
在介绍 Compact 之前, 我们先来了解 3 个重要的概念:
读放大:读取数据时实际读取的数据量大于真正的数据量。例如 LSM-TREE 读取数据时需要扫描多个 SSTable
写放大:写入数据时实际写入的数据量大于真正的数据量。例如在 LSM-TREE 树中写入时可能触发 Compact 操作,导致实际写入的数据量远大于该 key 的数据量
空间放大:数据实际占用的磁盘空间比数据的真正大小更多。例如 SSTable 中存储的旧版数据都是无效的
LSM-TREE 通过顺序写入和后台合并来获得极高的写入吞吐能力,而 Compaction 策略决定了系统在写性能、读性能与资源消耗之间的核心权衡。
对于传统的 LSM-TREE,compaction 的策略主要有两种:Size-Tiered Compaction 和 Level compaction。
Tiering:先堆起来,攒多了再一起合并 (写优先),Tiering 就像文件先丢抽屉,满了再统一归档
Leveling:每一层都整理整齐,不允许乱放 (读优先),Leveling 就像每次都立刻放到分类清晰的书架上
Tiered 为写付费,Leveling 为读付费。
Size-Tiered Compaction vs Level Compaction
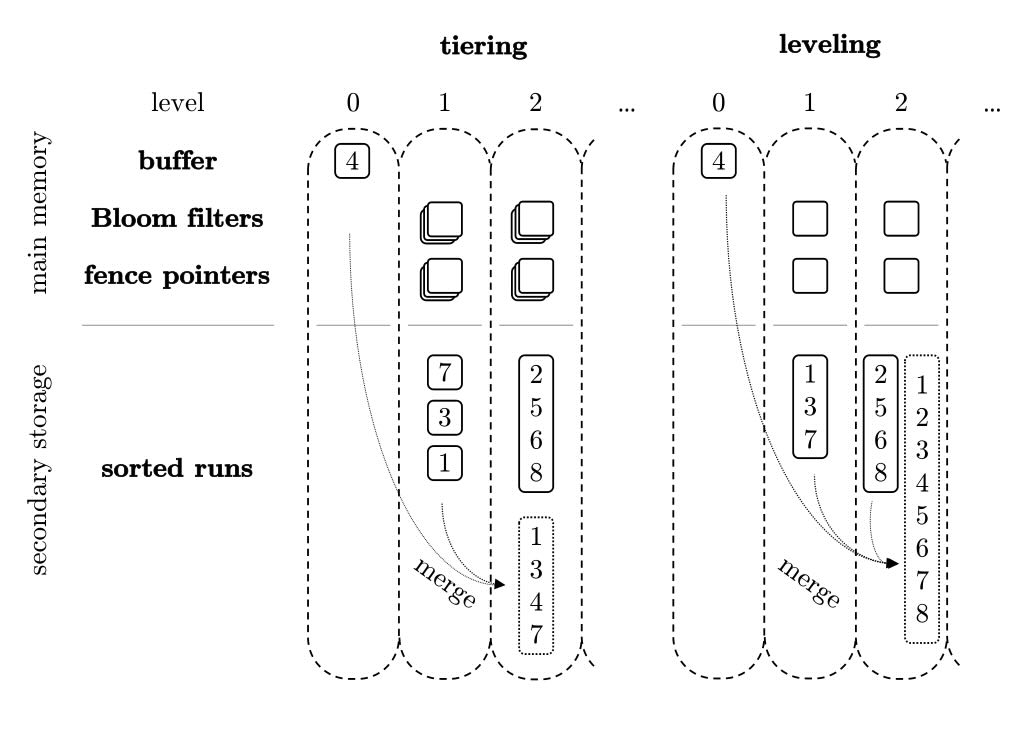
同一层允许 SST 互相重叠,更多是把大小相近的 SST 批量合并成更大的 SST,不强求每层严格不重叠。
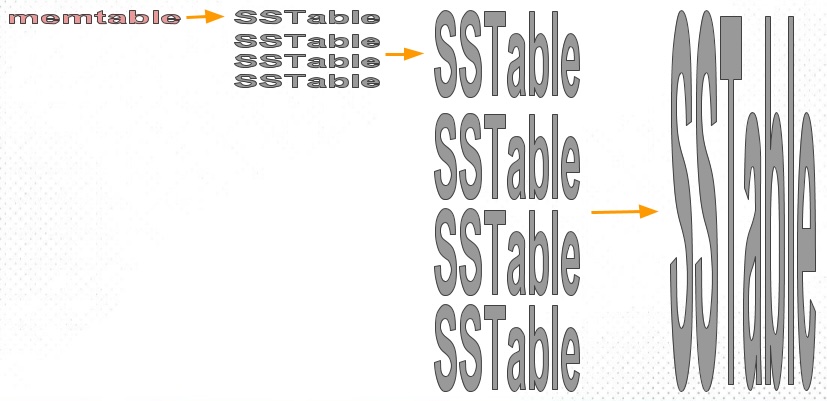
Size-Tiered Compaction Strategy (STCS) 的思路就是将大小相近的 sst merge 成一个新文件 memtable 逐步刷入到磁盘 sst,刚开始 sst 都是小文件,随着小文件越来越多,当数据量达到一定阈值时,STCS 策略会将这些小文件 compaction 成一个中等大小的新文件。同样的道理,当中等文件数量达到一定阈值,这些文件将被 compaction 成大文件,这种方式不断递归,会持续生成越来越大的文件。memtable 逐步刷入到磁盘 sst,刚开始 sst 都是小文件,随着小文件越来越多,当数据量达到一定阈值时,STCS 策略会将这些小文件 compaction 成一个中等大小的新文件。同样的道理,当中等文件数量达到一定阈值,这些文件将被 compaction 成大文件,这种方式不断递归,会持续生成越来越大的文件。
核心原则:
同一层允许存在多个 Key 范围重叠的 SST 文件
文件先堆积,达到数量阈值再统一合并
假设每个 SST 能存 4 个 key
第一次刷盘:SST-A: [1 – 4]
第二次刷盘:SST-B: [5 – 8]
第三次刷盘,这次有更新 + 新数据,写入 3,6,9,10,生成 SST-C: [3 – 10]
此时 Level 0 结构:[1–4] [5–8] [3–10]
C 与 A 在 3–4 重叠
C 与 B 在 5–8 重叠
查询 key=6 时必须同时查多个文件,这就是读放大。Tiered 的合并方式是当某一层文件数量达到阈值就触发合并,输出一个大文件,最终变成 [1 – 10]。
因此其优点是写入快、写放大小,但是缺点是查询要扫描多个文件,读放大。
每一层的 SST 尽量互不重叠 (key range disjoint),一旦有重叠就要把上层 SST + 下层所有重叠 SST合并重写。
优点:读放大低 (查一个 key/范围通常只要看很少文件)
缺点:写放大高 (频繁重写大量数据)
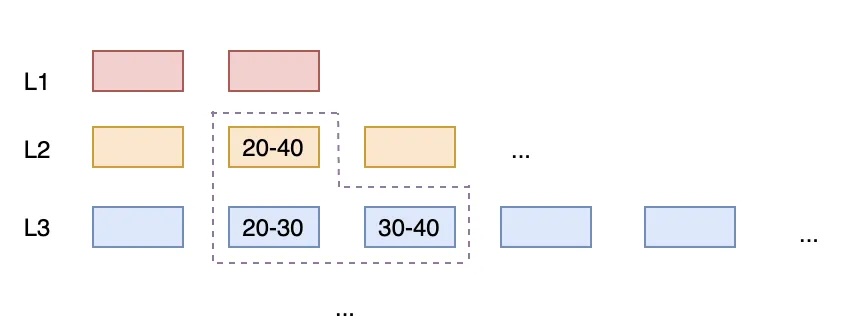
leveled 每层由多个 sstable 组成一个有序的的 run,sstables 之间互相也保持有序的关系,每层的数据 size 到达上限后与下一层的 run merge。这种方式将 level 的多个 run 降为一个,减小了读放大和空间放大,小 sstable 的方式提供了精细化任务拆分和控制的条件,控制任务大小也就是控制临时空间的大小。
核心原则:
每一层的 SST 文件 Key 范围必须互不重叠
全系统形成连续有序空间
同样的场景,发现重叠后立刻进行合并 [1–4] + [5–8] + [3–10] → [1–10],然后再次切分为 [1–5] [6–10],以此保证同层区间不重叠。
因此其优点是查询快,查询最多查一个文件,但是写放大大,后台 compaction 持续发生,IO 压力大。
| 维度 | Tiered | Leveling |
|---|---|---|
| 同层是否重叠 | 允许 | 不允许 |
| 写入成本 | 极低 | 中高 |
| 查询成本 | 高 | 极低 |
| 写放大 | 小 | 大 |
| IO 压力 | 轻 | 重 |
| 延迟稳定性 | 差 | 好 |
| 优先目标 | 吞吐 | 响应 |
MARS3 采用 Tiered compaction 的方式,简而言之,在 VIN+TS 的典型时序负载下,数据持续写入会导致新 run 与下层多个 run 的 key space 广泛重叠,使 Leveled Compaction 很难维持层内不重叠,进而频繁触发大范围重写,写放大显著且在 MPP 多实例场景被进一步放大。
假设现在有 3 个设备 (VIN=A,B,C),每个设备都在持续上报最新值。
现在系统里已经有一层 L1 文件,每个文件覆盖一个 VIN 的一个时间段:
L1 里已有:
A 的历史:A:[0~999]、A:[1000~1999]
B 的历史:B:[0~999]、B:[1000~1999]
C 的历史:C:[0~999]、C:[1000~1999]
这时新数据来了:
A 又上报了一些点:TS=1500~1700
B 又上报了一些点:TS=1600~1800
