





博客/
博客/

В реальном мире клиентские системы данных редко бывают чисто OLTP или чисто OLAP. При смешанных нагрузках традиционные системы хранения естественным образом разделяются: одни движки отлично справляются с сканированием и сжатием, но не выдерживают частые небольшие записи и обновления в долгосрочной перспективе; другие обеспечивают быструю запись и стабильный поиск по точкам, но имеют высокую стоимость и низкую эффективность при полном сканировании таблиц и агрегации. При попытке объединить несколько систем в так называемый HTAP возникают проблемы с актуальностью данных, изоляцией ресурсов, сложностью эксплуатации и общей стоимостью.
Поэтому мы разработали MARS3 — движок хранения, ориентированный на смешанные нагрузки с ядром AP. Его цель — не заменить все существующие решения, а разместить наиболее распространенные и критически важные смешанные рабочие нагрузки клиентов в единой управляемой системе хранения, обеспечив стабильность производительности и надежности под высокой нагрузкой за счет понятных механизмов.
Если вы занимаетесь выбором решений, рекомендуем сначала ознакомиться с главами 1–2, чтобы понять границы применимости.
Если вы архитектор или DBA, уделите особое внимание главам 3–6 для понимания механизмов и затрат.
Если вы отвечаете за внедрение и эксплуатацию, глава 7 предоставит быстрые пути решения проблем и шаблоны.
MARS3 ориентирован на смешанные нагрузки с ядром AP — в приоритете эффективность сканирования и агрегации, стабильность при непрерывной записи, а также удобство проверки детальных данных в типичных сценариях. При этом MARS3 не стремится достичь предельных показателей по всем параметрам, например, для экстремально чистых TP-нагрузок или сверхвысокочастотных крупномасштабных обновлений.
В большинстве клиентских систем данные не записываются сначала полностью, а затем анализируются — они записываются и используются одновременно, требования бизнеса к актуальности становятся все строже. Бизнесу нужны максимально свежие данные: данные оборудования производственной линии должны сразу формировать дашборды, статус транспортных средств в интернете вещей должен немедленно вызывать оповещения и анализ, данные сенсоров IoT-платформ должны поддерживать анализ трендов и обнаружение аномалий в реальном времени. При этом специалисты по эксплуатации и разработке должны в любое время проверять детальные данные — например, находить исходные записи определенного оборудования, транспортного средства, рабочего места за определенный период — и на их основе выполнять агрегацию, корреляционный анализ или объединение нескольких таблиц.
Общая черта таких сценариев: нагрузка смешанная, преимущественно аналитическая, с непрерывной записью. Сторона записи может включать пакетную загрузку (исторический анализ, ежедневная пакетная обработка), непрерывную микропакетную запись (T+0, минутная агрегация) и даже разрозненные точечные записи и корректировки. Сторона запросов включает глобальные сводные отчеты, сканирование с фильтрацией и частый поиск по отдельным сущностям.
Таким образом, суть противоречия не в выборе между быстрой записью и быстрым запросом, а в том, может ли система сохранить эффективность анализа и стабильную эффективность записи при одновременной непрерывной записи и анализе.
При смешанных нагрузках проблема не в том, хорошая или плохая определенная система, а в том, что разные формы хранения изначально ориентированы на разные задачи.
Строковое хранение — классический способ хранения в традиционных базах данных (например, PostgreSQL, MySQL), при котором полные данные каждой строки упаковываются вместе, как «целые коробки». Оно подходит для проверки детальных данных и получения небольшого количества записей по первичному ключу или условию. Однако при аналитических запросах (используется несколько столбцов, требуется сканирование большого объема данных для фильтрации/агрегации) системе приходится считывать всю строку, даже если большинство столбцов не нужны.
Результат:
Прочитано много ненужных столбцов, занята пропускная способность диска и кэша.;
Замедление сканирования и агрегации, увеличение потребления ресурсов;
Усиление неэффективного ввода-вывода и рост стоимости при увеличении объема данных.
