

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
YMatrix 是一款高可用的分布式数据库系统,支持在节点宕机后进行故障恢复。高可用的前提是冗余部署,所以主节点(Master)需要有备用节点(Standby)作为备份;对于数据节点(Segment),Primary 为主节点,需要有与其对应的镜像节点(Mirror)。
一个高可用系统的部署图如下所示:
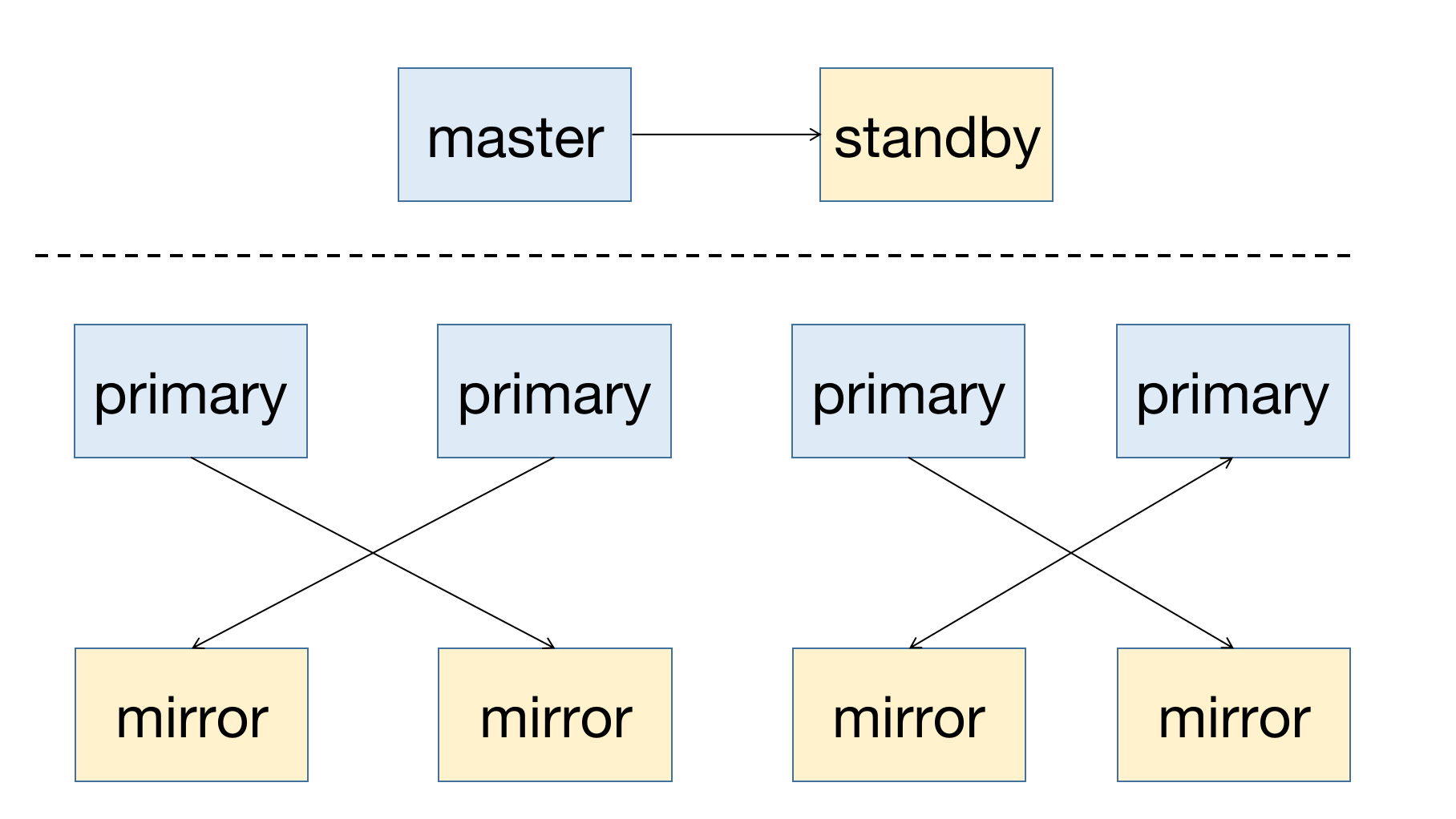
当集群中节点出现故障,你可以通过查看图形化界面(MatrixUI)来获取节点状态信息。示例集群 Master 为 mdw,Standby 为 smdw,Segment 为 sdw 1 与 sdw 2,二者各有一个 Mirror。
部署情况:
如上部署方式,目的就是避免单主机故障导致系统不可用,同时分散集群压力。
下文将简单讲述 YMatrix 集群的自动运维原理及不同作用节点的宕机场景解决。