C 又上报了一些点:TS=1400~1650
这些新写入通常会先形成一个新的 run (比如在 L0 或上层),我们叫它 NewRun。NewRun 里面同时包含 A/B/C 的最新时间片,它覆盖的键范围大概是:
A:[1500~1700]
B:[1600~1800]
C:[1400~1650]
现在它会和 L1 哪些文件重叠?
A 的新数据会重叠 A:[1000~1999]
B 的新数据会重叠 B:[1000~1999]
C 的新数据会重叠 C:[1000~1999]
也就是说一个 NewRun 会同时重叠 L1 的多个文件(每个 VIN 都重叠一个)。
如果设备更多,比如 10,000 个 VIN 同时写,那么一个 NewRun 可能会重叠 成百上千个 L1 文件(取决于 L1 的切分方式)。而 Leveled 的要求是:L1 里文件要尽量不重叠。所以当 NewRun 要合并进 L1 时,Leveled 必须做这件事:把 NewRun + 所有与它重叠的 L1 文件读出来,重新合并排序,再写回成新的 L1 文件,保证写回后依然不重叠。这一步的代价是即便这次新写入只有很少数据 (比如 1GB),只要它碰到了很多 VIN 的历史段,它就会拖进来很多历史文件一起重写 (比如 10GB、50GB、100GB),造成验证的写放大。而 Size-Tiered 不强求下层不重叠,它更多是把同尺寸的 run 合并变大,不会为了消除重叠而每次拖进来一堆下层文件重写,所以在这个场景下,相对来说写放大的影响会更小一些。
与此同时,MARS3 的 RUN 为列存结构,需要足够大的物理连续性以保障扫描吞吐与压缩效率,这与 Leveled 常用的小 SST 粒度相冲突。Size-Tiered Compaction 则更契合该负载:它以合并同尺寸 run 为主,显著降低写放大,同时在时间推进的数据流下自然形成按时间聚集的 run 组织,使基于时间条件的过滤与跳读更有效。
为了控制读放大,我们为每一层限制了读放大系数,每一层的读放大超过这个系数以后就会触发向下层的 compaction:
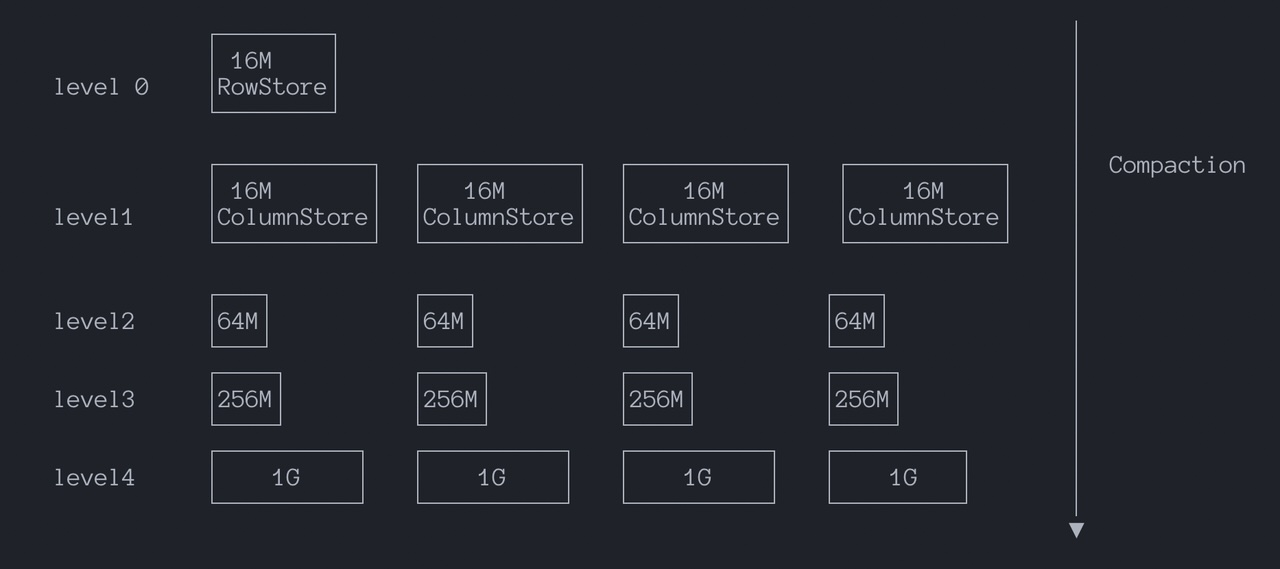
level_size_amplifier 用于指定 Level 尺寸的放大系数:
Level 尺寸的放大系数。Level 触发合并操作的阈值,计算方式为:rowstore_size * (level_size_amplifier ^ (level -1))。其值越大,读速越慢,写速越快。可以根据具体场景信息 (写多读少/读多写少、压缩率等) 来决定具体值。注意:确保每个 Level 的 run 数量不要过多,否则会影响查询性能,甚至阻止新数据插入
level_size_amplifier 的本质是控制每一层比上一层能大多少倍,就好比越往上是缓冲区,越往下是长期存储区
因此不难理解,amplifier 更大,每层能堆更久,run 更可能变多,导致查询检查更多对象 (读放大),但 compaction 触发少 (写更快),amplifier 更小,更早触发下沉整理,run 更少更整洁,读更快,但是 compaction 更频繁。rowstore_size 和 level_size_amplifier 两者合在一起,形成一个可控的下沉节奏,用来在 Tiered 模型下约束 run 堆积,从而限制读放大,同时尽量保留写吞吐优势。更多细节参照7.2 可观测性
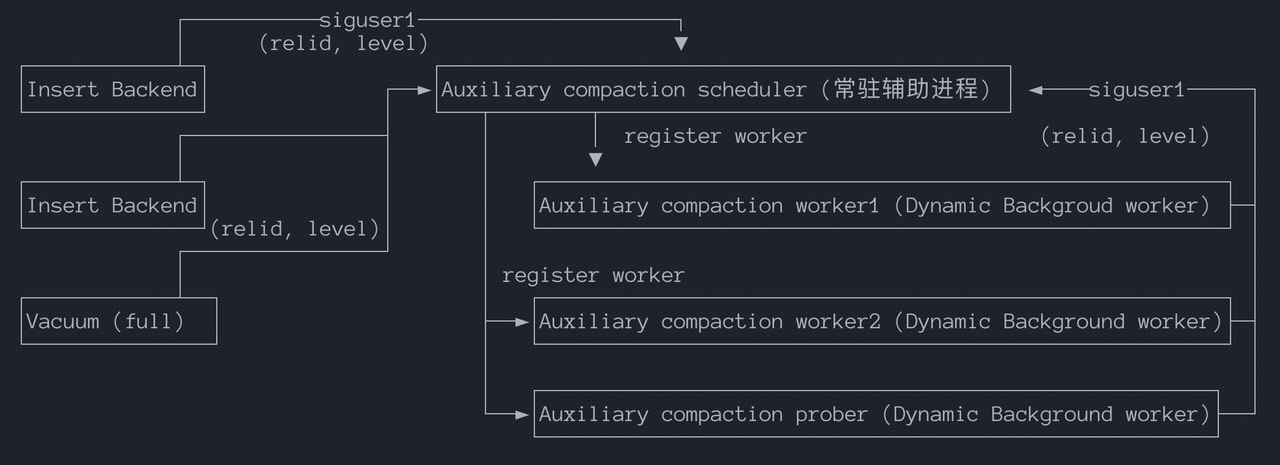
Compaction scheduler 主要负责:
启停 compaction worker
管理复用 compaction worker
确定 compaction 任务的优先级
正确响应数据库停机请求
Compaction worker:负责具体的 compaction 请求,同时检测到 level 的读放大超过限制以后,通知 scheduler 进程新的 compaction 请求,目前掣肘于进程模型,Compaction worker 的数量上限在代码中写死了 16 个。
Compaction prober:负责主动探测 compaction 任务,比如:
一些定时compaction任务
被中断的compaction任务
大体流程是:
1. Insert Backend 持续写入 RowStore
2. 当某个 RowStore 达到阈值,就会切换到一个新的 RowStore
3. 向 scheduler 发送 SIGUSR1,同时在共享内存里写入 compaction 请求信息:(relid, level)
4. scheduler 被唤醒,读取共享内存里的请求:
- 排队 / 去重 / 排优先级
- 选择新拉起 worker或复用空闲 worker
5. worker 开始执行 compaction对于 compaction,如果有多个表都需要做 compaction,但是总共就 16 个 worker,因此需要有一定的优先级,保证“最需要”的表能够及时进行 compact。
简而言之,compaction 会考虑比如 Level 的层次,越低级别越高;考虑是否是 Eager 还是 Lazy (手动和自动);compaction 的类型等等。
Autoprobe 的原理是,定时探测所有 Mars3 表的事务年龄和大小,以年龄除以大小为 score,autoprobe 可以对历史 Level 进行压缩。选出其中 score 最高的 N 个level触发 flush/compaction 任务。通过函数 matrixts_internal.mars3_autoprobe_candidates() 可以查看 autoprobe 的候选 level 及其 score。
adw=# select * from matrixts_internal.mars3_autoprobe_candidates();