Колоночное хранение для эффективного сканирования и высокой степени сжатия требует более сложной организации данных и поддержки метаданных (например, ClickHouse, HBase). Запись при этом не ограничивается добавлением записей — она включает дополнительную структурную поддержку:
Увеличение записи: одно логическое запись может вызвать несколько физических записей (несколько блоков столбцов, метаданные) и фоновое слияние/перезапись для поддержки качества организации данных;
Эффект малых пакетных записей: при высокочастотной микропакетной или непрерывной малой пакетной записи фиксированные затраты на единицу данных увеличиваются, частота слияния/перезаписи растет, создавая долгосрочную эксплуатационную нагрузку;
Связь с обновлениями и удалениями: колоночное хранение обрабатывает UPDATE/DELETE через версии/метки/перезапись для устранения фрагментации. При росте доли обновлений и удалений и недостаточной фоновой поддержке возникает увеличение занимаемого пространства и удлинение пути чтения.
Поэтому колоночное хранение идеально подходит для аналитики с преобладанием чтения, но при смешанных нагрузках предъявляет повышенные требования к пути записи и фоновой поддержке.
Размещение записи в одной системе, анализа — в другой, и соединение их через синхронизацию/ETL теоретически дает преимущества обеих сторон . Но на практике возникают издержки: данные «переезжают», чем длиннее цепочка, тем сложнее достичь высокой актуальности; чем больше систем, тем сложнее согласование показателей, восстановление после сбоев, права доступа и мониторинг, а общая стоимость растет.
С точки зрения бизнеса запрос «быстрая запись, быстрый запрос и низкая стоимость» кажется противоречивым. Но с инженерной точки зрения смешанные нагрузки не распределены равномерно: в большинстве бизнес-процессов основная ценность системы заключается в получении аналитических результатов (отчеты, метрики, диагностика, инсайты), а запись и проверка детальных данных нужны для непрерывного поступления и доступности данных.
Поэтому компромиссы проектирования MARS3 четкие: ориентация на смешанные нагрузки с приоритетом AP, создание управляемой системы хранения вокруг эффективности анализа и стабильности при непрерывной записи:
При росте объема данных и параллелизма система должна выполнять аналитические запросы с меньшим неэффективным вводом-выводом, лучшим пропуском и более высокой пропускной способностью. Стремиться к «максимальной отдаче от единицы ресурсов» для стабильного выполнения крупных запросов и периодической статистики.
Поддержка различных форм записи — от пакетной загрузки до непрерывной микропакетной (T+0), гарантия предсказуемости системы при «непрерывной записи и непрерывном запросе». Фоновая обработка (слияние, восстановление и т.д.) должна быть управляемой, а не передавать случайную нагрузку на онлайн-запросы.
Обеспечение удобного доступа для типичных бизнес-задач — поиск по отдельным сущностям, запросы по временным диапазонам, выборку с фильтрацией — исключение разрыва между сильной аналитикой и неудобной проверкой деталей.
MARS3 использует модель организации данных в стиле LSM‑Tree: записи быстро принимаются и последовательно записываются на диск, а при чтении используется высокая эффективность пропуска и сканирования за счет упорядоченности данных. Между слоями работает фоновый процесс управления, который постепенно преобразует структуру, оптимизированную для записи, в структуру, оптимизированную для чтения.