YMatrix 支持集群状态服务(Cluster Service),用以运维自动化。此服务主要包含故障自动转移(Failover)及以 mxrecover 工具为支撑的故障自动恢复(Failback)两个功能。利用这两个功能,可以实现节点故障的完整恢复流程。
故障自动转移指自动运维体系中,通过调取 etcd 集群的节点状态诊断信息,切换主备节点从而转移故障的机制。etcd 集群是 YMatrix 集群状态服务中的核心组件,负责管理所有节点的状态信息。当集群中任一节点出现故障时,数据库系统会自动进行节点故障转移,无需人工干预。
故障自动转移完成后,相应节点对仅存 Primary / Master,没有健康的备用节点。如果再出现故障,则无法恢复。所以,需要使用 mxrecover 工具为新的 Primary / Master 生成健康的 Mirror / Standby 节点。
mxrecover 工具有如下作用:
注意!
mxrecover 工具的详细使用方法请见 mxrecover。
当系统发现 Mirror / Standby 宕机,图形化界面的节点状态会变为 down。
注意!
Mirror 宕机并不会导致集群不可用,因此系统不会重新激活 Mirror。
激活 Mirror 需要使用mxrecover工具,详见下文。
此时,如果距离宕机时间间隔较短,且宕机节点数据量规模不算很大,建议你先尝试增量恢复。当 mxrecover 命令后没有参数或者只有 -c 时,即使用增量恢复模式。如果增量恢复失败,则需要通过复制全量数据激活宕机节点,即使用 mxrecover -F 命令。
当系统发现 Primary 宕机,则会自动提升对应的 Mirror 为 Primary。
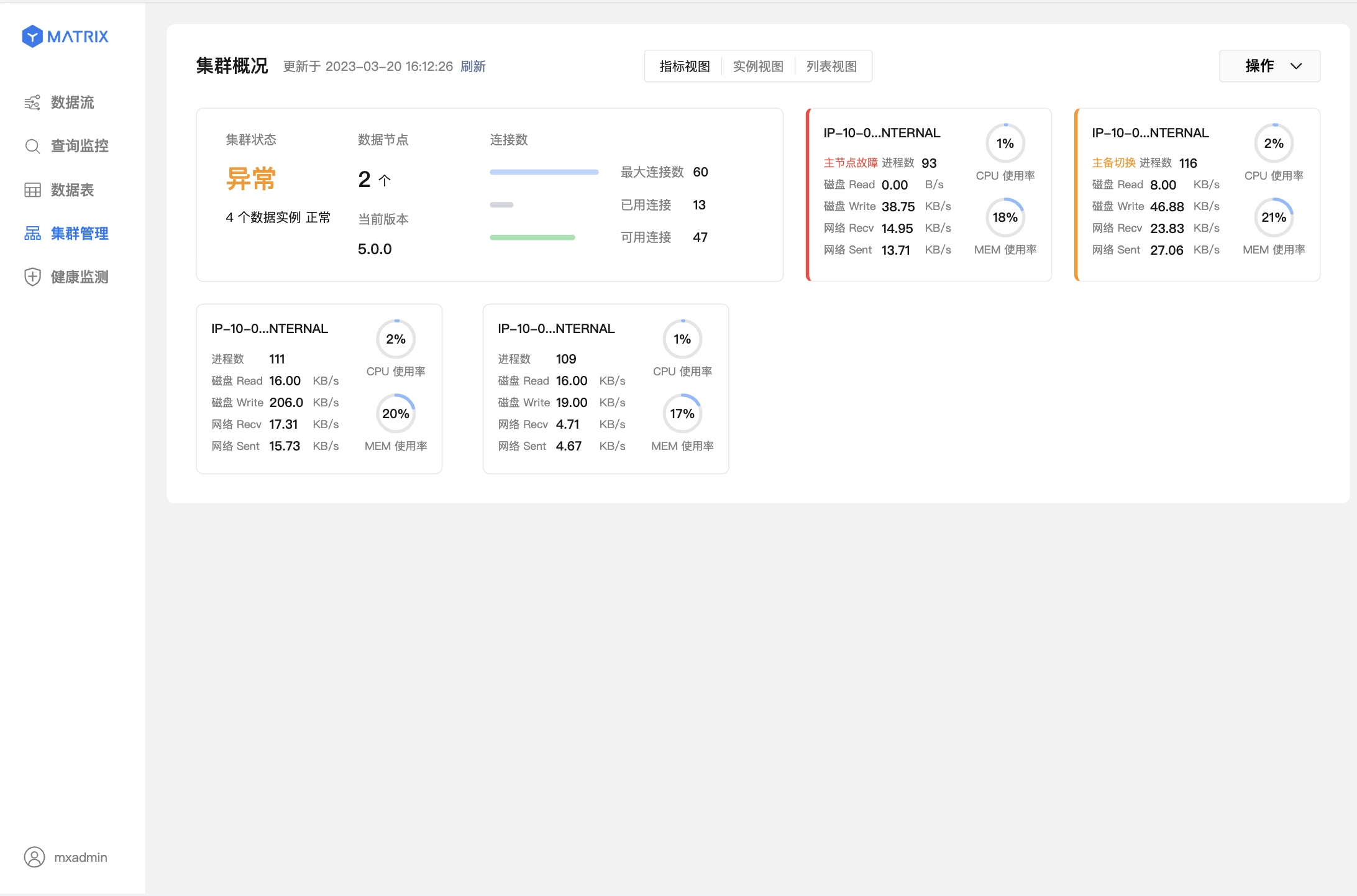
下图表示主节点(Master)故障,已完成主备切换。方框左侧红色表示此节点故障,黄色表示此节点已完成故障转移。
下面两个图则表示数据节点(Segment)故障,已完成主从切换。
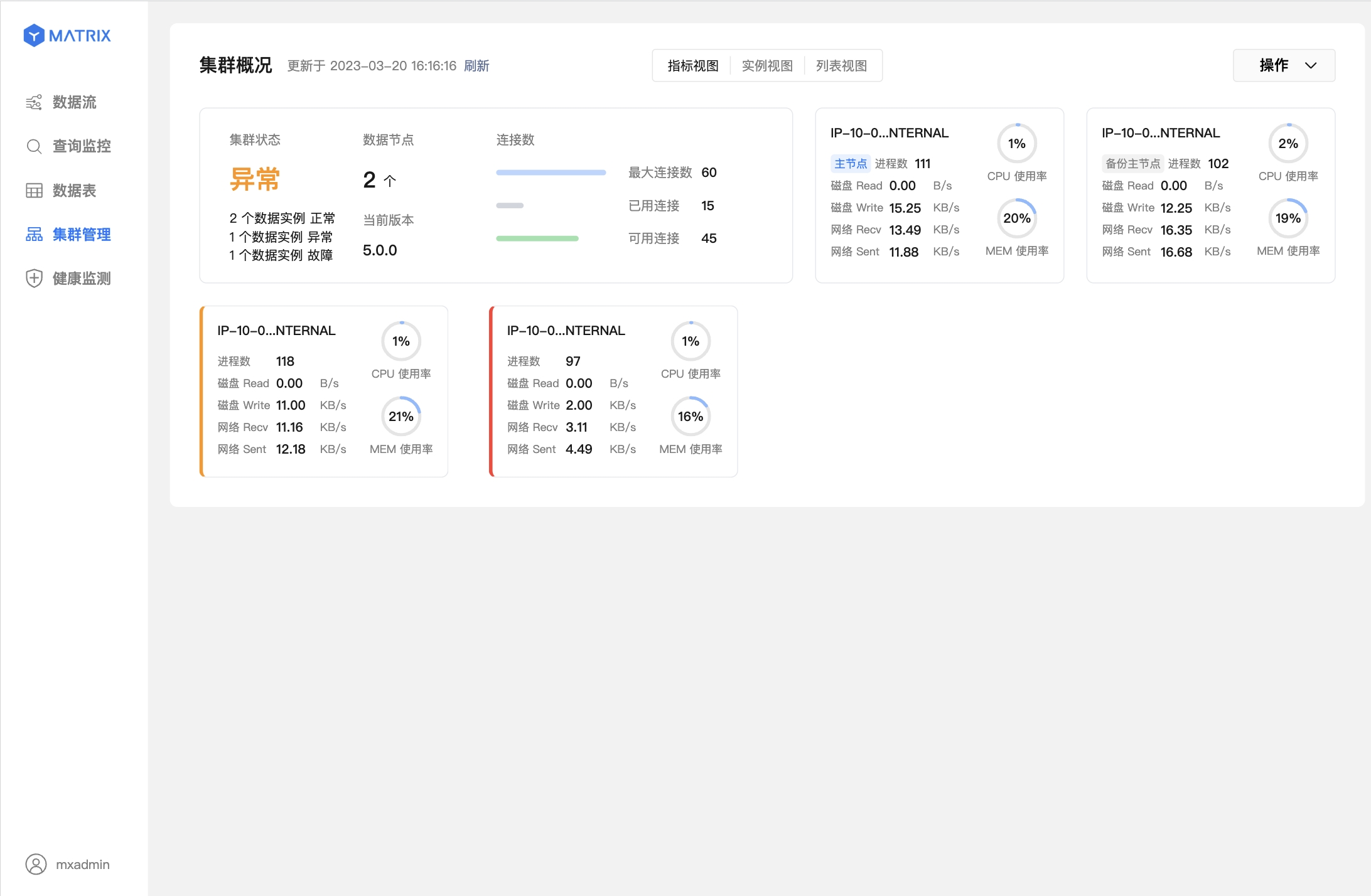