segid | datname | relname | level | nruns | age | bytes | score
-------+---------+-------------+-------+-------+------------+-----------+-----------------------
0 | adw | t_w0_nosort | 1 | 13 | 616005 | 49888440 | 0.012347650076851471
0 | adw | t_w0_nosort | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w3b_3key | 0 | 1 | 2147483647 | 25034752 | 85.78010467209741
0 | adw | t_w1_1key | 1 | 7 | 329693 | 23821378 | 0.013840215288972788
...因为 autoprobe 总是选择 score 高的 level,为了防止由于 compaction 失败导致 autoprobe 不能处理其他 score 更低 level。增加了 autoprobe 的黑名单机制,同一个 compaction 失败 3 次后进入黑名单,不再继续重试:
通过函数mars3_autoprobe_blacklist() 可以查看黑名单;
通过函数mars3_autoprobe_blacklist_remove(regclass, level)可以删除当前数据库指定的level的黑名单;
通过函数mars3_autoprobe_blacklist_clear()可以删除所有黑名单;
GUC 说明:
guc mars3.autoprobe_period 控制多长时间探测一次,单位是秒,大于 0 为打开,0 为关闭,默认为关闭,可以先设置 10 分钟探测一次,再根据工作负载调整
guc mars3.autoprobe_workers 这个控制一次探测选出几个 level,默认为 2,注意这个占用的是普通 compaction 的 worker 数,并不是启动新的 worker
guc mars3.autoprobe_retry 控制重试次数,值为 2 则一共尝试 3 次;
guc mars3.autoprobe_blacklist_size 控制黑名单大小;
autoprobe 关了的影响就是没有写入的表,就不会进行 compact 了;有写入的表还是会不断 merge 的
ps aux | grep postgres | grep 'compact worker':此命令用于验证所有工作进程是否处于运行状态。检查是否存在未处于运行状态但已启动较长时间且未退出的工作进程,这些系统运行异常的迹象。
其次,在数据库日志中也会有 compact 相关活动信息,创建一张 t1 表并不断插入数据:
postgres=# create table t1(id int,info text)
using mars3 with(mars3options='prefer_load_mode=single,rowstore_size=64');
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE 新开窗口使用 matrixts_internal.mars3_level_stats 不断观察各个 Level 的状态
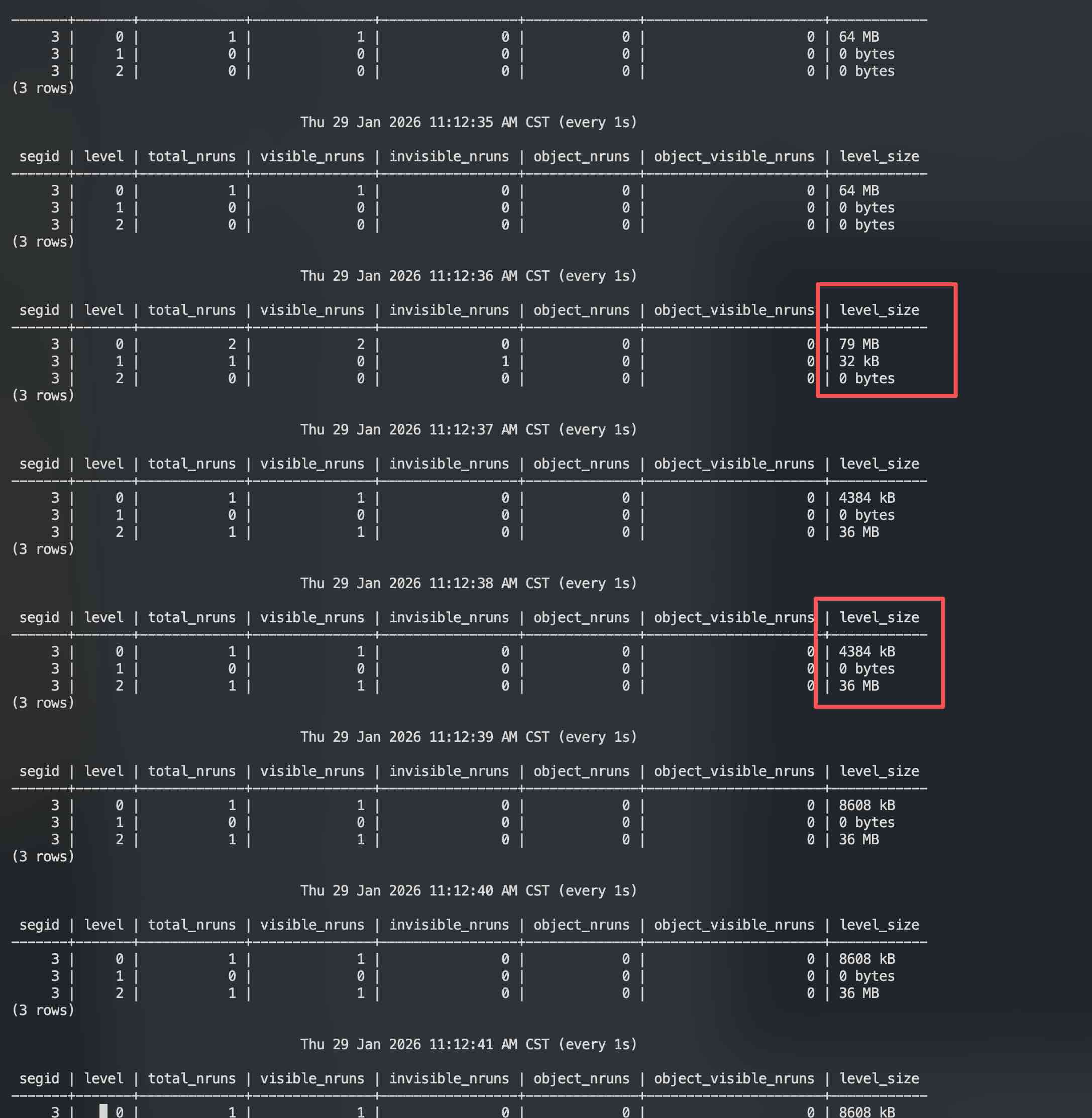
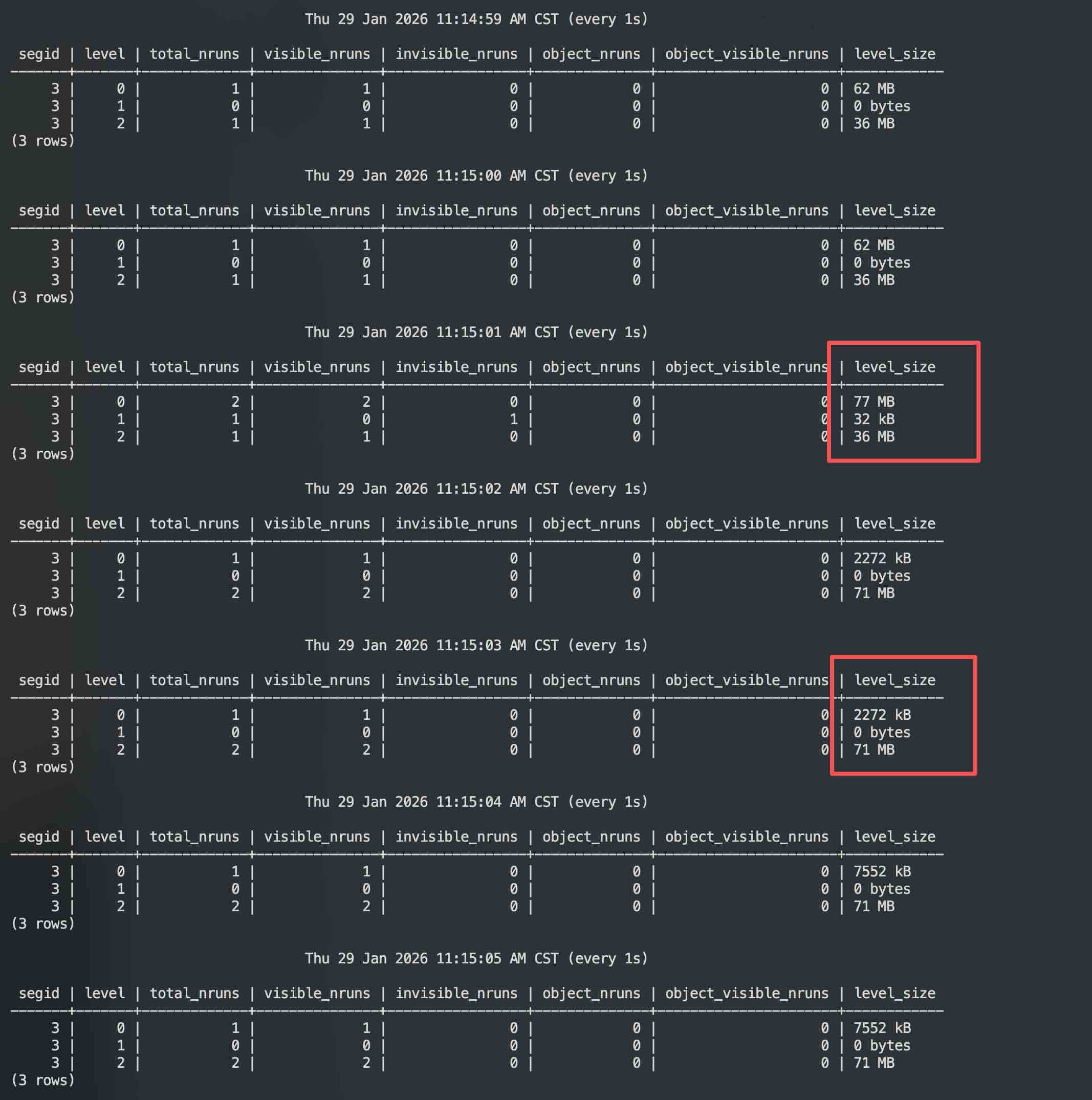
可以看到,当 L0 写满 64MB (rowstore_size) 之后,L1 短暂出现过 32 KB,然后直接往 L2 进行写。后续也是直接写入 L2,那么为什么会这样,为什么不是先直接写入 L1?
在 MARS3 中,有 adjust level 的逻辑 —— GetDesiredLevel
根据一个 Run 的大小 (TotalSize) 推算它应该属于哪个层级 (desired_level)
如果现在不在那个层级 (cur_level),就加锁,把这个 Run 从当前层挪到目标层
根据上面代码流程
run_size ≈ rowstore_size = 64MB
total_amp = run_size / rowstoresize = 64MB / 64MB = 1.0
desired_level = log(1.0) / log(8) = 0 / log(8) = 0
因此,这个 run 的理论相对层号是 0,其大小正好等于 rowstore_size 这一档
if (desired_level ERROR: there are too many segments, 6400 at most. please use VACUUM FULL.
某客户遇到的现象,将一个表 (同样结构,同样数据),从 BULK 模式往 Single 模式写入期间报错。原因是 Single 模式下写入太快,导致 compactor 来不及,生成了过的 Run,最终调大 rowstore_size 解决,但是调大 rowstore_size 会占用过多内存,需要进行权衡。
### 7.3.4 表大小过大
现象:使用元命令 \dt+ 查看表大小过大
可能原因:
- rowstore 中过多的 Run,仍是行存
- 过多的 invisible Runs
解决方式:
手动执行 vacuum + vacuum full,刷新为 columnstore,需要执行多轮,因为 vacuum full 涉及到 MERGE,也会产生 invisible,直到没有更多合并
### 7.3.5 如何获取表的排序键
```sql
