

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
Unique Mode 是 MARS3 为特定写入模型提供的一种模式:把“更新某条记录”的需求,转换为“按唯一键再次插入一条新记录”,由引擎自动完成同一键值下的新旧版本替换。它的核心价值是让业务在高频写入场景中,用更简单、更统一的写入方式 (INSERT) 表达更新语义,减少显式 UPDATE 的使用与代价,并保持数据组织在持续写入下更可控。
适用场景:
在 Unique Mode 下,唯一键由建表时的排序键 ORDER BY (...) 定义:当你插入一条与已有记录 相同 Unique Key 的新数据时,引擎会将其视为对该键对应数据的更新,无需显式执行 UPDATE,直接 INSERT 即可完成更新语义。
与传统的 upsert (insert .. on conflict) 不同,Unique Mode 是读时合并,数据在写入的时候依旧会写入到存储中,读取的时候通过一定的版本链和可见性规则确保读取的是最新的数据,并通过 compact 移除重复数据;upsert 则是写时合并,在写入时,即检查是否可能会重复,有额外的写入开销。
因此,Unique Mode 的写入效率会远高于传统 upsert 的方式,根据测试表明,Unique Mode 的性能大约是传统 upsert 的 1.5 倍。
在 Unique Mode 的同键再次写入场景中,标量列采用新值覆盖旧值的默认行为;但当某列为 JSONB 类型时,引擎支持增量合并语义:新版本的 JSONB 值不是直接写入,而是按以下规则得到:new_jsonb = jsonb_concat(old_jsonb, incoming_jsonb),数据库内部会直接调用 jsonb_concat 实现合并,比如:
postgres=# SELECT jsonb_concat('[1,2]'::jsonb, '[2,3]'::jsonb);
jsonb_concat
--------------
[1, 2, 2, 3]
(1 row)
postgres=# SELECT jsonb_concat('{"k":1,"x":2}'::jsonb, '{"k":null}'::jsonb);
jsonb_concat
---------------------
{"k": null, "x": 2}
(1 row)
postgres=# SELECT jsonb_concat('{"a":1,"b":2}'::jsonb, '{"b":99,"c":3}'::jsonb);
jsonb_concat
---------------------------
{"a": 1, "b": 99, "c": 3}
(1 row) 这样当业务使用 JSONB 承载动态属性/扩展字段/标签等信息时,可以只写入增量 JSONB,由引擎完成合并,避免应用层读旧值合并然后写回的额外复杂度与并发冲突。
为什么要做 UpdateChain:解决并发更新同一行时的正确性。对于 PG Heap 的更新不是原地改一行,而是旧 tuple 标记删除 + 插入新 tuple,并用 ctid 把旧版本指向新版本,形成一条 update chain。
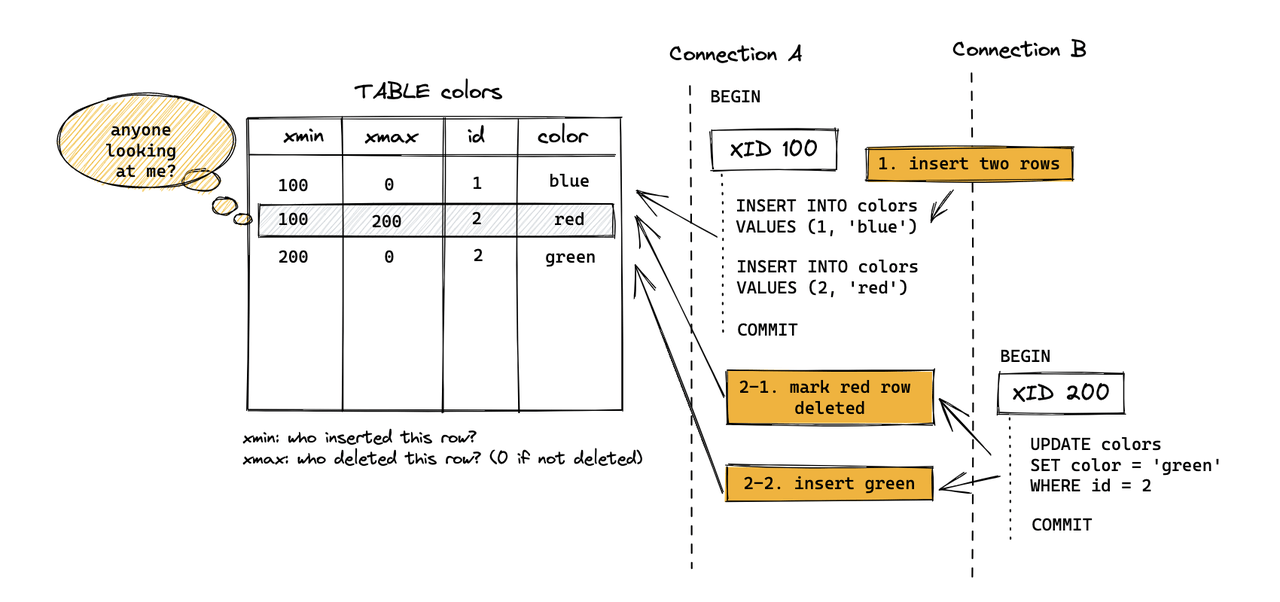
而对于 MARS3,MARS3 的删除/更新不是像 Heap 那样把 xmax 写在 tuple header,而是把类似的“删除/更新标记”写到 Delta 文件;同时为了保证 compaction/flush 后这些信息不丢,还需要 Link 文件。Heap 的 xmax/删除信息在 MARS3 里存 Delta,Link 确保 compaction 过程中 delete 信息不丢失。
因此,
早期 MARS3 在同一行并发更新场景下会直接报错退出,没有 UpdateChain 的支持,无法确保结果的并发正确性;引入 UpdateChain 后,通过 TupleLock 对逻辑行加锁,并沿 update-chain 定位最新版本,使并发更新按顺序推进,从而保证 Update 语义正确性。
和 PostgreSQL 类似,在 YMatrix 中,更新和删除操作并不是对原有的数据空间进行操作,而是通过对元组的多版本形式来实现的:
更新和删除过程中产生的死元组 (invisible runs) 会由后台进程 autovacuum 定时清理,也可以手动执行 vacuum 进行清理,另外在 compact 的过程中,随着小的 Run 合并为一个新的更大的 Run,invisible runs 也会被清理掉。vacuum full 则更进一步,它会将多个小的 Run 合并成一个大的 Run。如果没有新的写入操作发生,运行一次 vacuum full 通常会尽可能地合并这些批次,直到无法再进行合并为止。最终,剩余的每个批次的大小将约等于 max_runsize 的设定值 (注意,vacuum full 的过程中也可能会产生 invisible runs)。
简而言之:
返回上一章节:存储引擎原理



