
随着我国汽车工业逐渐完善,国内汽车市场愈发庞大,但车险利润却不增反降。据相关报告的数据,2023 年二季度当期国内车险行业承保利润为 37.00 亿元,环比一季度减少 12.09 亿元,降幅为 9.49%,车险行业整体承保利润快速下降,并有恶化趋势。
因此,车险平台需要改变过去的运营模式,充分挖掘数据价值,将数字化能力融入到市场运营当中。本文将重点从“时序数据高并发入库、海量数据高性能分析、库内机器学习”这三个方面,为大家分享国际领先的某保险公司依托 YMatrix 超融合数据库,围绕某汽车品牌旗下的海量车辆行驶数据,构建车险个性化定价及通用驾驶习惯分析平台的经验与实践。
当前,国内车险市场有 8000 亿的规模,且处于高度分散化的状态,其中一半以上都是由各地的几千家中小代理公司混战。国内的经代公司是通过传统的金字塔模式去运作和销售的,市面上几千个中小金字塔就构成了现有的传统保险市场。而这种相对低效的车险业务运营模式,无疑带来了一些问题:
归根结底,车险面向的用户并非汽车,而是司机。且每位司机的驾驶习惯不同,在车险这一相对特殊且垂直的保险市场中,即使是同一品牌、型号的汽车,往往会因为驾驶人的驾驶习惯、路况等客观因素,而导致不同车辆的损耗以及面临的风险程度不一。
而当前的标准化的车险定价,又决定了其只能通过扩大销售面积来保持增长,但这种形式无法让车主感受到差异化与性价比,只能通过价格方面来选择,自然难以实现增长;但如果实行定制化服务,对于车主,缺乏标准化的定价又会使得投保人心生怀疑。这种定价策略的不透明性和不确定性,一方面阻碍了保险公司与用户之间的信任,另一方面也让保险公司难以为客户提供更具性价的个性化服务,在一定程度上阻碍了保险公司与用户之间的正常沟通。