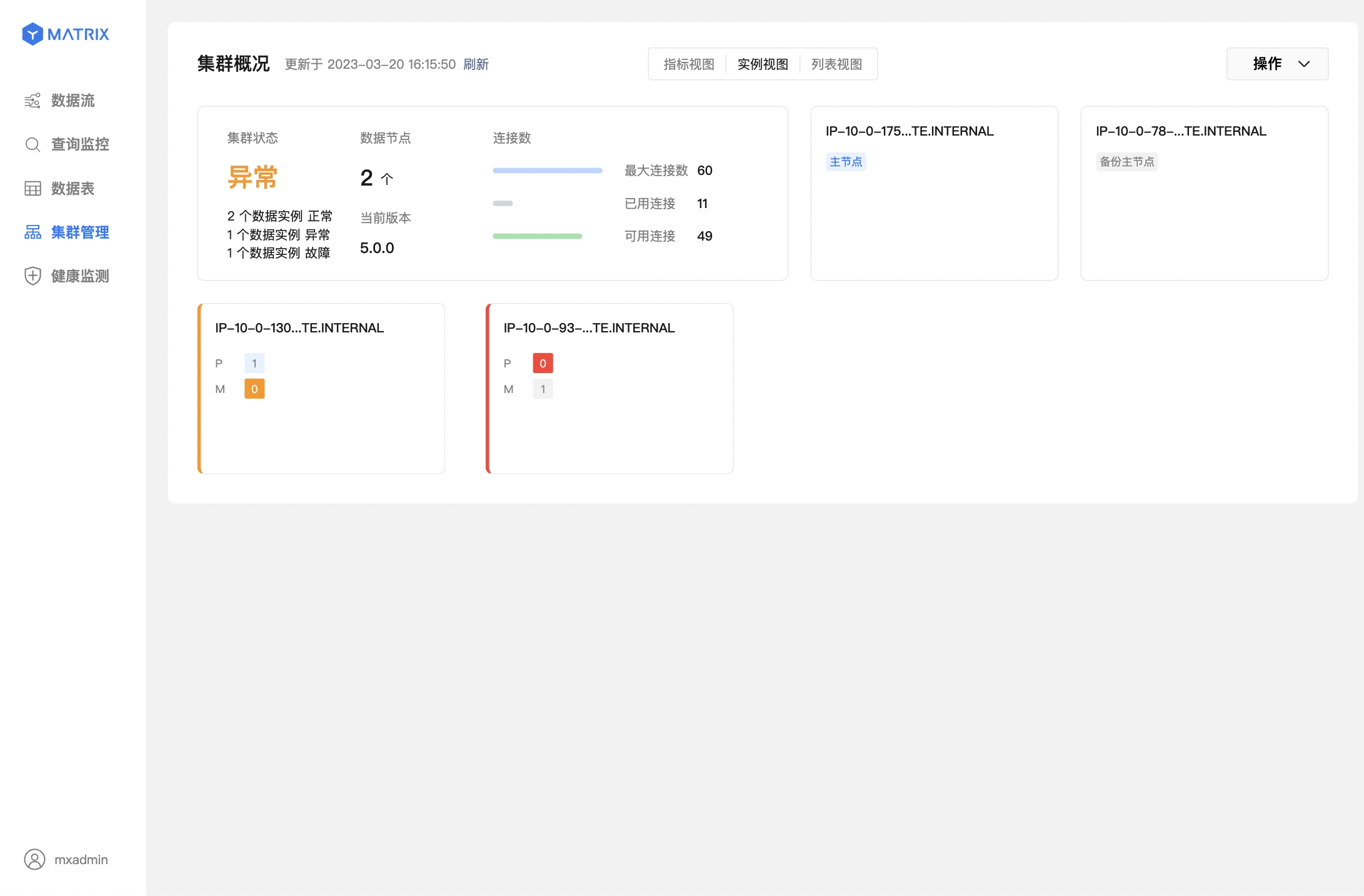
在系统自动完成 Mirror / Standby 的提升后,执行 mxrecover 可以为新的 Primary / Master 生成对应的 Mirror / Standby,并全量或增量同步节点数据以恢复宕机节点。 直接执行 mxrecover,即可激活宕机 Mirror / Standby,增量恢复数据。如上文所述,如需全量恢复,则需要使用 mxrecover -F 命令强制执行。
[mxadmin@mdw ~]$ mxrecover虽然 mxrecover 为新的 Primary 节点重新生成了 Mirror,但是也带来了一个新问题,Primary 节点分布关系发生了变化,两个 Primary 节点都分布在了 sdw2 上。这样会导致主机资源分配不均匀,sdw2 也会承载更多的负载。
重分布命令如下:
[mxadmin@mdw ~]$ mxrecover -r当执行了 mxrecover -r 后,再进入图形化界面的集群管理页面进行检查即可。
Master 的故障自动转移会基于以下两种情况发生:
下文会分别阐述这两种情况下 Master 故障自动转移对不同组件的影响及建议操作。
此情况说明 Master 宕机后发生故障自动转移,切换到了 Standby 来管理集群。
此时,用户应根据提示访问 Standby 节点上的图形化界面,默认地址为 http://<standbyIP>:8240。
可以用 mxadmin 的数据库密码,或 Standby 节点上的 /etc/matrixdb6/auth.conf 超级密码正常登陆:

登陆后一切功能均可正常使用。
此情况说明集群已经不可用。此时仍可以通过 Master 登录图形化界面查看集群状态,但需要查询数据库的功能会被限制。
注意!
如果你的集群安装时未配置 Standby 但曾经通过 mxinitstandby 工具追加过 Standby,则与初始就配置了 Standby 的情况无异。
注意!
