

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
系统配置参数
SQL 参考
常见问题(FAQ)
新架构 FAQ
集群部署 FAQ
SQL 查询 FAQ
MatrixGate FAQ
运维 FAQ
监控告警 FAQ
PXF FAQ
PLPython FAQ
性能 FAQ
本文档介绍了 Grafana 监控面板中的 YMatrix 相关指标及参考报警阈值。
告警级别说明
注意!
无参考报警阈值的指标,请根据实际情况判断并配置告警条件。

此版块显示了集群的整体运行状态,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 集群状态 | 集群节点状态,包括: 0:正常 1:无 Standby 2:无 Mirror 10:分布不均衡(部分节点宕机恢复后,没有重新平衡主从角色) 11:存在主从不同步节点(部分 Mirror 节点与 Primary 不同步) 12:只有 Master(集群只启动了 Master 节点,通常在诊断时使用) 20:Segment 宕机(存在不可用的 Segment 节点,集群不可用) |
short | p0 | 20:Segment 宕机为严重事件,需要报警 |
| uptime | 正常运行时间。包括 YMatrix 自启动以来的运行时间和 Master 宿主机操作系统运行时间 | seconds(s) | ||
| 版本 | YMatrix 的版本 | |||
| 连接状态 | 连接状态显示了数据库系统中的连接数统计,包括:连接总数(Total)、连接查询被阻塞数(Blocked)、空闲连接数(Idle)、事务中空闲数(Idle in TXN) | short | ||
| Long queries | 慢查询。当前系统中,执行时间超过 1 天的查询数量 | short | p3 | 大于 0 则说明有特别慢的查询,需要报警 |
| 节点状态 | 每个节点的状态,包括: 0:UP(正常) 10:Switched(角色互换,说明出现过主从切换,需要重新平衡) 11:Resync(主从同步中) 20:Down(宕机) |
short | 11、20 两个值需要增加报警 | |
| license_expire_date | LICENSE 过期剩余时间 | seconds(s) | p3/p2 | 过期会导致部分组件不可用,需要尽快处理,30 days-15 days |
| Disk Space in Use | 磁盘使用量。Master 节点或 Segment 节点实例的磁盘使用量 | 0-1 | 报警建议直接在 node_exporter 里设置 | |
| Available | 磁盘空闲空间。Master 节点或 Segment 节点实例的磁盘空闲空间 | 0-1 | 报警建议直接在 node_exporter 里设置 | |
| CPU | 主机 CPU 使用率 | 0-1 | ||
| Memory | 内存使用信息 | 0-1 | ||
| Load | 主机负载 | short | ||
| Transactions | 事务提交与回滚数量统计 | short | 可以设置回滚报警阈值 | |
| DiskIO | 磁盘写入数据量 | bytes | ||
| Network | 网络传输数据量 | bytes | ||