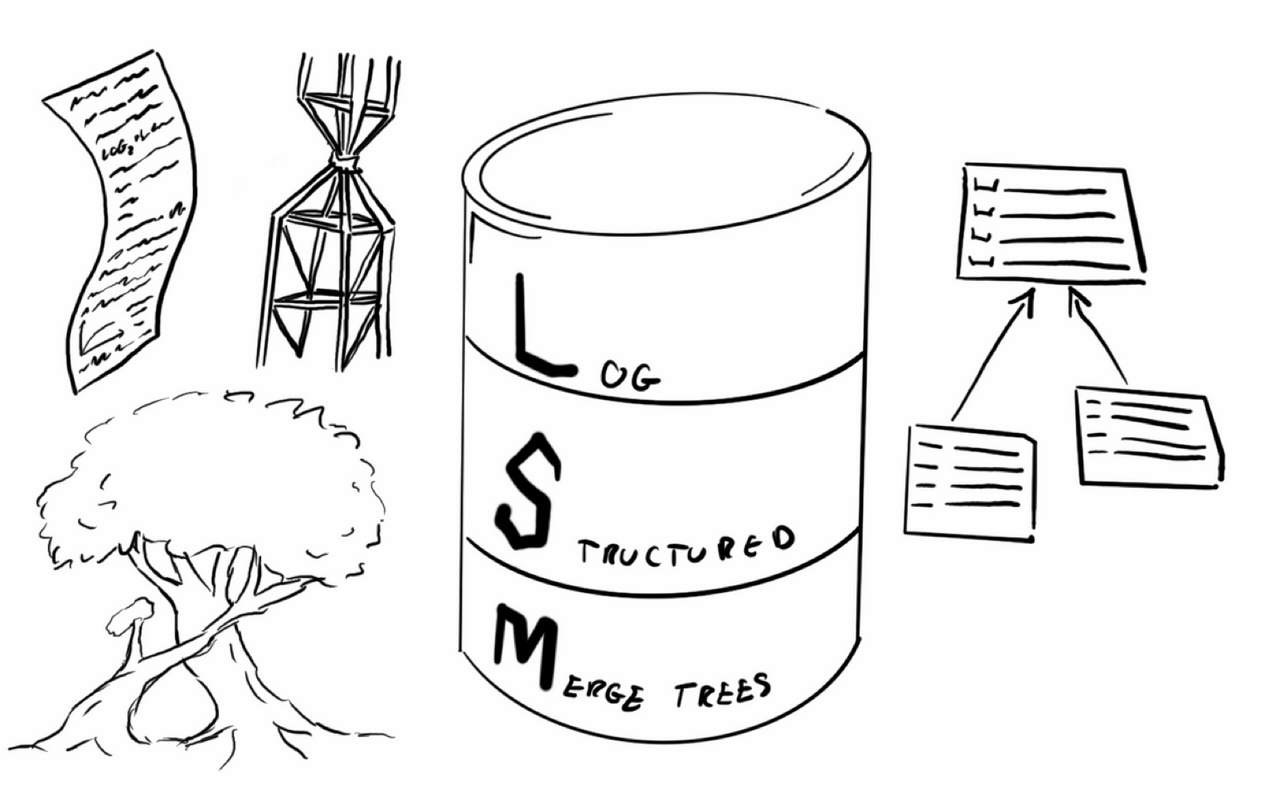
В данной модели выделяются три ключевых объекта: Run и Level (определяют сегментацию и иерархию данных), RowStore и ColumnStore (баланс между записью и чтением), Delta и MVCC (механизм обновлений и удалений).
В MARS3 все данные хранятся в упорядоченном виде. Непрерывный фрагмент упорядоченных данных называется Run.
В RocksDB, Leveldb аналогичные блоки называются SST; в YMatrix Run является аналогом SST.
Существует два типа Run:
Для высокоскоростной записи новые данные сначала сохраняются как RowStore‑Run (строковой).
Далее для оптимизации чтения и сжатия они преобразуются в ColumnStore‑Run (колоночный).
Ограничение размера одного Run:
Параметр таблицы max_runsize — максимальный размер одного Run (до 16384 МБ).
По умолчанию: 4096 МБ.