基于来自业务和用户侧的痛点,车险业务需要向精细化运营的方向转型。车险业务数字化的核心是对车联网终端设备带来的数据做加工处理,识别出风险特征,梳理排查风险做量化分析,并对风险较高的个体予以风险减量管理,将有限资源用到有效的地方,实现精细化管理。而这些都需要数据库本身的性能来进行支撑。因此,需要数据库具备以下四条特征:
以某汽车品牌服务为例,该汽车品牌旗下共有 30 多种车型,其中大部分是小型货车,截止今年已销售 1000 万辆车,其中最新产的车上都装备有 SIM 卡,每 30s 上报一次密文数据。此前,该汽车品牌的数据流程如下图所示:
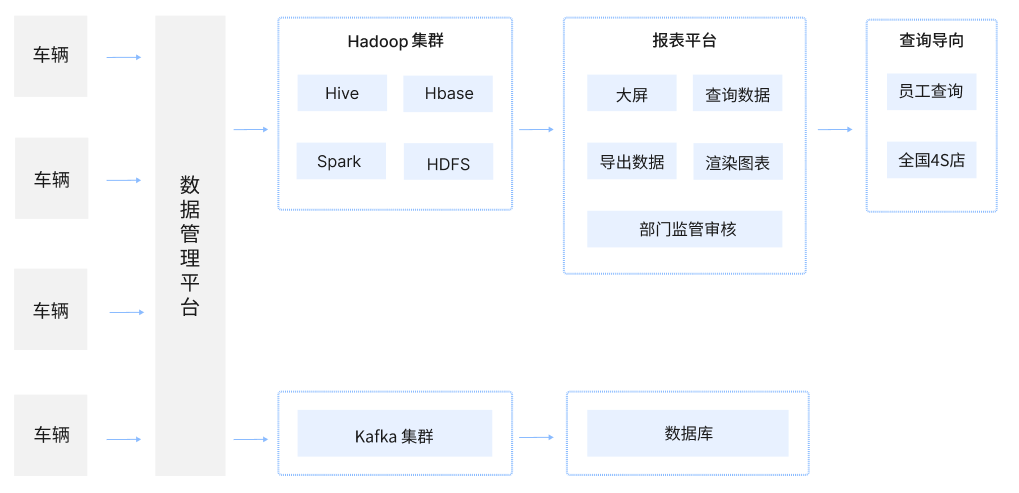 某车企数据收集流程
某车企数据收集流程
但这样只是对数据进行存储,无法从数据中提取更多价值。而这样一个相对庞大的流程也决定了他们的核心诉求,即一方面亟需大数据平台支持海量时序数据分析,同时也希望延用原有 Python 技术体系以降低对新业务的探索成本。
因此,某保险集团车险部门选择引入了 YMatrix 超融合数据库,并以 YMatrix 为基础构建了一套高效的、易用的车险数字化运营平台。下面将详细为大家介绍某保险集团车险部门基于 YMatrix,依托车联网大数据构建车险业务数字化运营平台的经验与实践。
在这一整套流程当中,该车企将旗下大约 15 万辆车近 2 年的历史数据通过 Kafka 消费到 YMatrix 数据库当中,并将这 2 年历史数据当中的静态数据、 驾驶行为数据、车辆行驶数据以月为单位进行聚合,最终形成月保单数据。
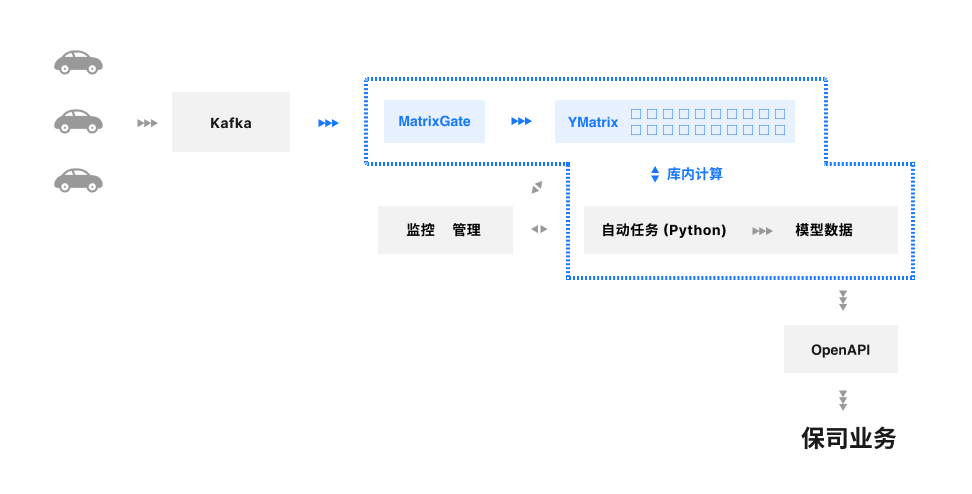 项目整体架构
项目整体架构
其中保单数据包含驾驶风险类的统计、运营风险类、道路风险类的聚合结果,通过 YMatrix 与保司数据的算法因子相关联,评估出车辆的驾驶分,为保险公司保险定价提供依据,具体实践可大致分为以下三部分:
YMatrix 高性能时序能力,对存储集群中的静态、驾驶行为、车辆行驶等数据进行整合分析,全方位支撑平台的海量数据存储和复杂分析需求;YMatrix 高性能时序能力,对存储集群中的静态、驾驶行为、车辆行驶等数据进行整合分析,全方位支撑平台的海量数据存储和复杂分析需求;
首先,平台需要将大约 15 万辆车的 2 年历史数据,通过 Kafka 消费到 YMatrix 数据库当中。但是车辆网下的数据写入场景十分复杂,包含分批合并、乱序、异频等场景;此外,不断增长车辆以及高频的采集频率都会产生巨大的数据量,对数据库的吞吐性能形成了极大挑战。
基于车联网这种典型时序数据应用场景,YMatrix 开发了 MatrixGate 高速写入工具,通过直接向数据节点(Segment)并行写入数据,之后再内对数据进行重分布的实现方式,消除了传统方式通过单一主节点(Master)写入时的单点瓶颈,从而达成最高到亿级数据点/秒的写入速度。
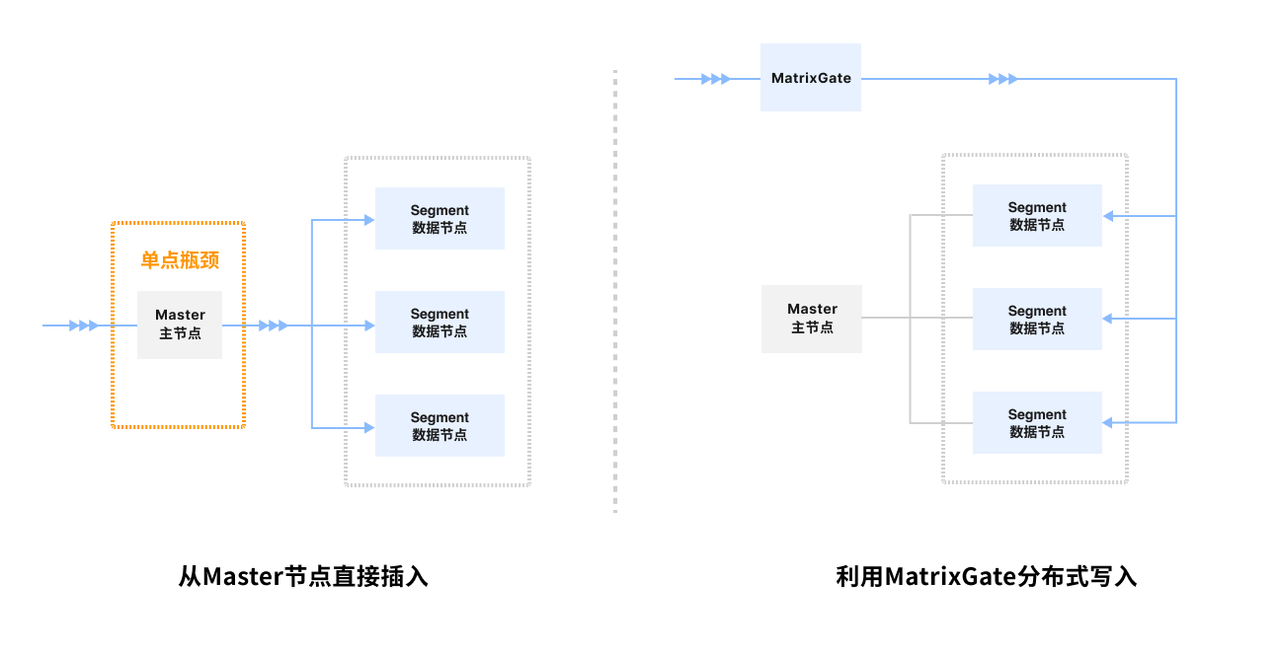 MatrixGate 写入流程
MatrixGate 写入流程
YMatrix 数据库天然支持 Kafka 无缝连接功能,可将 Kafka 数据持续自动导入到 YMatrix 表中,并支持图形化界面操作。随后,YMatrix 使用 MatrixGate 消费客户的 Kafka 集群中的 20 万行车辆的静态数据、驾驶行为数据、车辆行驶数据。
在写入期间,YMatrix 可将数据直接发送到 Segment 数据节点,实现并行高速写入,为后续基于驾驶行为的的分析提供 T+0 级的时效性。
库内机器学习,功能丰富,不仅易用更能充分利用集群算力,可快速计算出参保用户的危险等级,依托数据指标为不同用户提供定制化的参保服务;库内机器学习,功能丰富,不仅易用更能充分利用集群算力,可快速计算出参保用户的危险等级,依托数据指标为不同用户提供定制化的参保服务;