adw=# create table testmars3(id int,info text) using mars3 distributed by (id) order by(id) ;
CREATE TABLE
adw=# \d+ testmars3
Table "public.testmars3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
info | text | | | | extended | |
Distributed by: (id)
Access method: mars3
Order by: (id)
adw=# select * from matrixts_internal.mars3_sortkeys('testmars3');
sks
------
(id)
(1 row) 从 6.5.0 开始 MARS3 正式支持增量备份,具备与 AO 表一致的表级增量备份能力:备份系统可以判断一张表自上次备份以来是否发生过数据修改或结构调整,从而只备份真正变过的内容,大幅减少备份规模与耗时。
YMatrix 新增了对数据修改变化的精确记录能力,类似 AO 表的 modcount 属性,通过参数 mars3.update_modcount 用户可以灵活控制是否开启该功能,从而让系统在每次对表进行写入、更新或删除时自动累加修改计数。此外,MARS3 也支持从 pg_stat_last_operation 视图中获取表的最近一次属性变更时间,用于识别结构层面的变化。
MARS3 最新支持版本支持记录数据修改变化情况,类似 AO 表的 modcount 属性,通过 mars3.update_modcount 参数来控制开启和关闭。并且支持从 pg_stat_last_operation 表中获取上一次修改表属性的时间。基于这两个功能实现 MARS3 表和 AO 表相同的增量 analyzedb 能力。
MARS3 面向的是企业中最常见、也最难平衡的一类场景:数据持续写入、查询持续发生,既要承接实时数据,又要支撑分析决策;既要明细回查,又要大范围聚合。
在这类场景下,客户最头疼的问题通常不是单点性能不够,而是系统容易割裂:为了同时满足实时写入与分析查询,不得不维护多套存储与计算链路,带来更高的架构复杂度、运维成本以及性能不确定性。MARS3 的核心价值,就是用一套统一的存储体系,把这些原本相互牵制的能力整合起来,形成可交付、可验证、可持续的系统能力。
在写入侧,MARS3 能够承接高频、小批、实时到达的数据,并通过后台有节奏地将数据整理为更适合分析的列式组织。这意味着客户不必在实时写入能力和分析性能之间做二选一:新数据可以快速进入系统,沉淀后的数据又能保持高效扫描与聚合。与此同时,MARS3 采用更适合混合负载的后台整理策略,有效控制写放大与资源竞争,避免系统随着数据增长、业务高峰和多实例并发而越来越“难写、难查、难维护”。
在查询侧,MARS3 的价值不仅是把数据读得更快,更重要的是尽量少读无效数据。通过排序键驱动的数据局部性、块级统计信息以及索引访问路径优化,系统可以在查询早期就缩小实际扫描范围,把“不命中就不读”的判断尽可能前移。对客户来说,这带来的直接收益是:同样的硬件资源可以支撑更多分析任务,同样的数据规模下查询更稳定,整体资源投入更可控。 这种收益并不依赖人工反复调优,而是由存储组织、跳读能力和索引优化共同形成的系统性能力。
更重要的是,MARS3 并不是只在理想负载下表现亮眼的“实验型能力”,而是补齐了生产环境真正需要的正确性与运维边界。在更新与删除场景下,它能够保证后台搬迁与合并过程中语义不丢;在并发更新场景下,它能够把“冲突报错退出”升级为“可等待、可追链、可重检”的正确行为;在治理与运维层面,它提供可观测的层级/run 统计、退化模式识别与参数化治理手段,使系统从“能跑”走向“能长期稳定跑”。这意味着,客户得到的不只是一个性能更好的存储引擎,而是一套更容易落地、更容易运维、也更适合长期承载核心业务的基础能力。
归根结底,MARS3 在 AP 核心 mixed workload 下的价值可以归纳为三点:
统一能力:用一套存储体系同时承接实时写入、分析扫描与明细回查,减少多套系统拼装带来的复杂度。
稳定能力:在持续写入、持续查询和后台治理并存的情况下,仍然保持性能与行为可预测,而不是“只在理想场景下快”。
落地能力:不仅追求性能指标,更注重正确性、可观测性与运维闭环,让系统真正具备长期上线运行的条件。
这正是 MARS3 的核心价值:它不是单纯提升某一项能力,而是帮助客户在最常见、最复杂的混合负载场景中,用更少的系统割裂、更低的总体成本和更高的长期稳定性,获得真正可持续的业务支撑能力。
BRIN 索引支持 multi-minmax
MARS3 支持 GIN 索引,很多现场遇到 like % 这类情况,只能用 HEAP + BTREE
可观测性进一步提升,目前关于 pick、compact 等都是记录在日志中的,需要去对应的 QE 上找,并且有些是面向内核开发者的,对于 field 不友好,希望有一个比如系统表类似gp_segment_configuration 记录历史 compact 信息,比如 compact 花费多少时间、merge 了多少 run 等等
期望 matrixts 和 mxnumeric 都放在 template1 ,然后设置 numeric 使用 mxnumeric,default_table_access_method = mars3 的问题就迎刃而解了,不会因为新的库没 matrixts 插件导致循环死锁,建不出来 extension 了,更何况 APM 啥的也是集成在 matrixts 插件,客户用 APM 还是要 create 这个插件
将 single 设为默认的写入模式
