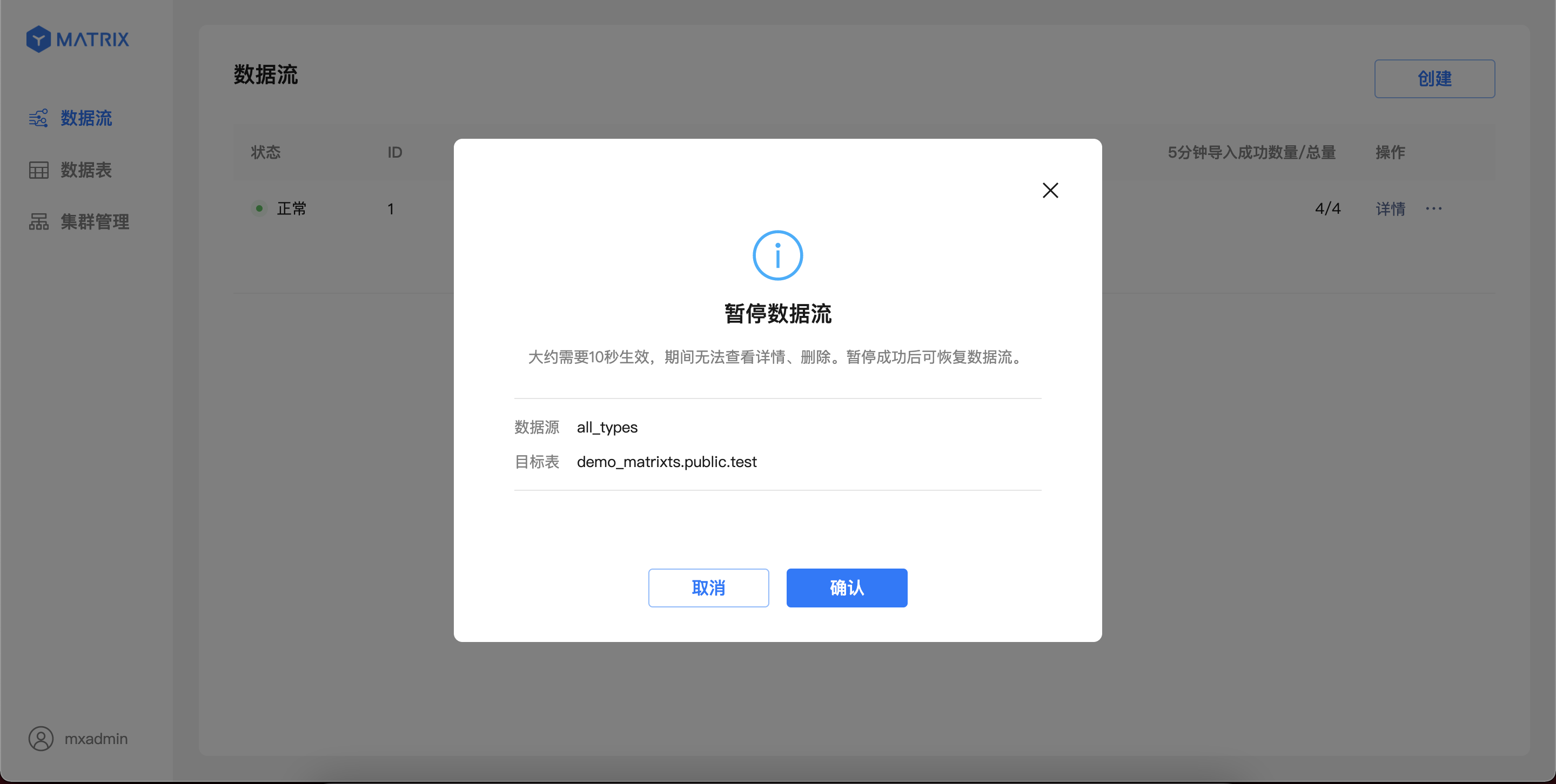
对于处于“已暂停”状态的 Kafka 数据流,可以从列表页操作入口恢复数据导入。确认操作后,数据流会立即恢复导入;页面将在最多 5 秒后恢复显示最新的导入信息。