| Process | 各个状态进程数 | short |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Top 10 Disk %Util | 磁盘占用率 Top 10 | 0-1 | 建议在 node_exporter 中配置 | |
| Disk Throughput | 磁盘吞吐量 | bytes | 建议在 node_exporter 中配置 | |
| Disk IOPS | 磁盘读写次数(蓝色读、橘色写,数值取绝对值) | I/O ops/sec | 建议在 node_exporter 中配置 |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| NetStat | 网络状态 | short | 建议在 node_exporter 中配置 | |
| Network Throughput | 网络吞吐量(蓝色接收、橘色发送,数值取绝对值) | bytes | 建议在 node_exporter 中配置 | |
| Network IO | 网络 I/O 次数(绿色接收、黄色发送,数值取绝对值) | io/s | 建议在 node_exporter 中配置 | |
| Packet Loss/Sec | 因为内核缓冲区空间不足导致的丢包数 | short | p3 | 建议在 node_exporter 中配置 |
| Packet Error/Sec | 发送和接收失败的包数 | packet/s | 建议在 node_exporter 中配置 |
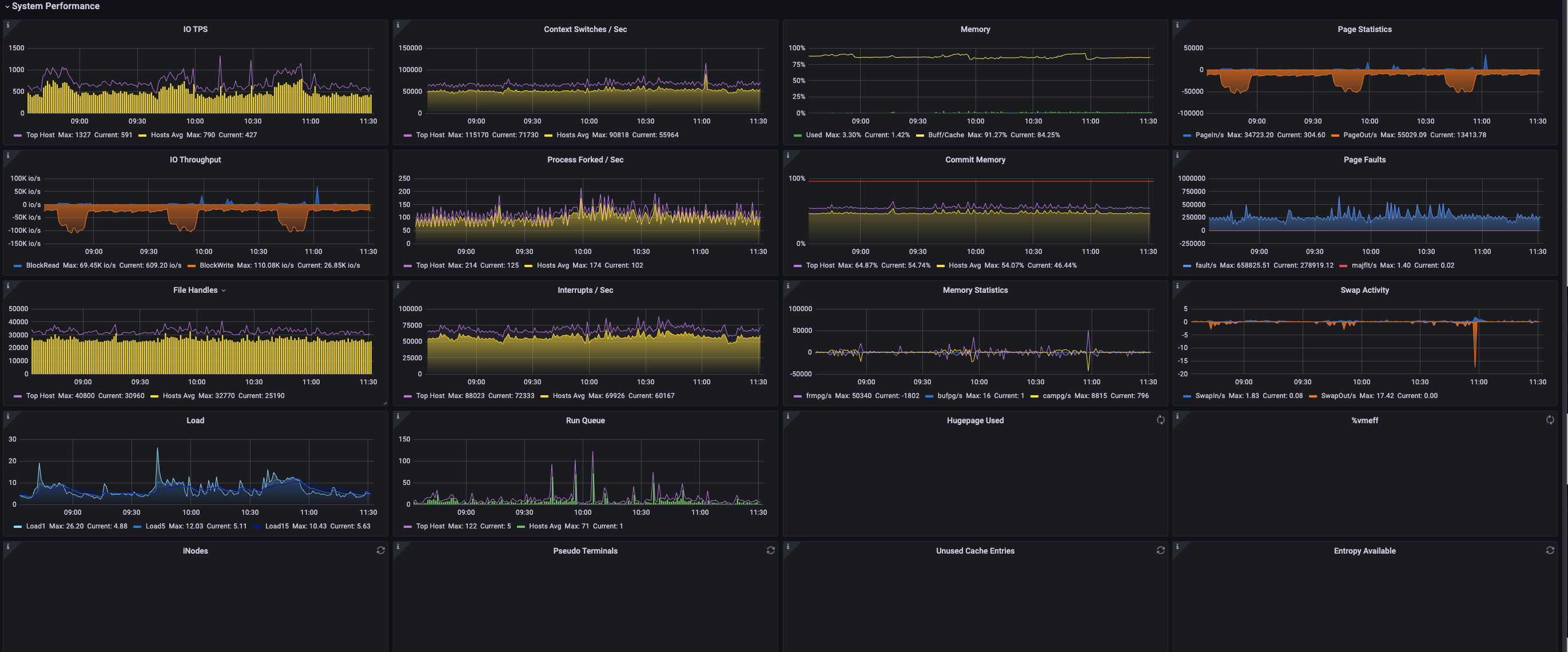
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| IO TPS | 物理磁盘每秒传输总次数。一次传输是对物理设备的一次 I/O 请求。多次逻辑请求会被合并成一次对设备的 I/O 请求。传输数据量不确定 | iops | ||
| Context Switches/Sec | 每秒内核上下文切换量(最大值主机和所有主机平均值) | short | ||
| Memory | Used - 已使用内存百分比 Buff/Cache - 缓存内存百分比 |
0-1 | ||
| Page Statistics | PageIn/s - 系统每秒从磁盘读取页总大小 PageOut/s - 系统每秒向磁盘写入页总大小 注解:2.2.x 及更早的内核版本中,该值为页数量,而不是页总大小 |
KB | ||
| IO Throuhgput | Read - 每秒从磁盘读取的块数 Write - 每秒向磁盘写入的块数 在 2.4 及更新的内核版本中,块和扇区等价,512字节。早期的内核版本块大小不确定 |
iops | ||
| Process Forked/Sec | 每秒 Fork 进程数 | short | ||
| Commit Memory | 当前负载下内存使用量。该值可能大于 100%,因为内核通常会过量使用内存 | 0-1 | p3/p2 | 60% 80%,内存不足,未设置 OOM 保护,可能会被 OOM killer 杀掉 |
| Page Faults | fault/s - 系统每秒出现的页错误。页错误并不一定会引发 I/O 操作,因为有些页错误可以在不发起 I/O 操作下解决 majflt/s - 需要从磁盘加载内存页而引发的页错误 |
short | ||
| File Handles | 系统使用的文件句柄数 | short | ||
| Interrupts/Ses | 中断数 | short | ||