不过会有些情况下存在写放大的问题,所以等 Auto probe 搞好以后,可以默认加载模式设置成 single
mxnumeric 与 MARS3
PostgreSQL 的 numeric 类型 (以下简称 pg numeric) 虽然精度远高于其它数据库中的同名类型,但其实现更为复杂,性能也相对较差。pg numeric 难以实现向量化,导致在向量化执行器中不仅没有性能提升,反而因采用兼容机制运行,性能甚至低于非向量化执行器。与经过向量化加速的 int/float 等类型相比,pg numeric 的性能慢约 1-2 个数量级。为了提高 numeric 类型的性能,实现了一个有限精度的 numeric 类型 (以下简称 mxnumeric),最大支持 38 位精度,并通过 mxnumeric 扩展提供。
因为 mars3 和 mxnumeric 都是扩展,不能保证 mars3 的安装顺序一定在 mxnumeric 之前,所以默认 mxnumeric 类型是不支持 mars3_btree 和 mars3_brin 索引类型的。
如果需要使用 mars3_btree 和 mars3_brin 索引类型,可以使用 mxnumeric.set_config('mars3', true) 来手动创建 operator class,以支持 mxnumeric 类型使用 mars3_btree 和 mars3_brin 索引类型。不过必须保证 matrixts 插件已经创建,否则会提示错误
ERROR: data type numeric has no default operator class for access method "mars3_btree" HINT: You must specify an operator class or define a default operator class for the data type.
并且可以使用 mxnumeric.set_config('mars3', false) 来删除 operator class,恢复到默认状态。
术语表
Run:MARS3 中一段按排序键有序的数据集合,是存储与后台治理(合并/转列/回收)的基本单位。
Level:按层级组织 Run 的结构,低层更偏写入与快速落盘,高层更偏读优化与数据规整。
Delta:为支持更新/删除而追加记录的增量变化信息 (新版本/标记/差异),需通过后台治理逐步收敛回收。
MVCC:多版本并发控制机制,用版本可见性判断哪条数据对当前事务可见,并支持并发读写一致性。
先行后列:数据先以更适合写入/新鲜访问的形态进入系统,再在后台逐步转为更适合扫描与压缩的列式形态的生命周期策略。
行存 (RowStore):按行组织数据的物理布局,适合点查/明细回查与小范围读取,但分析扫描可能产生较多无效 I/O。
列存 (ColumnStore):按列组织数据的物理布局,适合大范围扫描与聚合、压缩效率高,但对高频小批次写入更敏感(维护/写放大更显著)。
排序键 (Sort Key / ORDER BY):决定数据在 Run 内的有序方式,是影响跳读效果、扫描效率与治理成本的关键设计。
数据局部性 (Locality):相近键值的数据在物理上尽量相邻,从而让范围查询更容易集中访问、减少扫描范围。
跳读 (Data Skipping):利用块级元数据 (如 min/max、BRIN 等) 在读取时跳过不可能命中的数据块,实现“少读”。
块级元数据 (Block Metadata):用于跳读与过滤的统计信息,例如块的最小/最大值、行数、可见性信息等。
BRIN:一种基于块范围摘要 (range summary) 的索引/元数据机制,用较低成本提供范围剪枝能力,常用于大表范围过滤。
default_brin:MARS3 针对典型工作负载默认启用/维护的一套 BRIN/跳读元数据策略,用于降低扫描范围与成本。
选择率 (Selectivity):谓词过滤后预计保留的数据比例;在 BRIN 场景下常对应“命中多少 range/页”的比例。
读放大 (Read Amplification):为了读到需要的数据,实际读取的数据量/对象数大于逻辑需求的倍数(例如需要跨多个 Run/版本查找)。
写放大 (Write Amplification):一次逻辑写入导致更多的物理写入(例如元数据维护、合并重写、转列等)产生的倍数效应。
合并 (Compaction):后台将多个 Run 整理/合并为更规整的数据形态,以降低读放大、回收无效版本并改善跳读与压缩效果。
合并债务 (Compaction Debt):尚未完成的后台合并工作量(治理缺口)的度量,债务累积通常会导致读路径变长或写入抖动。
转储 (Flush / Dump):将内存中的增量数据按顺序落盘,形成可持久化的 Run 的过程。
转列 (Row-to-Column / Columnization):将数据从更写友好的形态转换为列式布局,以提升扫描吞吐与压缩效率。
回收 (GC / Vacuum-like Reclaim):清理不再可见的版本/标记并回收空间的过程,通常与合并/整理协同完成。
Unique Mode:一种按唯一键(由排序键定义)插入即更新的模式,同键写入生成新版本,适合最新态/快照型数据模型。
shared_buffers:PostgreSQL 传统缓冲池,是否参与某类读路径取决于存储引擎的实现与访问方式。
varbuffer (mx_varbuffer_size_mb):MARS3 为特定访问路径(常见于索引相关访问)提供的专用缓存,用于降低重复读取与尾部延迟。
参数说明
adw=# select name,setting from pg_settings where name like '%mars3%';
name | setting
