

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
系统配置参数
SQL 参考
常见问题(FAQ)
新架构 FAQ
集群部署 FAQ
SQL 查询 FAQ
MatrixGate FAQ
运维 FAQ
监控告警 FAQ
PXF FAQ
PLPython FAQ
性能 FAQ
本文档是“时序数据建模”章节的首篇。YMatrix 认为,数据模型的设计会直接影响到数据消费与使用的价值。因此,除技术介绍外,我们尝试通过整个章节使你对时序数据模型(Time-series Data Model)的概念、应用及发展都有清晰的理解。
信息时代的世界正在以惊人的速度发生变化,这离不开人类对于数据的捕获、分析和利用。地图导航软件、街头的监控摄像头以及供暖公司,每天都通过精准的数据统计为我们的生活服务。但随着科技发展及生活节奏的不断加快,我们不只想知道要前往的地点在哪、怎么走,还想随时了解哪条路通畅,以避开堵塞的路径;政府为保护人民安全监控公共区域,而我们也想买到一款实时健康监测设备,为保障自己的健康而对身体进行实时监测。它必须轻便易携,最好还具有时尚的外观;供暖公司也已不满足于了解一个月内的建筑平均日温度(MDT)变化,而是想要加入智慧城市的发展行列,通过每小时的气温、风速、降水量变化等更精准地提高自身物业建模和优化能源效率的能力......
显然,只进行较长时间周期内的数据统计显然已无法满足人类越发“贪婪”的需求,详细的、功能丰富的数据已成为我们这个信息匮乏的世界中最有价值的商品之一。而在分析需求的过程中,我们认识到这些场景的核心都离不开一种类型的数据:它与时间强相关,来源于各种设备;它随着时间推移不断积累,具有丰富的利用价值;它的体积极大,轻松可达到 TB 甚至 PB 级别,对数据库底层存储性能要求极高。
据其本质特征,早期的学者将它称作:时序数据。
毋庸置疑,时序数据(Time-series Data)是充满变化的,它是业务系统中正在发生的、无限时长的动态电影。它具有丰富而强大的利用价值,不仅可以为企业降本增效提质,还可以为奋斗中的理想者找到合适的开拓方向。在当下,拥有并充分利用它的人才可以说是占领了时代的先机。
具体而言,YMatrix 认为时序数据主要由以下部分构成:
2023-02-10 20:00:00。6.2。_1681725703.png)
综上,我们可以总结出 YMatrix 中时序数据的定义:即时间序列数据,表示与时间强相关的有顺序的一系列数据。应用中通常表现为指标数据在不同时间点采集到的一系列数据点。
时序数据可以跟踪不同时间间隔单位的变化,如毫秒、天甚至年,具有强大的洞察力。我们认为,无论场景或用例如何,所有时间序列数据集都有几个共同点:
采集到的数据总是记录为一个新行。
数据通常按时间顺序到达数据库。
时间是主轴(时间间隔可以是规则的或不规则的)。
实效性。越新的时序数据价值越大,价值密度随时间推移而逐渐降低。
可降采样。降采样即使用 GROUP BY 语句将原始数据按更宽广的时间间隔分组,并统计出每组数据的关键特征信息。降采样不仅可以降低存储开销,还能保留关键数据特征,便于分析数据的历史趋势,预测未来趋势等。
需与关系数据结合才具价值。没有结构化的关系数据提供上下文信息,时序数据就只是一个数字。我们需要充分的结构化信息来对一个数字进行表述。譬如对于一个值为 36.5 的数据点,我们需要理解,它是温度、湿度还是压强?其单位是摄氏度还是帕斯卡?其来源是锅炉、传送带还是轴承?设备位于厂房一区还是二区?等等。关联信息越丰富的数据,其价值常常也更高。
那么时序场景与传统 OLTP(Online Transactional Processing)、OLAP(Online Analytical Processing)场景又有何不同呢? 我们以一个表格来说明:
| 业务场景 | 数据操纵语句(DML) | 写入方式 | 查询需求 | 并发度 |
|---|---|---|---|---|