建议在严肃生产环境里一定要配置 Standby。
此情况说明 Master 宕机后发生故障自动转移,切换到了 Standby 来管理集群。
这里有的影响有以下两种:
此情况下 MatrixGate 应在 Master 主机上,且 Master 主机宕机已经造成集群不可用。
这种场景下,MatrixGate 进程因为在离线的主机上,可以认为已经随主机消亡,或者与其他节点网络隔离。
此时,MatrixGate 会自动切换为向 Standby 插入数据,监控数据会继续正常入库,无需人工介入。
如果需要查看 Grafana 监控页面,此时需要手动修改数据源,指向 Standby 的地址。
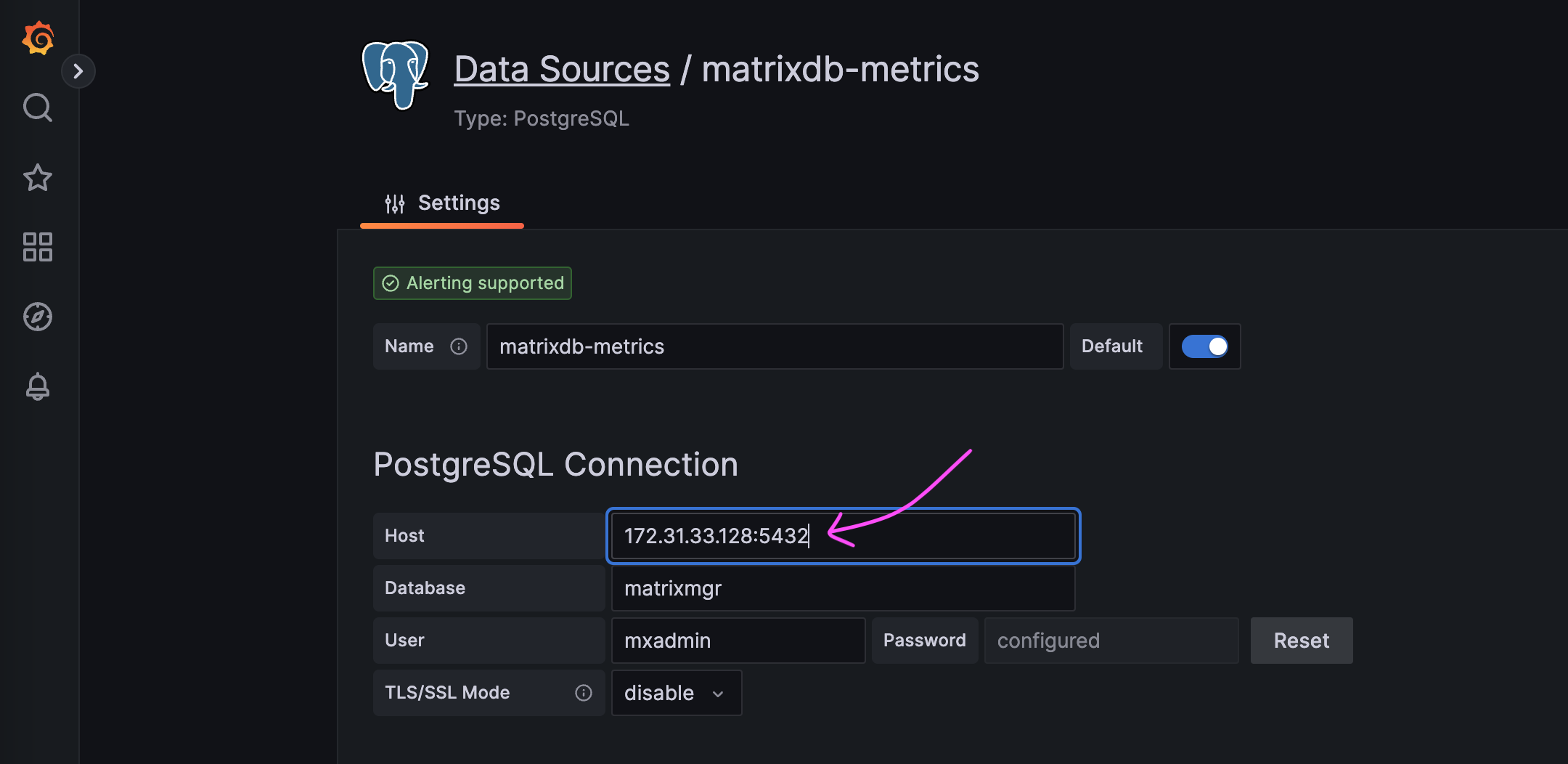
这种情况下,因为监控部署的 MatrixGate 服务已消亡,因此不会再产生新的监控数据。