Для просмотра файлов таблицы MARS3 используется функция:matrixts_internal.mars3_files
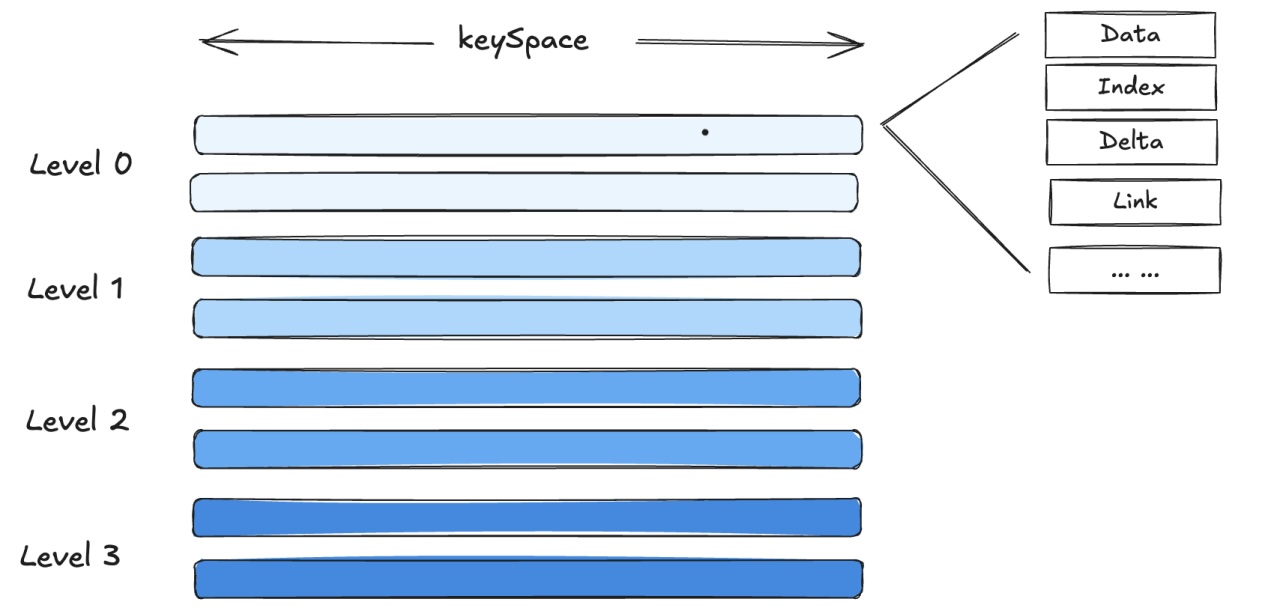
Основные типы файлов:
DATA: основные файлы с пользовательскими данными.
FSM (Free Space Map): отслеживает освобожденное пространство после удаления устаревших версий.
LINK: поддерживает связи между версиями кортежей при обновлениях и удалениях во время слияния.
DELTA: хранит информацию об удалениях; обновления и удаления в MARS3 не изменяют данные на месте, а управляют видимостью через Delta и версионность.
INDEX / INDEX_1_TOAST: файлы индексов.
postgres=# select * from matrixts_internal.mars3_files('test');
segid | level | run | file | seq | path | bytes
-------+-------+-----+---------------+-----+----------------------------+---------
1 | 0 | 1 | DATA | 0 | base/14011/235713_meta_1.2 | 1081344
1 | 0 | 1 | DELTA | 0 | base/14011/235713_meta_1 | 32768
1 | 0 | 1 | LINK | 0 | base/14011/235713_meta_1.1 | 0
1 | 0 | 1 | FSM | 0 | base/14011/235713_meta_1.3 | 131072
1 | 0 | 1 | INDEX_1 | 0 | base/14011/235713_meta_1.4 | 65536
1 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/235713_meta_1.5 | 0
2 | 0 | 1 | DATA | 0 | base/14011/253866_meta_1.2 | 1081344
2 | 0 | 1 | DELTA | 0 | base/14011/253866_meta_1 | 32768
2 | 0 | 1 | LINK | 0 | base/14011/253866_meta_1.1 | 0
2 | 0 | 1 | FSM | 0 | base/14011/253866_meta_1.3 | 131072
2 | 0 | 1 | INDEX_1 | 0 | base/14011/253866_meta_1.4 | 65536
2 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/253866_meta_1.5 | 0
3 | 0 | 1 | DATA | 0 | base/14011/243459_meta_1.2 | 1081344
3 | 0 | 1 | DELTA | 0 | base/14011/243459_meta_1 | 32768
3 | 0 | 1 | LINK | 0 | base/14011/243459_meta_1.1 | 0
3 | 0 | 1 | FSM | 0 | base/14011/243459_meta_1.3 | 131072
3 | 0 | 1 | INDEX_1 | 0 | base/14011/243459_meta_1.4 | 65536
3 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/243459_meta_1.5 | 0
0 | 0 | 1 | DATA | 0 | base/14011/238674_meta_1.2 | 1081344
0 | 0 | 1 | DELTA | 0 | base/14011/238674_meta_1 | 32768
0 | 0 | 1 | LINK | 0 | base/14011/238674_meta_1.1 | 0
0 | 0 | 1 | FSM | 0 | base/14011/238674_meta_1.3 | 131072
0 | 0 | 1 | INDEX_1 | 0 | base/14011/238674_meta_1.4 | 65536
0 | 0 | 1 | INDEX_1_TOAST | 0 | base/14011/238674_meta_1.5 | 0
(24 rows) Данные в MARS3 организованы по уровням на основе LSM‑Tree. Всего поддерживается 10 уровней: L0, L1, L2, ..., L9.