随后,他们将 20 万条车辆数据通过 web 平台解析后同步至 YMatrix 中,其中数据的三个字段分别为 vin 码、保费以及保额。通过 YMatrix 数据库内强大的机器学习能力,YMatrix 能够对已被写入的数据进行计算与分析,并与 vin 码进行关联并得出最终结果。
另一方面,Python 作为全球流行的开发语言之一,其被广泛应用于数据挖掘领域,对于此次车险数字化运营平台建设而言同样如此。YMatrix 支持 PL/Python、PL/R,使用 Python、R、C 等语言实现存储过程,并支持常用的 Python/R 函数库,在数据库内实现高效数据处理和机器学习。用不但保障了原有业务计算逻辑能够平滑迁移至YMatrix,后续新业务、新算法的开发仍然能够继续使用原有的Python技术栈,进一步降低了用户使用 YMatrix 的技术门槛。
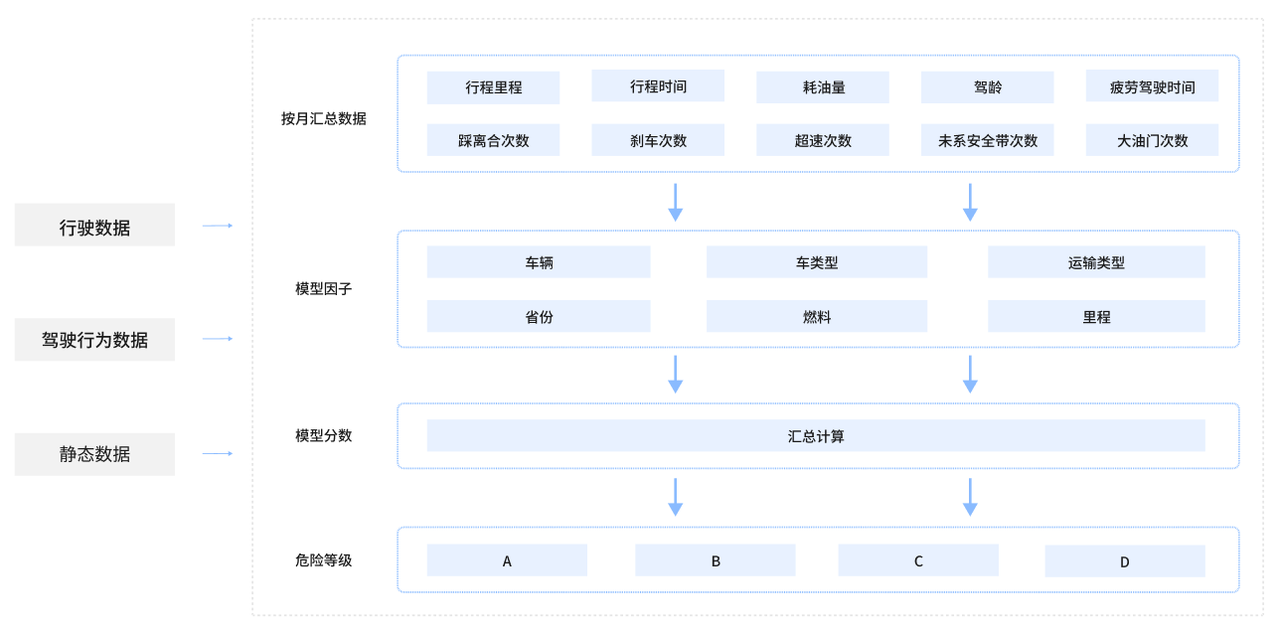 算法实现路径
算法实现路径
依托 YMatrix 数据库本身强大的性能和机器学习能力,根据算法模型因子可计算出车辆风险等级。如可分为 ABCDE 五个等级,A 等级(90 分以上),B 等级(80-90 分),C 等级(70-80 分),D 等级(60-70 分),E 等级(60 分以下)。A 等级为优秀客户,正常上保险正常理赔。D 等级或 E 等级如果上保险理赔的金额则会下降。
除了对客户分级之外,在人员与数据进行对应匹配后,可对用户进行标签化,根据数据以及得分可对用户实时生成“疲劳驾驶、超速”等标签,并汇总到平台之中,最终以图表等可视化的形式展现出来。
