

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
MatrixDB 4 可以安装在支持 x86_64 平台的操作系统上:Red Hat 7、CentOS 7;支持 ARM 64 平台的操作系统上:银河麒麟 V10 。
注意!
麒麟系统等国产化平台仅在企业特性中支持,此文档安装步骤不适用。如有需要请联系售前人员:info@ymatrix.cn。
本文档描述了在多台服务器上快速部署使用 MatrixDB 4 集群的步骤,以三个节点为例,主节点为 mdw,两个数据节点分别为 sdw1 和 sdw2。
本课程教学视频请参考 MatrixDB 安装与部署
注意!
MatrixDB 安装环境需至少支持 Haswell 及以上的 Intel 处理器架构,或 Excavator 及以上的 AMD 处理器架构。
服务端安装过程包括查看服务器基本信息、安装准备、数据库 RPM 包安装、Python 依赖包安装、数据库初始化和安装后设置共 6 个环节。
在进行安装操作前,先查看服务器基本信息。无疑,这是一个好习惯,了解一台服务器有助于你更好的规划部署集群。
| 步骤 | 命令 | 用途 |
|---|---|---|
| 1 | free -g | 查看操作系统内存信息 |
| 2 | lscpu | 查看 CPU 数量 |
| 3 | cat /etc/system-release | 查看操作系统版本信息 |
| 4 | uname -a | 以如下次序输出所有内核信息(其中若 -p 和 -i 的探测结果不可知则被省略):内核名称;网络节点上的主机名;内核发行号;内核版本;主机的硬件架构名称;处理器类型(不可移植);硬件平台或(不可移植);操作系统名称 |
| 5 | tail -11 /proc/cpuinfo | 查看 CPU 信息 |
在所有节点上,通过 root 用户执行下列操作。
MatrixDB 4 需要 Python 3.6,请使用下列命令安装并将 Python 3.6 设为默认版本:
yum install centos-release-scl
yum install rh-python36
scl enable rh-python36 bash安装 parquet 依赖