Когда количество Run на одном уровне или их суммарный размер достигает порога, запускается процесс слияния: несколько Run объединяются в один и переходят на следующий уровень. Para ускорения работы разрешено параллельное выполнение нескольких слияний на одном уровне.

В YMatrix работают фоновые процессы, которые периодически проверяют состояние таблиц и запускают слияние.
Для просмотра статистики по уровням используется функция:matrixts_internal.mars3_level_stats
postgres=# select * from matrixts_internal.mars3_level_stats('test') limit 10;
segid | level | total_nruns | visible_nruns | invisible_nruns | object_nruns | object_visible_nruns | level_size
-------+-------+-------------+---------------+-----------------+--------------+----------------------+------------
1 | 0 | 1 | 1 | 0 | 0 | 0 | 1280 kB
1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 2 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 4 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 5 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 6 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 7 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 8 | 0 | 0 | 0 | 0 | 0 | 0 bytes
1 | 9 | 0 | 0 | 0 | 0 | 0 | 0 bytes
(10 rows) Практические правила здоровья таблицы:
Уровень L0: состояние неудовлетворительное, если Run > 3.
Уровень L1: состояние неудовлетворительное, если Run > 50.
Уровни L2 и выше: состояние неудовлетворительное, если Run > 10.
ColumnStore не использует буферный слой вроде Shared Buffers, данные записываются и читаются напрямую.
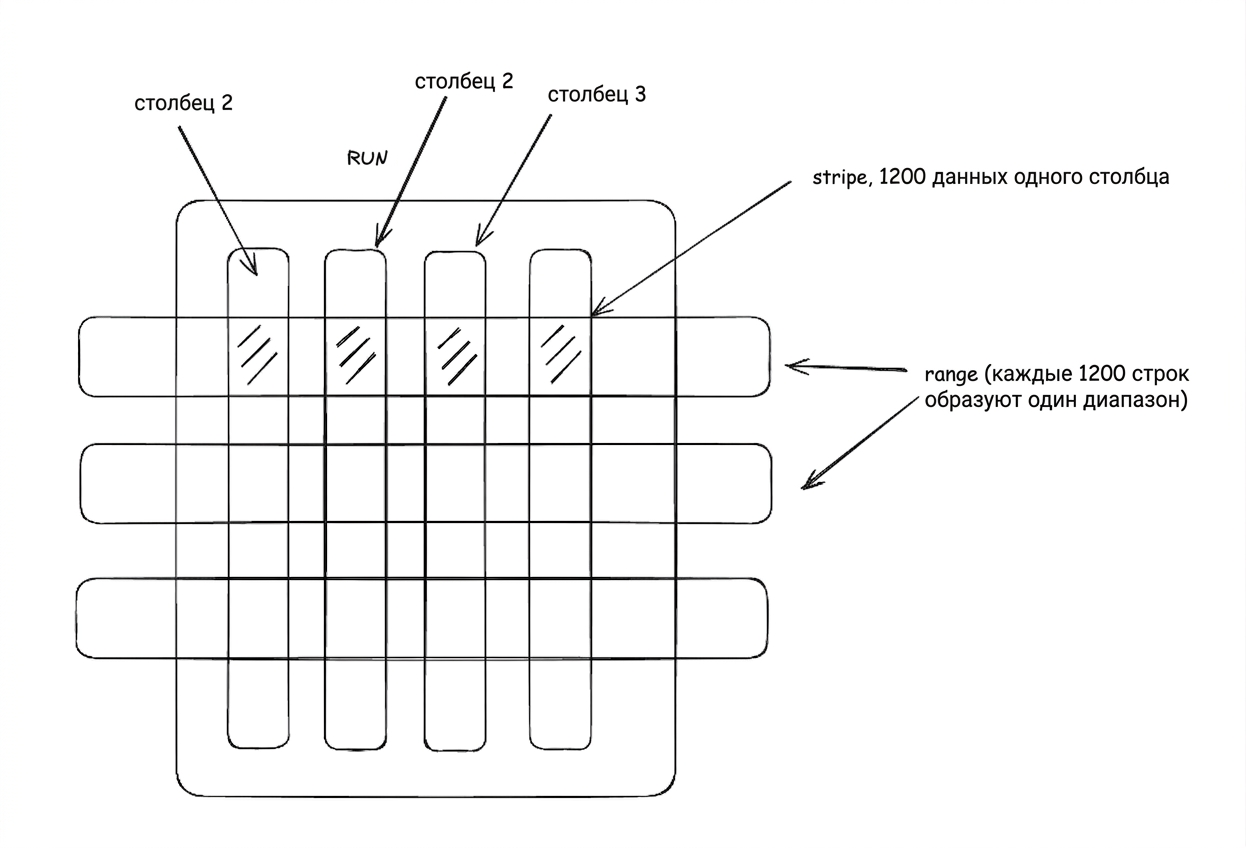
Range: логический блок, состоящий из compress_threshold строк (по умолчанию 1200 строк).
Stripe: данные одного столбца внутри одного Range.