| Memory Statistics | frmpg/s - 系统每秒释放的内存页数。负数表示系统申请的页数 bufpg/s - 系统每秒用于缓冲区的附加的内存页数。负值表示较少的页数用于缓冲区 campg/s - 系统每秒被缓存的附加内存页数。负数表示更少的页数被缓存 注意,机器架构不同,页大小可能为 4KB 或 8KB |
page | ||
| Swap Activity | 系统每秒进出交换分区的页数 | page | ||
| Load | Load1 - 近1分钟的系统平均负载。平均负载是处在可运行状态、正在运行状态和不可中断睡眠状态的任务平均数 Load5 - 近5分钟的系统平均负载 Load15 - 近15分钟的系统平均负载 |
short | p3/p2 | CPU核数 3 / CPU核数 5 |
| Run Quene | 运行队列长度(等待运行的任务数,紫色为所有主机的最大值,绿色为所有主机的平均值) | short | ||
| Hugepage Used | 大页内存使用量 | 0-1 | ||
| %vmeff | 页回收与页扫描的比例。更高的值意味着大部分页扫描后就被回收释放。如果该值为 100% 意味着每个页扫描后即被回收。如果该值比较低(小于 30%),则意味着释放内存比较困难。如果没有页被扫描,该值为 0。所以该值最好是 0 或 100% | 0-1 | ||
| iNodes | 系统使用的 inode 句柄数 | short | p3 | |
| Pseudo Terminals | 系统使用的伪终端数量 | short | ||
| Unused Cache Entries | 缓存目录中未使用的缓存条目数(粉色为最小主机值,黄色为所有主机平均值) | short | ||
| Entropy Available | 系统通过关注不同的事件来收集一些“真实的”随机数,例如:网络活动、硬件随机数生成器等。并将它们提供给 /dev/random使用的内核熵池。需要安全性极高的应用程序倾向于使用/dev/random作为它们的熵源,或者称为随机源 如果/dev/random用完了可用的熵,它就无法提供更多的随机性,并且等待随机性的应用程序会停止,直到有更多的随机材料可用 |
short |
YMatrix Database 界面包含 Database Performance 和 Storage 两个板块。
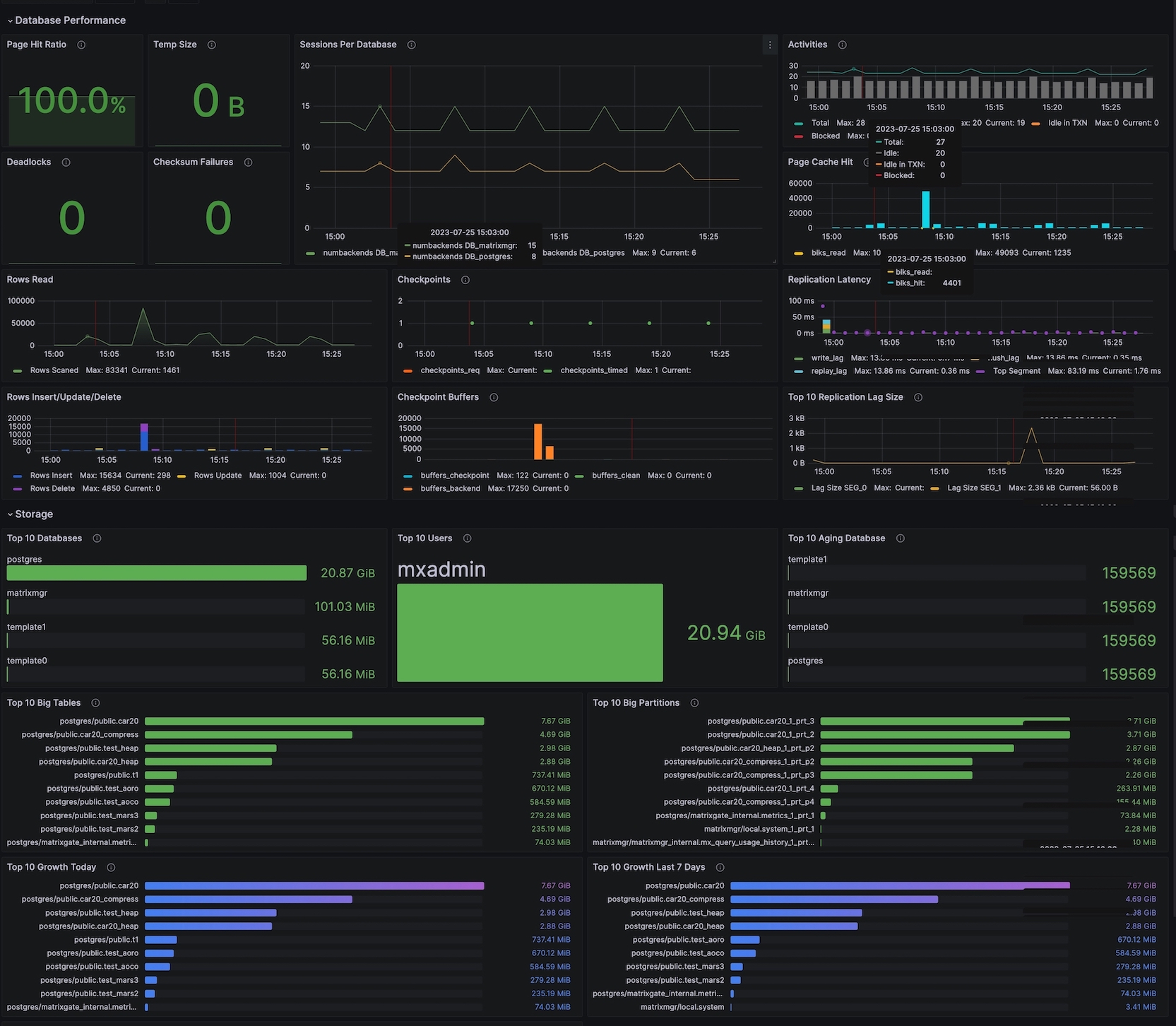
此版块展示了数据库性能,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Page Hit Ratio | HEAP 表读操作命中块缓存次数与读操作总数的比值。(缓存仅包括 HEAP 表自己维护的缓存,不包括操作系统缓存) 显示的数值为当前值,曲线为历史值 通常要求数值在 90% 以上 |
0-1 | ||
| Temp Size | 数据库中查询写入临时文件的数据总量。不管创建临时文件的原因和 log_temp_files 设置,所有临时文件都会被统计 | bytes | ||
| Sessions Per Database | 每个数据库的会话数 | short | p2/p1 | 最大连接 %60 %80 |
| Activities | 各个状态会话数 | short | ||
| Deadlocks | 发现的死锁数量 | short | 大于 0 可报警 | |