在计算出结果后,相关的用户数据将会以 API 的形式为保险集团车险部门提供查询支持,同时也会将接口开放,以 OpenAPI 平台的形式面向行业,为其它保险公司提供数据支撑,推动国内车险行业良性竞争有序发展。
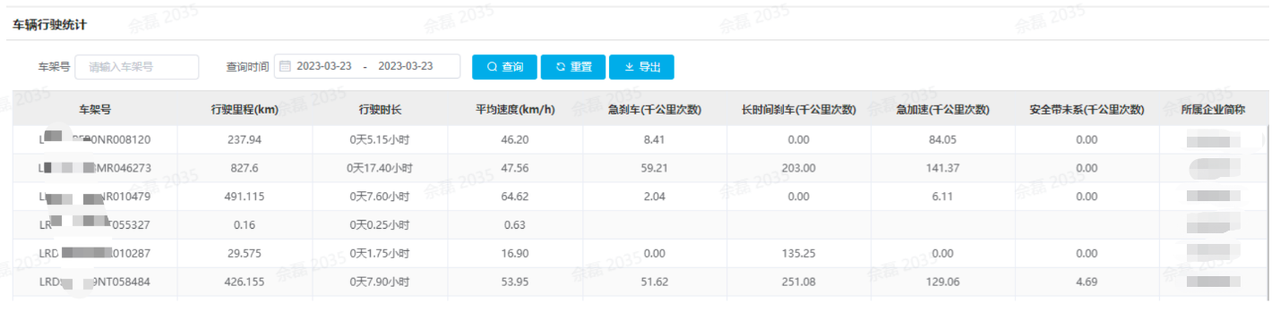 OpenAPI 平台界面
OpenAPI 平台界面
基于 YMatrix 超融合数据库,某保险集团车险部门在行业内率先构建了 AIoT 车险分析平台并应用于汽车保险场景。借助 YMatrix 丰富的库内数据清洗加工能力和高性能的库内机器学习算法,能够基于车辆信号和驾驶行为数据实时计算车况和驾驶危险系数,进而提供个性化定价服务,在降低汽车保费的同时充分保障了自身的收益。在当前车险市场低迷的大背景下,选择与 YMatrix 合作,针对性运营每一位用户,为保险定价提供科学依据,为车险平台的数字化探索提供了一条全新、可落地的实践方案。
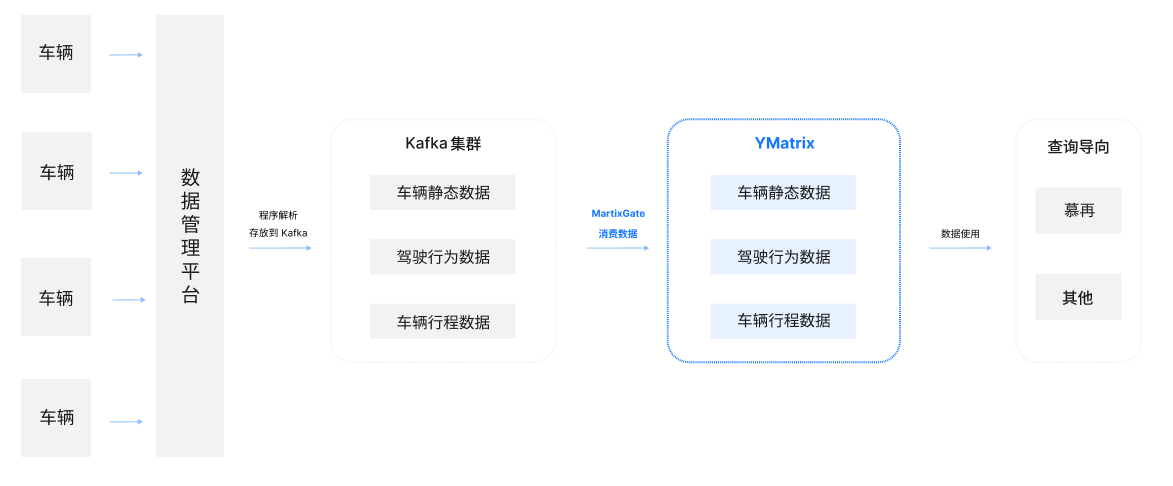 完成项目改造后的数据流通路径
完成项目改造后的数据流通路径
此外,在我们将视野放大到整个金融生态当中,可以发现金融产业中正在涌现出各式各样的细分业务场景。面对不同业务场景的不同需求,企业往往需要将更多的时间花费在数据库选型、功能取舍等前期工作上,这样所带来的结果往往是底层部署有许多不同的数据库,在后续运维管理上造成了相当复杂的局面。加之来自信创、数字化方面的压力逐渐增大,企业需要一套能够统一运行在各类场景下并优秀完成各项任务的融合型数据库。
这也是 YMatrix 超融合数据库所存在的价值,通过帮助企业在多场景下高效完成各类任务,满足业务生产对于性能的严苛需求,以一款数据库生态代替多套数据库体系,节约企业运维成本,降低集群管理难度,从而推动企业向数据驱动的数字化迈进。