Если столбец очень большой, Stripe разбивается на блоки по 1 МБ.
Структура:
RUN
└── Range (по строкам, по умолчанию 1200 строк)
├── column1 stripe (1200 значений)
├── column2 stripe (1200 значений)
├── column3 stripe (1200 значений)
└── ...Range: логическое окно по строкам.
Stripe: физический блок столбца.
Datum: минимальная единица — значение одного столбца в строке.
MARS3 сочетает строковое и колоночное хранение для удовлетворения смешанных нагрузок:
RowStore оптимизирован для записи и доступа к свежим данным; подходит для быстрого вставления и точечных запросов.
ColumnStore оптимизирован для сканирования и агрегации; обеспечивает высокую скорость аналитических запросов и эффективное сжатие.
Принцип работы: сначала строка, потом столбец — данные сначала поступают в строковом виде для быстрой записи, затем фоновым процессом преобразуются в колоночный для эффективного чтения.
Поддерживается три режима записи (управляются параметрами prefer_load_mode и owstore_size):
Normal (по умолчанию): данные сначала в RowStore L0, затем при накоплении преобразуются в ColumnStore L1.
Bulk: массовая загрузка — данные сразу записываются в ColumnStore L1.
Single: данные напрямую помещаются в RowStore в Shared Buffers.
MARS3 поддерживает два типа индексов: BRIN и BTREE. На одну таблицу допускается не более 16 индексов любого типа.
BRIN — это лёгковесный индекс на основе диапазонных сводок, предназначенный для сверхкрупных таблиц данных. Он не указывает напрямую на конкретные строки, а поддерживает для непрерывных блоков данных статистическую информацию, такую как минимальные и максимальные значения, чтобы на этапе выполнения запроса быстро отсеивать области блоков, не содержащие искомых данных, тем самым значительно сокращая объём сканируемых операций ввода-вывода.