| Checksum Failures | 数据库数据页校验失败次数,如果没有开启则为 NULL | short | p3 | |
| Rows Read | 读取数据行数 | short | ||
| Checkpoints | 检查点统计。橘色为主动请求生成检查点的操作次数,绿色为因为超时而自动生成检查点的操作次数 | short | ||
| Page Cache Hit | blks_hit:读取数据页时命中缓存次数 blks_read:未命中缓存而要读磁盘的次数 |
|||
| Replication Latency | write_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL 成功(但尚未刷新或应用它)之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 remote_write 时,提交产生的延迟 flush_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL 并刷盘成功(但尚未应用它)之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 on 时,提交产生的延迟 replay_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL,刷盘并成功应用之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 remote_apply 时,提交产生的延迟 |
milliseconds(ms) | p3 | 建议值:10s 主从同步复制,延迟过高,可能会影响写入事务缓慢 |
| Rows Insert/Update/Delete | 行操作统计 Rows Insert:插入行数 Rows Update:更新行数 Rows Delete:删除行数 |
short | ||
| Checkpoint buffers | buffers_checkpoint - 检查点生成时写入的缓存数 buffers_clean - 后台写进程写入的缓存数 buffers_backend - 工作进程直接写入的缓存数 |
short | ||
| Top 10 Replication Lag Size | Top 10 复制延迟 WAL 大小 | bytes | p3 | 1GB |
此版块展示了存储相关的统计,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Top 10 Database | 数据库大小 Top10 | bytes | ||
| Top 10 Users | 用户数据量大小 Top10 | bytes | ||
| Top 10 Aging Database | 数据库年龄 Top10,当数据库年龄超过 20E 时,会导致数据库不可用 | short | p2 | 1500000000 |
| Top 10 Big Tables | 表大小 Top10 | bytes | ||
| Top 10 Big Partitions | 分区表大小 Top10 | bytes | ||
| Top 10 Growth Today | 当天数据量增长最快的 10 张表 | bytes | ||
| Top 10 Growth Last 7 Days | 7天内数据量增长最快的 10 张表 | bytes |