yum install -y epel-release || yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-$(cut -d: -f5 /etc/system-release-cpe | cut -d. -f1).noarch.rpm
yum install -y https://apache.jfrog.io/artifactory/arrow/centos/$(cut -d: -f5 /etc/system-release-cpe | cut -d. -f1)/apache-arrow-release-latest.rpm
yum install -y arrow-libs-3.0.0 parquet-libs-3.0.0关闭防火墙:
systemctl stop firewalld.service
systemctl disable firewalld.service关闭 SELinux, 编辑 /etc/selinux/config,将 SELINUX 的值设为 disabled:
sed s/^SELINUX=.*$/SELINUX=disabled/ -i /etc/selinux/config
setenforce 0确保所有节点上有持久不变的主机名,如果不存在,请用下述命令设置主机名,例如,在主节点可以这样设置:
hostnamectl set-hostname mdw两个子节点也分别设置对应的主机名:
hostnamectl set-hostname sdw1hostnamectl set-hostname sdw2确保集群中所有节点都可以相互通过主机名、IP 访问。在 /etc/hosts 添加记录,将主机名映射为一个本地网卡地址。例如,三个节点的 /etc/hosts 都包含类似这样的内容:
192.168.100.10 mdw
192.168.100.11 sdw1
192.168.100.12 sdw2在所有节点上,用 root 用户执行下述 yum 命令安装数据库 RPM 包,系统依赖库会一并自动安装。缺省会安装在 /usr/local/matrixdb 目录下:
yum install matrixdb-4.0.0-1.el7.x86_64.rpm注意:在实际安装过程中,请将文件名替换成最新下载的 RPM 包名