----------------------------------------+-------------------
mars3.allow_alter_rewrite | off
mars3.append_sync | off
mars3.archive_dontvacuum | off
mars3.autoprobe_period | 0
mars3.autoprobe_retry | 2
mars3.autoprobe_workers | 2
mars3.debug_block_skip | off
mars3.debug_btree_bloomfilter | off
mars3.debug_btree_build_summary | off
mars3.debug_btree_minmax | off
mars3.debug_clean_ignore_successor | off
mars3.debug_columnstripereader | off
mars3.debug_indexrollback | off
mars3.debug_logicdecode | off
mars3.debug_thread_insert | off
mars3.debug_uniquemode_sortkey | on
mars3.debug_update_chain | off
mars3.debug_use_deltachain | off
mars3.default_btree_options |
mars3.default_storage_options | compresstype=none
mars3.disable_physical_tlist | on
mars3.enable_autofreeze | off
mars3.enable_block_sample | off
mars3.enable_block_skip | on
mars3.enable_btree_bloomfilter | on
mars3.enable_btree_minmax | on
mars3.enable_inorderscan | on
mars3.enable_post_customscan_vectorize | on
mars3.force_allocate | off
mars3.freeze_in_compact | on
mars3.inplace_freeze_columnstore | off
mars3.mars3_autoprobe_blacklist_size | 1000
mars3.max_insert_threads | 2
mars3.punish_inorderscan | 1.15
mars3.test_print_index_info | off
mars3.trace_run_life | on
mars3.update_modcount | off
mars3.verify_rangefile | on
mars3_auto_analyze_projection | on
mars3_brin_buildsleep | 0
mars3_orderkey_contain_partkey | on
optimizer_enable_mars3_indexscan | on
(42 rows)注意:
debug/test 开头的 GUC ,生产基本也不要碰,调试用的
划线的 是已经弃用的参数
| 参数名称 | 当前设置 | 含义 |
|---|---|---|
| mars3.allow_alter_rewrite | off | 允许由 ALTER 操作触发的表重写。当修改表的存储选项会导致表重写时,需要显式启用此参数来确认操作。 |
| mars3.append_sync | off | 强制启用追加同步。控制 mars3 在追加数据时的同步行为。 |
| mars3.archive_dontvacuum | off | 归档后不执行 vacuum 操作,便于调试分析。 |
| mars3.autoprobe_period | 0 | 自动探测压缩任务的间隔时间(秒)。设置为 0 表示禁用自动探测功能。 |
| mars3.autoprobe_retry | 2 | 失败任务的重试次数。设置为 0 表示禁用重试。 |
| mars3.autoprobe_workers | 2 | 执行自动探测任务的工作线程数量(范围: 1-16)。 |
| mars3.debug_block_skip | off | 输出 block skip 的调试信息,用于调试跳过块的优化逻辑。 |
| mars3.debug_btree_bloomfilter | off | 输出 B 树布隆过滤器的调试信息。 |
| mars3.debug_btree_build_summary | off | 输出 B 树构建摘要的调试信息。 |
| mars3.debug_btree_minmax | off | 输出 B 树最小/最大值边界检查的调试信息。 |
| mars3.debug_clean_ignore_successor | off | 调试清理操作时忽略后继节点的逻辑。 |
| mars3.debug_columnstripereader | off | 调试 ColumnStripeReader 的读取行为。 |
| mars3.debug_index_rollback | off | 显示索引回滚的调试信息,用于分析 index rollback 相关问题。 |
| mars3.debug_logicdecode | off | 调试逻辑解码功能。 |
| mars3.debug_thread_insert | off | 调试多线程插入功能。 |
| mars3.debug_uniquemode_sortkey | on | 调试唯一模式下的排序键扫描。 |
