

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
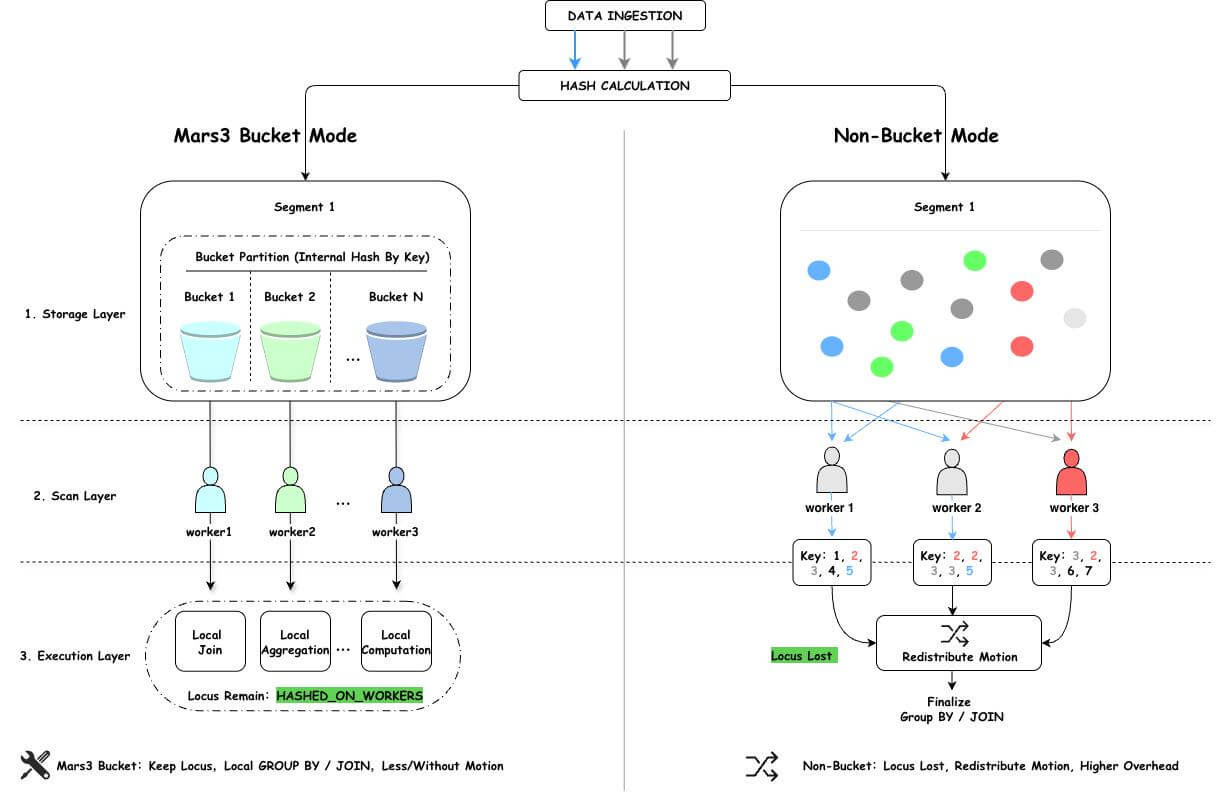
MARS3 Bucket 是 YMatrix 数据库针对 MPP 架构中并行扫描场景设计的存储层并行执行优化机制 ,通过在数据落盘阶段就按分布键哈希组织为多个逻辑桶,确保并行扫描时相同分布键的数据由同一工作进程处理,从而保留数据分布语义(locus),避免不必要的数据重分布(Motion),实现从"扫得更快"到"算得更本地"的性能跃迁。
Bucket 主要适用于有并行扫描需求的大表,尤其是 Hash 分布表上基于分布键进行聚合或关联、并且希望减少不必要 Motion 的场景。对于小表、临时表、很少并行扫描的表,开启 Bucket 通常收益有限,还会增加文件、元数据和后台治理成本。
配置 nbuckets 时,建议遵循以下原则:
nbuckets 的最大值不超过单机 CPU 核数与单机 Segment 个数的比值。rowstore_size 和单表数据量评估,避免单个 bucket 小于 2 MB。nbuckets。后续修改 nbuckets 会导致全表重写,不建议作为常规调优手段。nbuckets 也不会生效。MARS3 Bucket 的目标是:让并行扫描之后,数据仍然保持良好的本地性,让更多计算继续在本地完成。
MARS3 Bucket 在传统分布中“先决定数据落到哪个数据节点”的基础上,进一步决定了数据在数据节点内做更有组织的 Bucket 划分,使得可以确保同一个 Bucket 的数据由一个 worker 输出。
MARS3 bucket 方案与普通 page 抢占式并行扫描的本质区别:segment 内部的并行处理也变得有组织,并行扫描不再只是更多 worker 一起读数据这么简单,而是变成了按分布语义协同读数据。
例如,假设有一张 t_sales 表,分布键是 c1。现有如下 SQL:select c1,count(*) from t_sales group by c1;
Gather Motion 12:1
-> Finalize HashAggregate
Group Key: c1
-> Redistribute Motion 12:12
Hash Key: c1
-> Partial HashAggregate
Group Key: c1
-> Parallel Seq Scan on t_sales第一步是并行顺序扫描(Parallel Seq Scan)。每个 segment 会启动多个 worker 并行读取数据,但 worker 是随机争抢页面来扫描的,从输出结果来看,无法保证同一个 c1 的数据只由一个 worker 处理。
第二步是局部哈希聚合(Partial HashAggregate),每个 worker 只对自己读到的数据做一次初步聚合。
第三步需要按 c1 重分布(Redistribute Motion)。因为经过局部聚合后,同一个 c1 仍可能分散在多个 worker 上,必须重新按 c1 分发数据,才能保证最终聚合结果正确。
简单来说:问题不是表本身的分布方式不对,而是并行扫描破坏了原本可以直接用于聚合的数据分布规则。为了修正这个问题,优化器只能额外增加一次数据重分布,这也直接削弱了并行执行本该带来的性能提升。
Gather Motion 12:1
-> HashAggregate
Group Key: c1
-> Parallel Custom Scan (MxVScan) 首先,数据落盘时先做 hash,再按照桶号 (bucket) 进一步组织;然后,扫描时每个 worker 只扫描一个或多个 bucket,这样扫描输出就可以继续保持哈希分布特性,知晓分布语义。则执行计划无需显式添加 Motion,这样就能够大幅度地提升 SQL 执行效率。
在 YMatrix 数据库中,数据是按照一定规则分散存储在各个数据节点 (segment) 上的,所有数据节点上的数据共同构成完整的数据集。每张表在定义时都需要指定分布键,数据在写入时根据分布键计算哈希值,然后将哈希结果映射到某个数据节点。因此,当表具有相同的分布键时,相同数据可以确保存储在同一个数据节点上,因此基于分布键的关联、聚集等操作将会以最⾼效的⽅式将绝⼤部分⼯作在节点本地完成,不需要数据移动,这种现象我们将其称为数据共生 (co-locality)。
首先,从整个表的数据的角度看,YMatrix 是 MPP 架构,每个 Segment 上都有进程扫描,这一层并行指的是整个实例范围内的并行。
其次,从某一个特定 Segment 中的表数据角度看,某一个特定 Segment 中的数据可以有多个进程同时参与扫描,这一层并行指的是所以有节点内并行。