安装成功后,会自动启动 supervisord、cylinder、mxui 进程。这些后台进程用于提供图形化操作界面、管理和控制集群等。
在所有节点上,用 root 用户执行下述命令安装 MatrixDB 所依赖的 Python 包,请注意,source greenplum_path.sh 必须执行,以便可以安装正确版本的依赖包:
source /usr/local/matrixdb/greenplum_path.sh
yum install gcc python3-devel
pip3 install --upgrade setuptools
pip3 install argparse psutil pygresql pyyaml 这里仍然使用 MatrixDB 提供的图形化部署。远程图形化部署需要服务器 8240 和 4617 端口可以访问。安装完成后,所有节点的这些端口会默认打开。图形化 UI 服务由 mxui 进程提供。
使用浏览器访问以下图形化安装向导 URL,IP 为 mdw 服务器的 IP:
http://<IP>:8240/安装向导的第一个页面,需要填写超级用户密码,在 /etc/matrixdb/auth.conf 中可以找到:
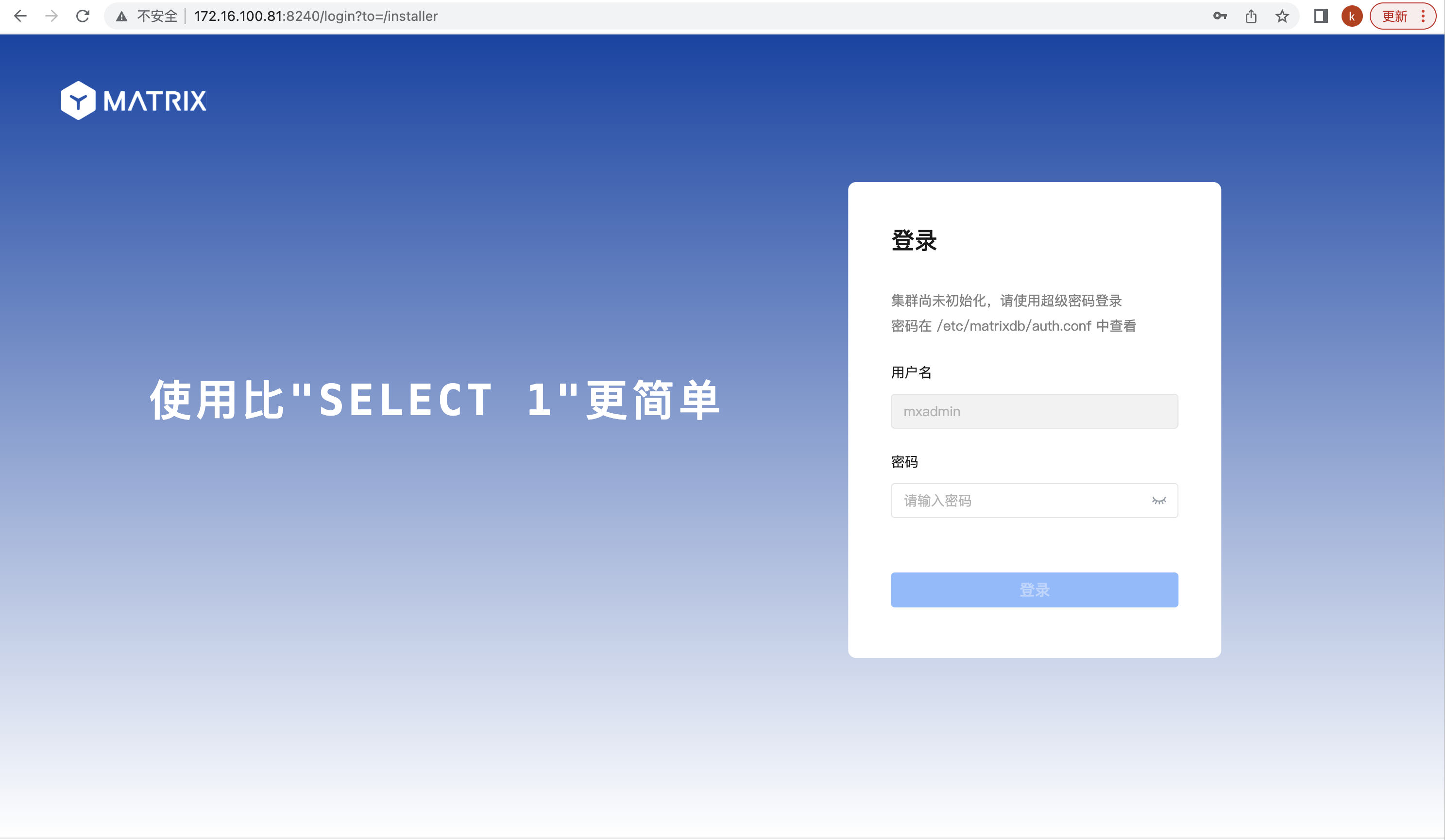
第二个页面选择“添加多个节点并初始化数据库集群”,然后点击下一步:
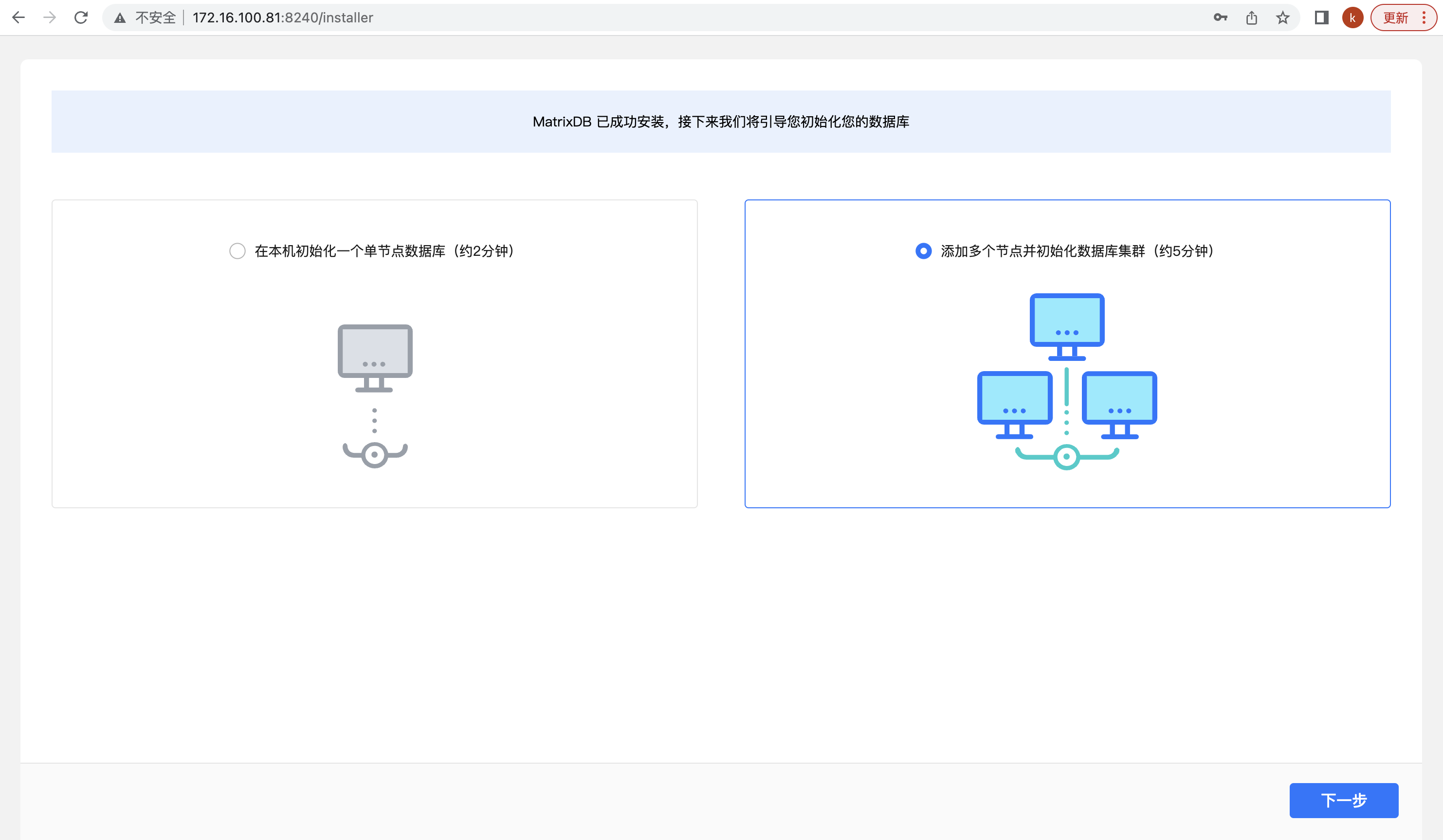
接下来开始多机部署的五步操作。
第一步,添加节点,在右上文本框里输入节点的 IP 地址、主机名或 FQDN 并点击“添加节点”:
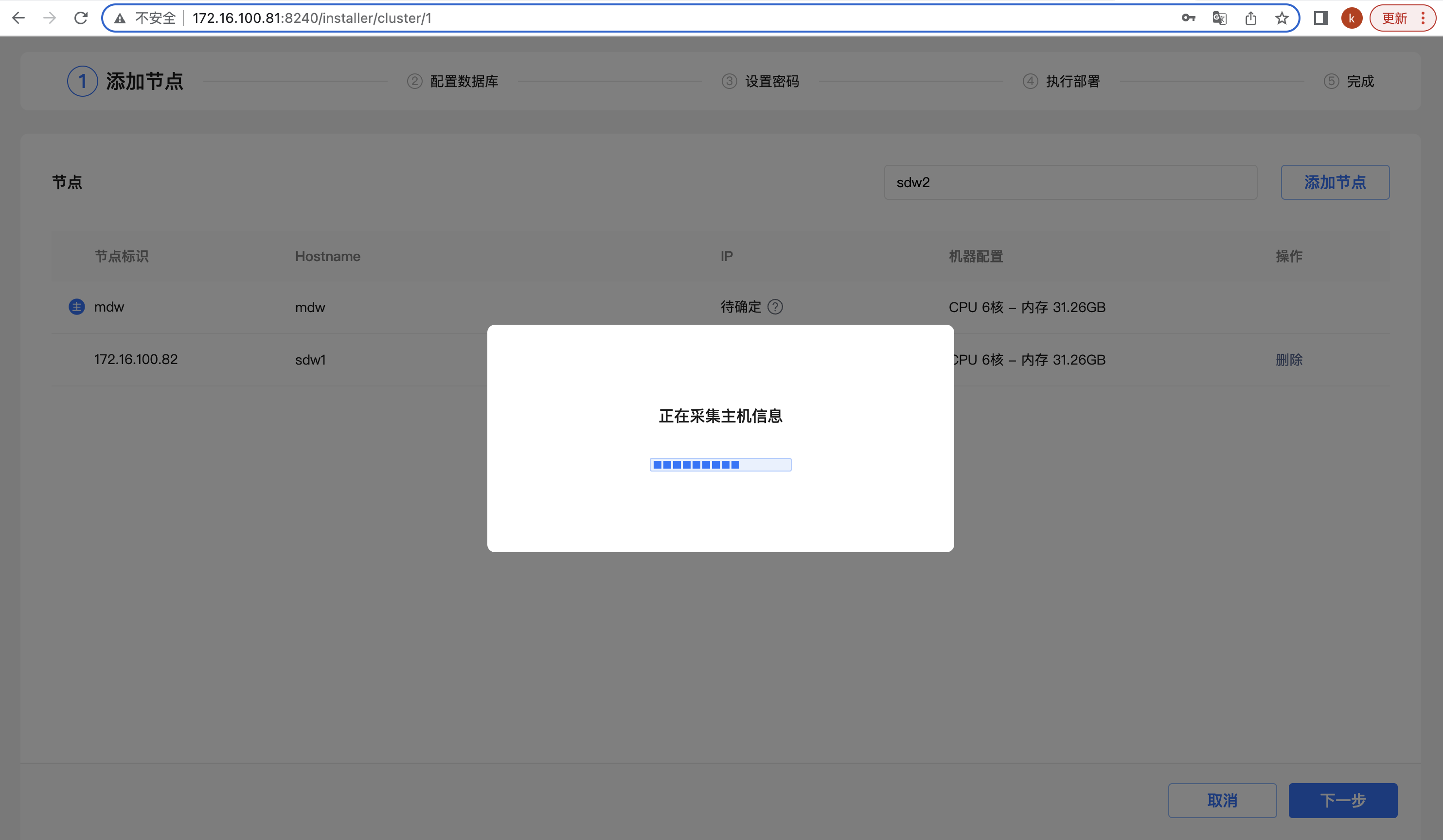
添加完 sdw1 和 sdw2 之后,点击“下一步”
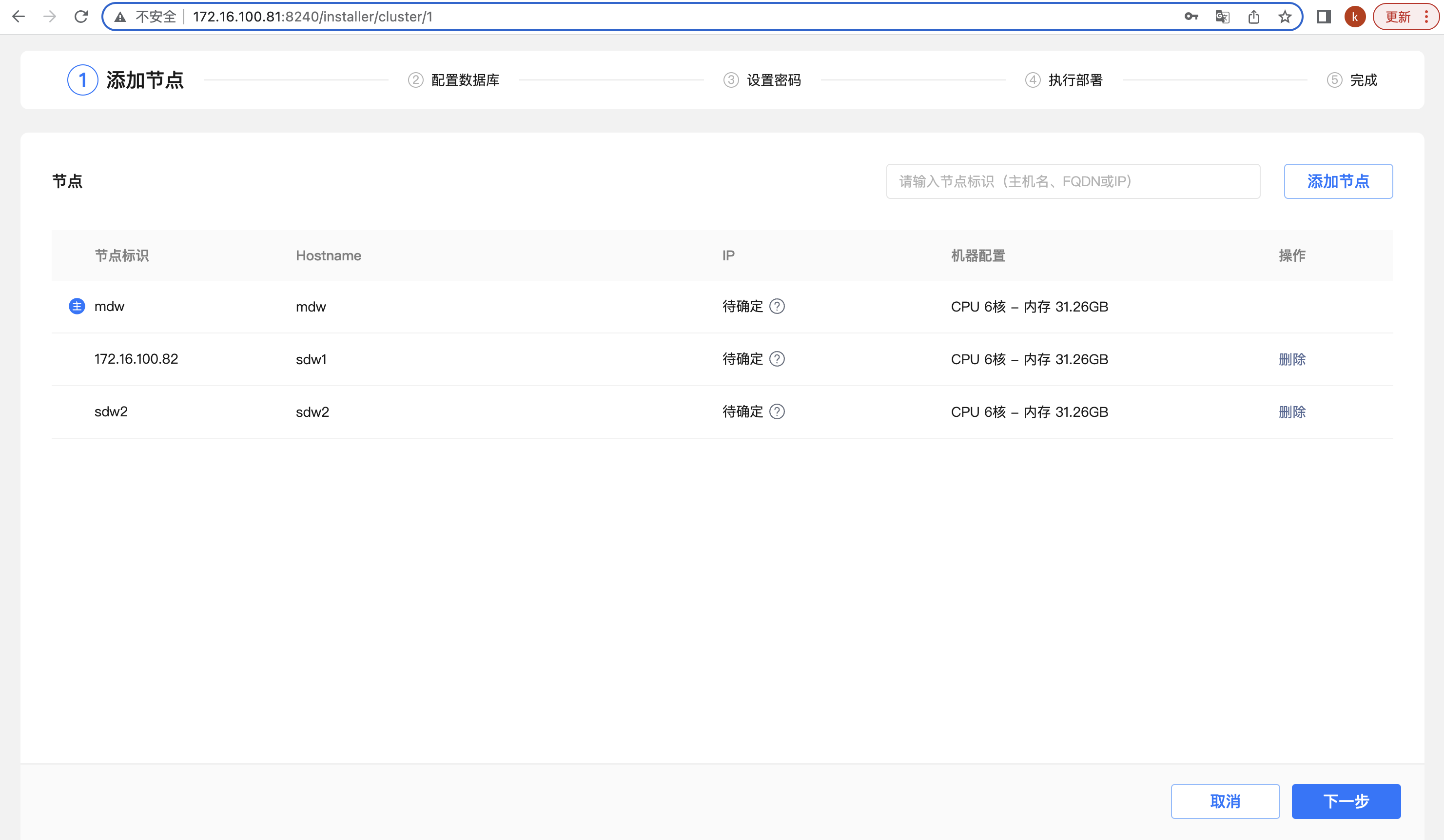
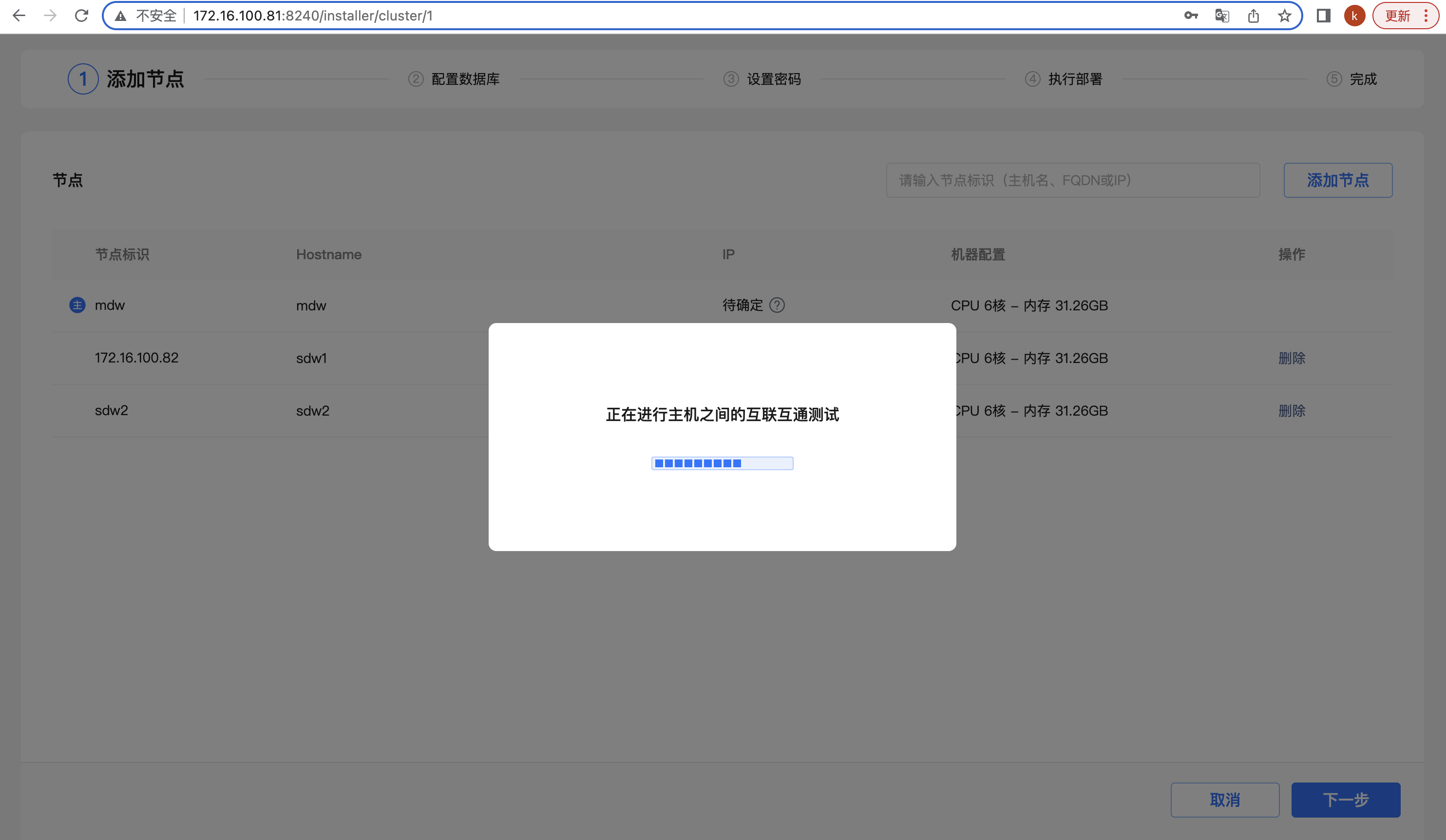
这个时候会进行主机之间的互联互通测试,保证主机之间的网络是联通的。
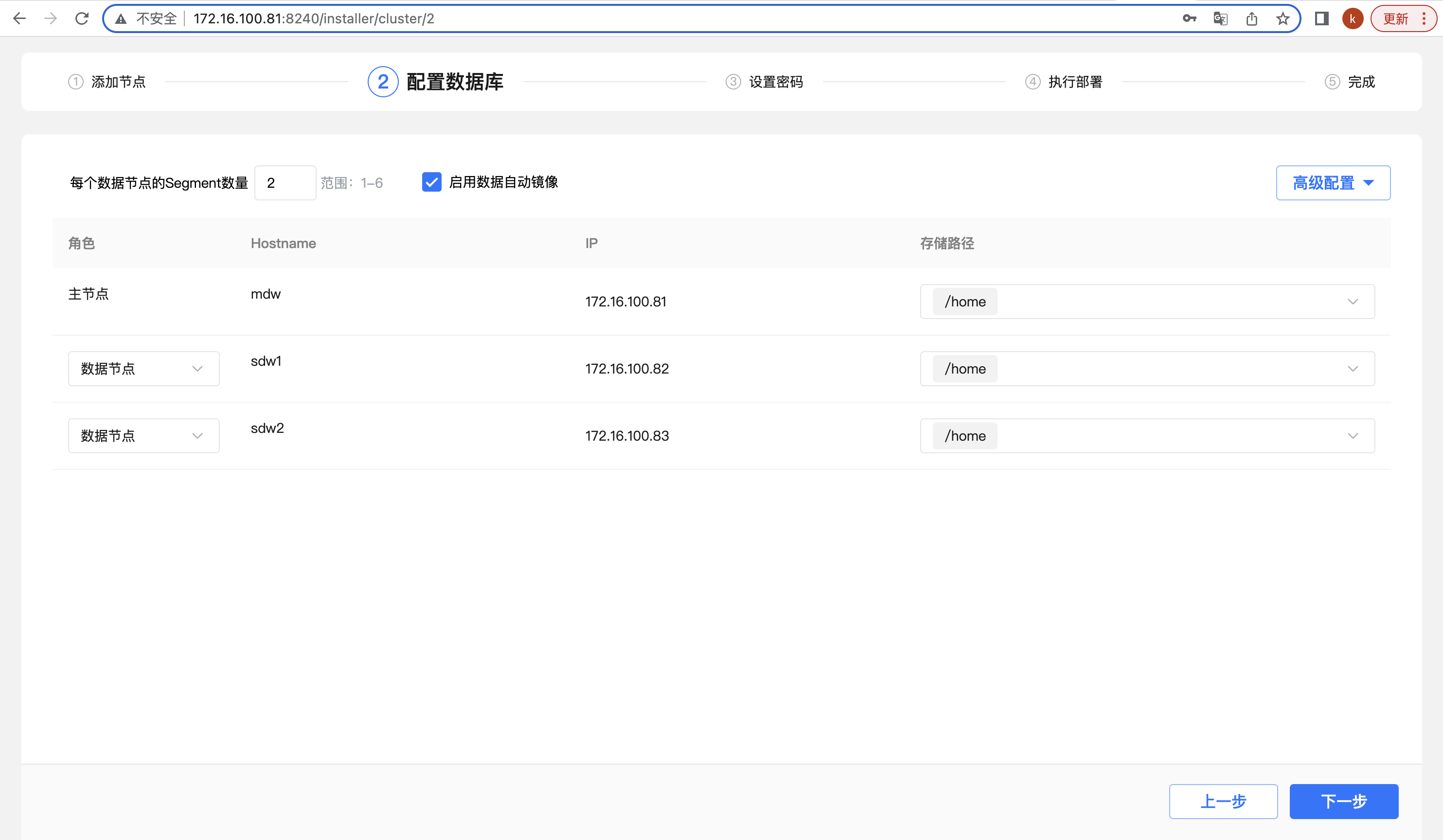
第二步,配置数据库,选择数据库目录存储路径和 segment 数量。系统自动推荐空间最大的磁盘和与系统资源相匹配的 segment 数目,可根据具体使用场景调整。“启用数据自动镜像”决定了集群数据节点是否包含备份镜像,在生产环境中建议勾选,这样集群才是高可用的。确认后点击“下一步”:
第三步,设置密码。MatrixDB 会建立 mxadmin 数据库管理员账户,并作为超级账户。在这个环节设置 mxadmin 账户的密码,然后点击“下一步”(此处设置的是数据库账户的密码,而非操作系统账户的密码)。另外,还有一个选项是“允许远程连接至数据库”,默认勾选:

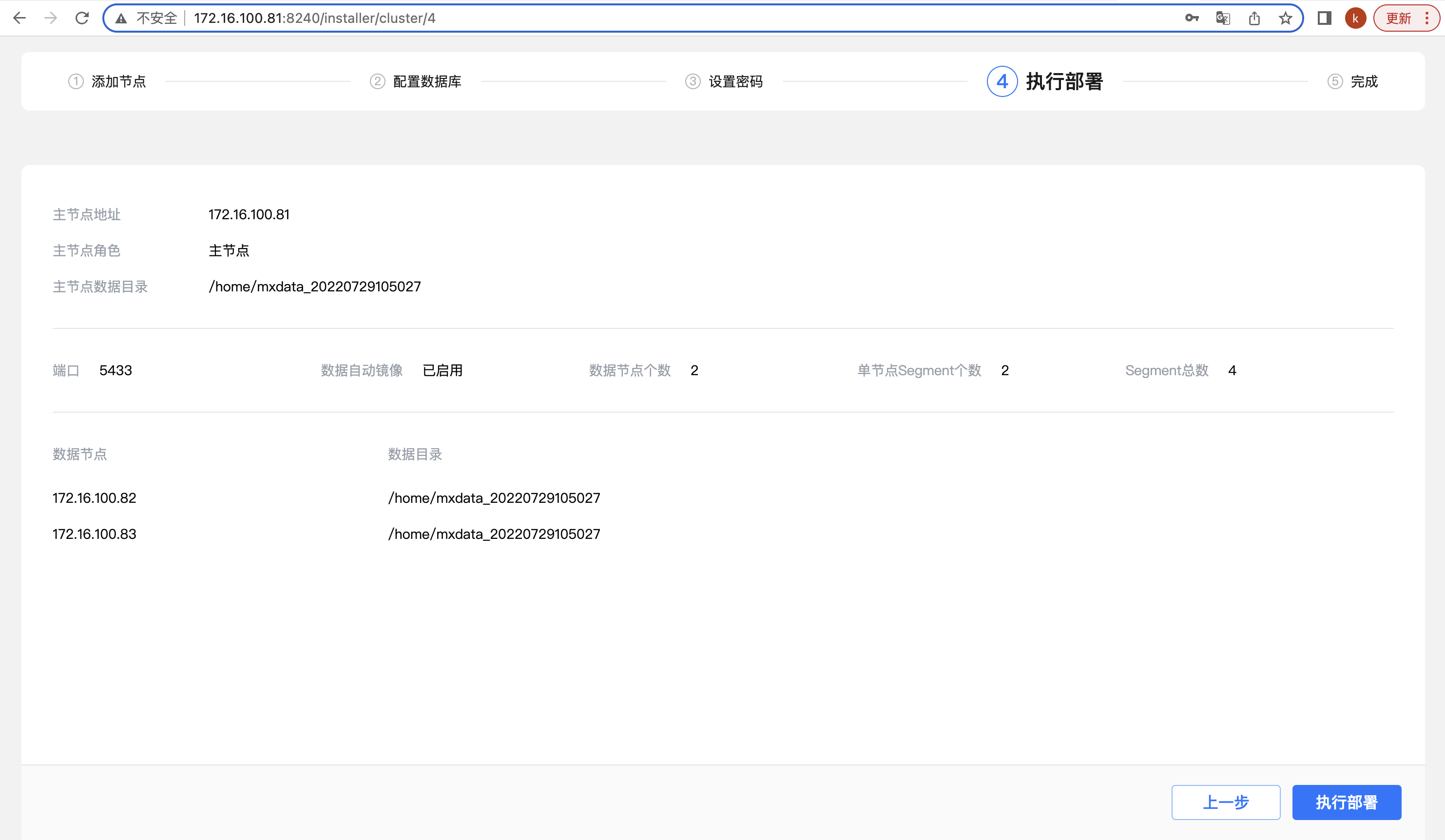
第四步,确认部署。该步骤会列出来之前的操作的完成配置参数,确认无误后,点击“执行部署”:
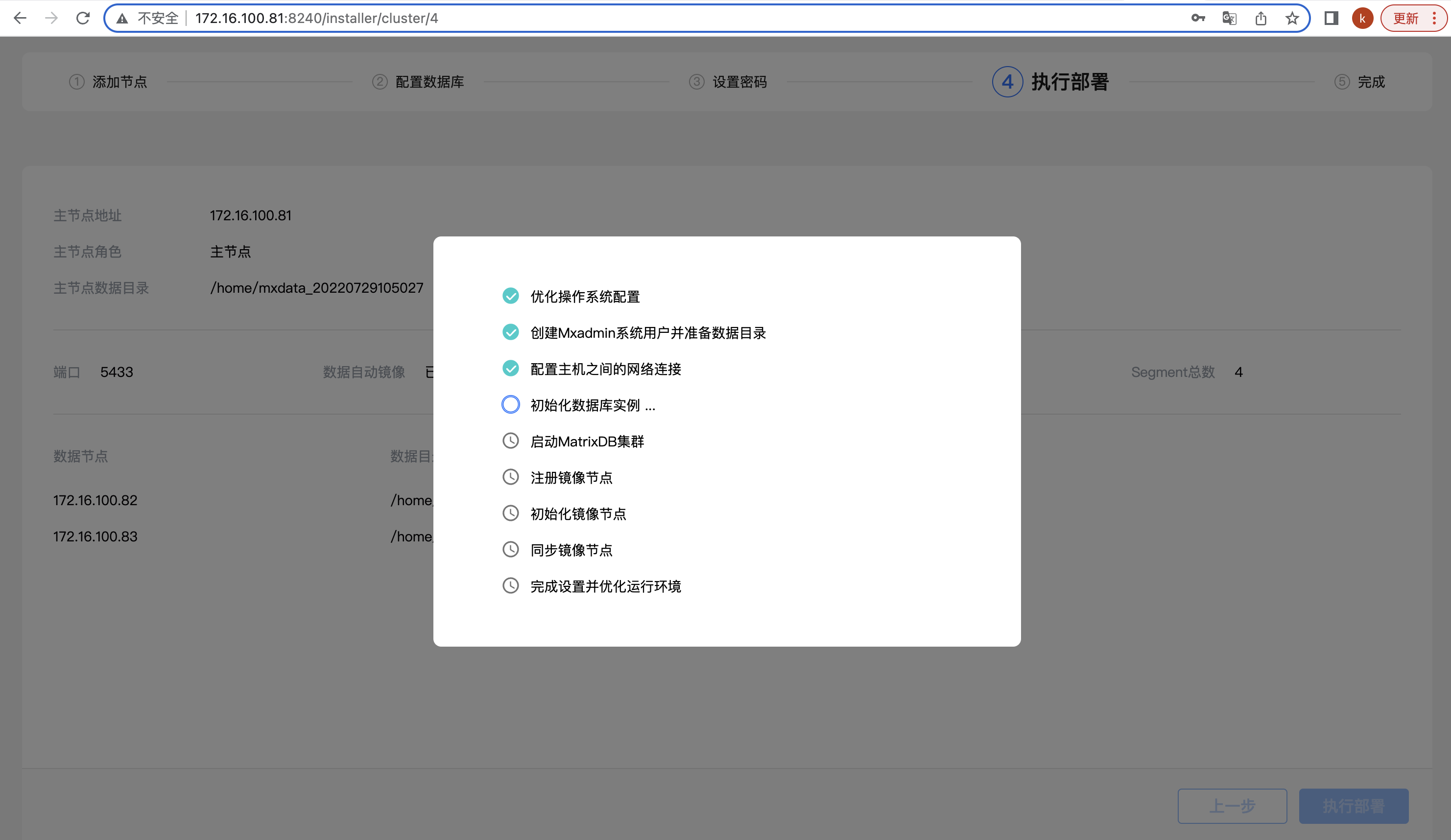
然后,系统会自动进行集群部署,并列出详细步骤和执行进度。所有的步骤都成功执行后,表示部署完毕:
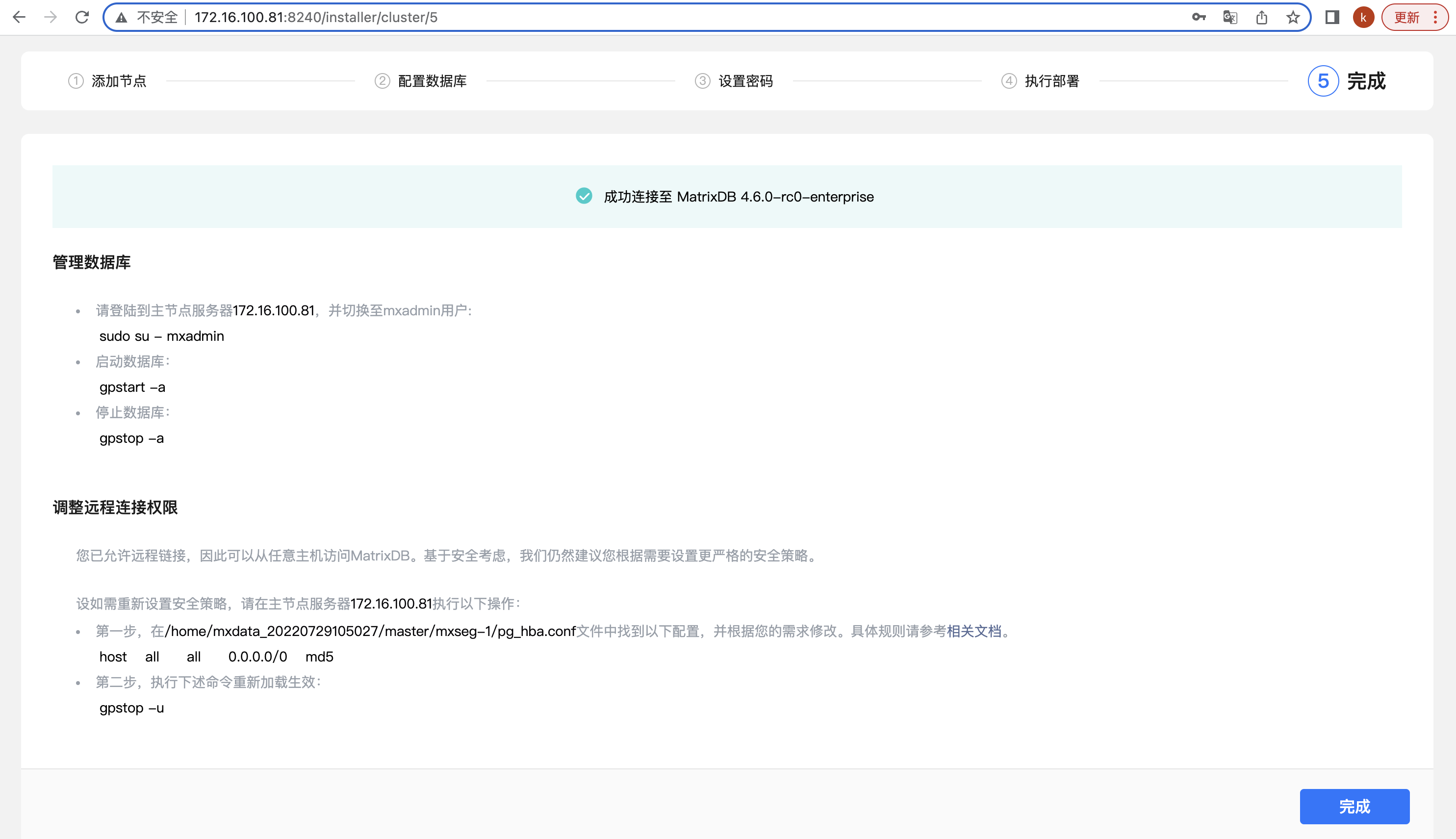
这时,可以看到管理数据库的基本方法和如何设置允许远程连接。为了确认数据库集群成功部署并可以访问,可以点击“测试连接”:
当看到成功连接的提示,说明集群已经可以正常接收用户的请求:
MatrixDB 缺省安装支持远程连接,如果在安装过程中没有勾选“允许远程连接至数据库”,请手工修改 $MASTER_DATA_DIRECTORY/pg_hba.conf 文件添加类似这样一行,表示允许来自任何 IP 的访问所有数据库的用户通过密码认证连接,可以根据实际需要限定 IP 范围或者数据库名称以减少安全风险:
host all all 0.0.0.0/0 md5完成这些修改后,需要执行下述命令让数据库重新加载 pg_hba.conf 配置文件:
gpstop -uMatrixDB 的启动、停止、重启、状态查看可以通过下述命令分别完成:
gpstart -a
gpstop -af
gpstop -arf
gpstate| 命令 | 用途 |
|---|---|
| gpstop -a | 停止集群。(此模式下,如果有会话链接,关闭数据库会卡住) |
| gpstop -af | 快速关闭集群 |
| gpstop -ar | 重启集群。等待当前正在执行的 SQL 语句结束(此模式下,如果有会话链接,关闭数据库会卡住) |
| gpstate -s | 查看集群状态 |