| 时序 | INSERT / Appendly-only | 高频流式写入 | 基于时间的点查、明细、聚集;关联分析、复杂分析 | 高并发 |
| OLTP | INSERT / UPDATE / DELETE | 高频写入 | 点查 | 高并发 |
| OLAP | INSERT / 少量 UPDATE / 少量 DELETE | 低频批量写入(ETL) | 关联、聚集 | 低并发 |
就时序数据库的开发而言,数据模型是其组织数据的模式,是暴露给用户的接口。用户必须要了解将要使用的数据库基于什么数据模型构建,才能知晓如何使用该库。也就是说,数据库选择建模和存储数据的方式决定了你可以使用它做什么。
就用户使用而言,数据模型则更偏向于定义表元信息的最佳实践,是一个需要根据业务需求事先设计的建模动作。
据统计,时序数据库已成为全球增长最快的数据库类型。
专门为时序场景与时序数据服务的时序数据库在刚刚诞生时,为追求数据规模的快速扩大,大部分以非关系型(Non-relational)数据模型为基础设计构建。但到了今天,随着用户对于时序数据的消费需求逐步深入,非关系数据库的查询性能在很多场景已不足以满足业务层面的使用,无统一的标准接口导致开发人员的学习成本也不断升高,需通过业务层面不断修改程序来满足需求。与此同时,分布式数据库发展蓬勃,使得本来写入性能相对薄弱的关系型数据库有了质的提升。因此,浪潮又逐渐回归了关系型(Relational)数据模型,YMatrix 也在此浪潮之中。
我们同意,长期看来,将所有数据保存在一个系统中必定会大大减少应用程序开发时间、成本,并加快你做出关键决策的速度。
在时序数据模型的开发设计方面,存在着两种截然不同的观点:
实际上,以上两种模型在时序数据库的发展历程中都发挥了非常重要的作用。起初,由于时序数据极快的积累速度,早期开发人员认为传统的关系模型很难承载此类规模的大数据集,而数据入口简易的非关系型数据模型则在规模承载上表现更佳。因此,时序数据库以非关系型模型发展起来。
非关系型数据库产品如 InfluxDB 决心自我挑战,从零开始写数据库,凭借着其在运行速度、规模扩大等方面的优势取得了很好的初步成果。但是随着业务需求的不断变化、发展,广大数据消费者逐渐发现一开始非关系库吸引自己的低门槛儿(通常其不需要过多进行前期的数据模型设计,可以快速上手开始业务),在系统越发壮大、复杂后也越发难以掌控。由于没有通用的查询语言,无论是数据库的开发还是运维人员,都必须要补上这份“技术债务”,甚至还要自学更加高阶的编程语言来实现更多、更复杂的查询和运维需求。
越来越昂贵的成本与越来越窄的用户接口,使得非关系时序库的用户难以负担,开始试图回归关系库(关系库中数据库本身的“负担”逐渐加重,而人逐渐从运维重担中解脱出来),并且发展成为了一个浪潮。
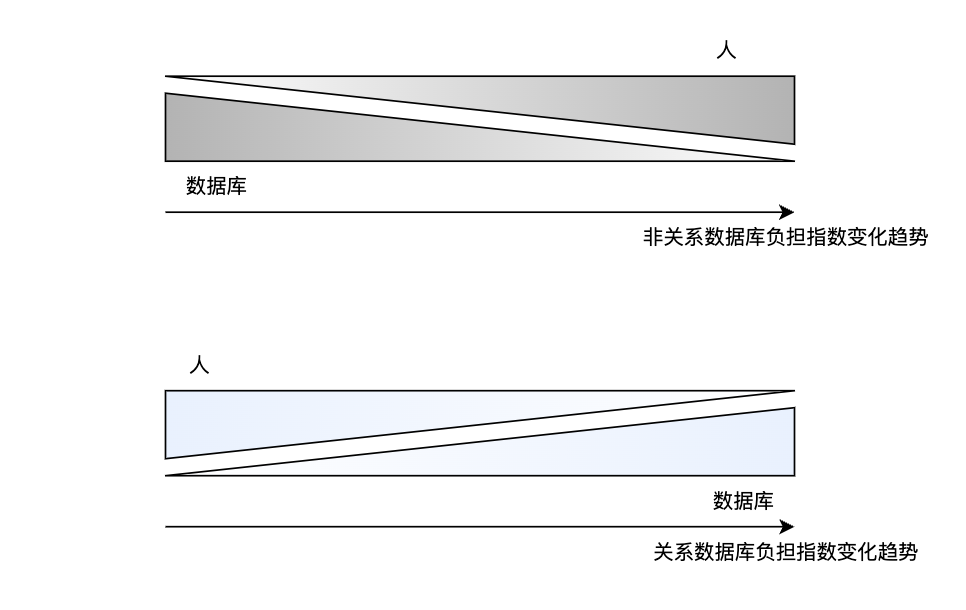
我们这里说的“回归”,并非是一种数据库技术的回退,而是在传统关系库基础上设计新的、符合时序场景特征的变式。例如下文将“结构化”与“半结构化”相结合的的宽表变式。
由于时序应用旨在存储大量与时间相关的信息,对底层数据存储进行数据建模是必不可少的。 关系数据模型以关系数据表的外化形式描述信息。
由于 YMatrix 以关系数据模型为基础构建,所以你可以通过多种方式设计分区表的 DDL(或泛称表的 Schema)。一般来说,有两个主要的存储模式:窄表(Narrow)和宽表(Wide)。
| 窄表 | 宽表 | 窄表变式 | 宽表变式 | |
|---|---|---|---|---|
| 前期设计成本 | 低 | 较高 | 较低 | 较高 |
| 扩展难度 | 容易 | 较复杂 | 较容易 | 较容易 |
| 空间开销 | 大 | 小 | 较大 | 小 |
| 查询性能 | 低 | 高 | 较低 | 高 |
注意!
宽表、窄表、窄表变式、宽表变式详细介绍请见 时序建模思路;具体场景下的模型构建示例请见车联网场景下的数据建模示例及 智能家居场景下的数据建模示例。