| mars3.debug_update_chain | off | 调试更新链(update-chain)逻辑,用于分析 update-chain 相关问题。 |
| mars3.debug_use_deletechain | off | 调试删除操作使用增量链的逻辑。 |
| mars3.default_btree_options | (空) | 设置 mars3 存储 B 树索引的默认选项(如 compresstype、compresslevel、fillfactor、minmax、compressstd 等)。 |
| mars3.default_storage_options | compresstype=none | 设置 mars3 存储的默认选项(如 compresstype、compresslevel、mars3options、encodekind、uniquemode 等)。 |
| mars3.disable_physical_tlist | on | 禁止为 mars3 使用物理 tlist(目标列表)优化。 |
| mars3.enable_autofreeze | off | mars3 的 autovacuum 是否自动执行 autofreeze 操作。 |
| mars3.enable_block_sample | off | mars3 使用块采样方式进行分析统计。 |
| mars3.enable_block_skip | on | mars3 启用基于 BRIN 信息的块跳过优化。默认 brin 可以在 SeqScan 时跳过不相关的块,可以通过此参数禁用该优化。 |
| mars3.enable_btree_bloomfilter | on | 启用 B 树布隆过滤器检查。 |
| mars3.enable_btree_minmax | on | 启用 B 树最小/最大值边界检查。 |
| mars3.enable_inorderscan | on | mars3 提供带排序键的顺序扫描路径。 |
| mars3.enable_post_customscan_vectori ze | on | 已弃用,当时为了支持 ORCA 产生的 bitmapscan 的向量化而加的 |
| mars3.force_allocate | off | 强制分配 segment 和 run slot,平时必须为 false,仅用于处理当 run 或 segment 达到上限无法写入数据时,启用预留的 slot 进行数据合并的紧急情况。 |
| mars3.freeze_in_compact | on | 在 compact 过程中执行 freeze 操作。 |
| mars3.inplace_freeze_columnstore | off | 启用列存的就地冻结(inplace freeze)功能。 |
| mars3.mars3_autoprobe_blacklist_size | 1000 | 自动探测黑名单的最大容量,即最多可以跳过多少个任务。 |
| mars3.max_insert_threads | 2 | 单条插入操作最大可用的线程数(范围: 0-6)。0 表示不启用多线程,默认值为 2。 |
| mars3.punish_inorderscan | 1.15 | 为 mars3 的 inorderscan 成本增加惩罚系数(范围: 1.0-10.0),影响优化器选择顺序扫描的概率。 |
| mars3.test_print_index_info | off | 仅用于测试,打印额外的索引信息。 |
| mars3.trace_run_life | on | 打印 mars3 内部 run 的生命周期信息,用于分析问题。默认值为 true。 |
| mars3.update_modcount | off | 启用 modcount(修改计数)的更新。 |
| mars3.verify_rangefile | on | 列存输出 rangefile 时进行数据校验。默认值为 true。 |
| mars3.auto_analyze_projection | on | 自动分析时仅分析 order by 列,减少分析开销。 |
| mars3_brin_buildsleep | 0 | 索引构建前的休眠时间(毫秒),范围 0-600。用于测试和调试。 |
| mars3_orderkey_contain_parkey | on | 分区 mars3 表必须在 orderkey 中包含分区键(parkey)。 |
| optimizer_enable_mars3_indexscan | on | ORCA 优化器启用 mars3 的索引扫描。 |
参考配置模板与示例 SQL
CREATE EXTENSION matrixts;
CREATE TABLE t(
time timestamp with time zone,
tag_id int,
i4 int4,
i8 int8
)
USING MARS3
WITH (compresstype=zstd, compresslevel=3,compress_threshold=1200,
mars3options='rowstore_size=64,prefer_load_mode=normal,level_size_amplifier=8')
DISTRIBUTED BY (tag_id)
ORDER BY (time, tag_id);分区表
CREATE EXTENSION matrixts;
CREATE TABLE t(
time timestamp with time zone,
tag_id int,
i4 int4,
i8 int8
)
USING MARS3
WITH (compresstype=zstd, compresslevel=3,compress_threshold=1200,
mars3options='rowstore_size=64,prefer_load_mode=normal,level_size_amplifier=8')
DISTRIBUTED BY (tag_id)
PARTITION BY RANGE (time)
(
START ('2026-02-01 00:00:00+08')
END ('2026-03-01 00:00:00+08')
EVERY (INTERVAL '1 day')
)
ORDER BY (time, tag_id);
ORDER BY (time, tag_id);lz4、zstd、zlib 三种通用压缩算法需要在建表时用 WITH 语句中实现,示例如下:
=# WITH (compresstype=zstd, compresslevel=3, compress_threshold=1200)参数说明如下:
| 参数名 | 默认值 | 最小值 | 最大值 | 描述 |
|---|---|---|---|---|
| compress_threshold | 1200 | 1 | 8000 | 压缩阈值。用于控制单表多少元组(Tuple)进行一次压缩,是同一个单元中压缩的 Tuple 数上限 |
| compresstype | none | 压缩算法,支持zstd、zlib 和 lz4 | ||
| compresslevel | 0 | 1 | 压缩级别。值越小压缩越快,但压缩效果越差;值越大压缩越慢,但压缩效果更好。 不同算法有效值范围: 1. zstd: 1-19 2. zlib: 1-9 3. lz4: 1-20 |
当指定 compresstype 默认值,未指定 compresslevel 默认值时,compresslevel 默认值为 1。 当 compresslevel > 0,未指定 compresstype 默认值时,compresstype 默认值为 zlib。
以下参数用于调节 L0 层 Run 的大小,也可间接控制 L1 层之上的 Run 大小。
| 参数 | 单位 | 默认值 | 取值范围 | 描述 |
|---|---|---|---|---|
| rowstore_size | MB | 64 | 8 ~ 1024 | 用于控制 L0 Run 何时切换。当数据大小超过该值,将会切换下一个 Run |
以下参数用于指定数据在 MARS3 中的加载模式。
| 参数 | 默认值 | 取值范围 | 描述 |
|---|---|---|---|
| prefer_load_mode | normal | normal / bulk | 数据加载模式。 - normal:正常模式,新写入数据先写到 L0 层的行存 Run 中,积累到 rowstore_size 之后,落至 L1 层的列存 Run;相对于 bulk 模式多一次 I/O,列存转换由同步变为异步,适用于 I/O 能力充足且对延迟敏感的高频次小批量写入场景。- bulk:批量加载模式,适用于低频大批量写入场景,直接写至 L1 层的列存 Run;相对于 normal 模式减少一次 I/O,列存转换由异步变为同步,适用于 I/O 能力不足且对延迟不敏感的低频大批量数据写入场景。 |
以下参数用于指定 Level 尺寸的放大系数。
| 参数 | 默认值 | 取值范围 | 描述 |
|---|---|---|---|
| level_size_amplifier | 8 | 1 ~ 1000 | Level 尺寸的放大系数。Level 触发合并操作的阈值,计算方式为:rowstore_size * (level_size_amplifier ^ level)。其值越大,读速越慢,写速越快。可根据具体场景(写多读少/读多写少、压缩率等)决定具体值。 注意:确保每个 Level 的 run 数量不要过多,否则会影响查询性能,甚至阻止新数据插入。 |
6.7.0
MARS3 支持了在 drop/truncate table 时终止持锁阻塞的 compact 任务
pg_rewind 支持了 MARS3 表的增量修复
6.6.0
MARS3 支持了 DEFAULT BRIN
支持并发 alter table split partition,split 的同时支持并发的读和写 (暂时不支持 aoco 表,stream 流表,且父表带有 trigger 的情况)
MARS3 支持了线程插入 (目前只在 prefer_load_mode = normal/bulk 时且数据量超过 rowstore 大小时有效),不是所有的插入都会触发线程化插入,只有当单次插入超过 rowstore_size 时才会触发线程化插入,另外线程化插入也会导致内存使用变大
6.5.0
MARS3 放松了unique mode 创建 btree 索引时的顺序限制
MARS3 支持了 unique mode 场景下的 delete 操作
MARS3 支持了 btree inorder scan
MARS3 支持了增量 analyzedb 与增量 mxbackup
MARS3 新增提供 mars3.default_storage_options, mars3.default_btree_options 两个GUC,用于指定默认的 mars3 存储参数
6.4.1
新增 ORCA 支持 MARS3 索引
增强了 MARS3 的 analyze 逻辑,采用基于行的采样
新增了 MARS3 在分区表上的 drop index 的功能 (#ICGEOH)
6.4.0
MARS3 支持了 roi 索引
MARS3 支持了自动转换 btree/brin 到 mars3_btree/mars3_brin 索引
MARS3 分区表支持了 drop index