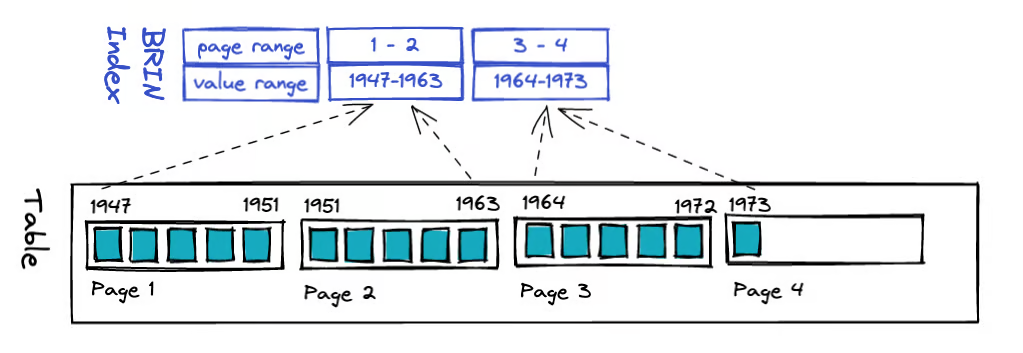
BRIN занимает крайне мало места на диске и имеет очень низкую стоимость создания и обслуживания, однако эффективность запросов сильно зависит от физической упорядоченности данных. При записи данных в порядке временных меток или возрастающих ключей BRIN обеспечивает производительность сканирования, близкую к эффективности секционирования, в сценариях анализа временных рядов и обработки логов. Это важное дополнение к индексам для крупных аналитических таблиц. Например, при поиске данных со значением 250 можно быстро определить, что они находятся в третьем блоке данных.
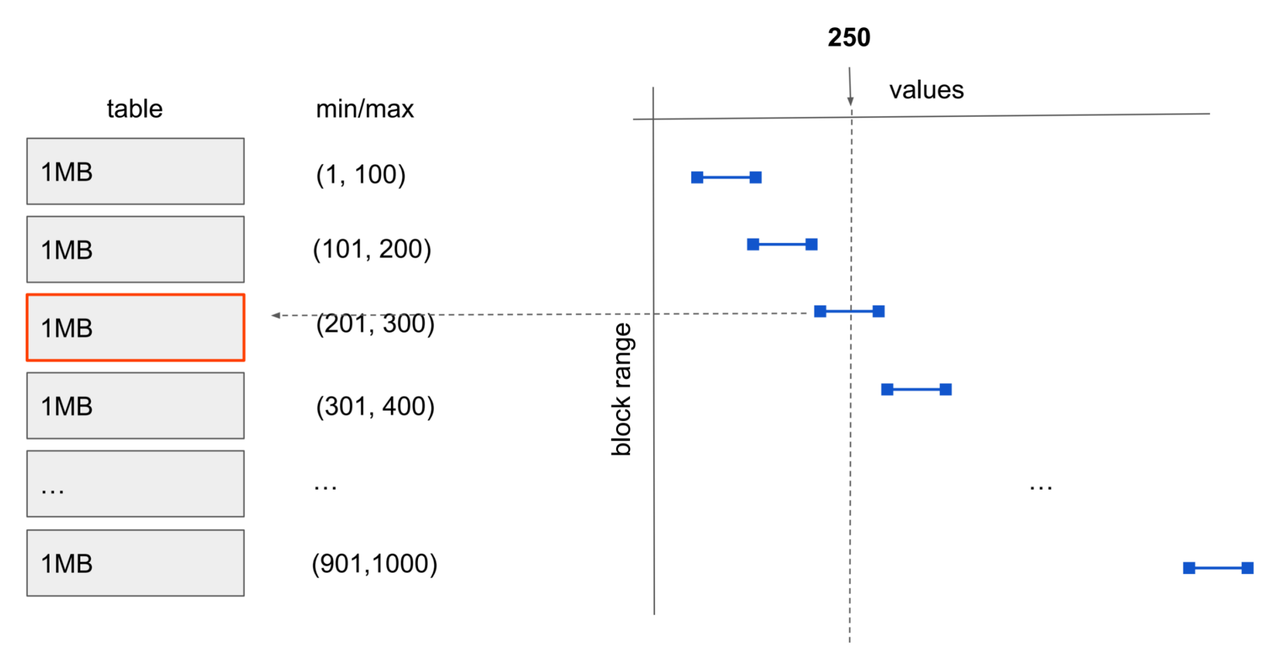
В силу особенностей этой структуры данных основная идея BRIN заключается не в «индексировании каждой строки», а в ведении сводной информации для непрерывных блоков данных. Поэтому BRIN не подходит для данных со случайным физическим распределением, а также для сценариев с высокой частотой обновлений и частых неупорядоченных изменений — в таких случаях эффективность сводится к последовательному сканированию, при котором приходится обрабатывать каждый блок данных.
В YMatrix также поддерживается Default BRIN.
BTREE — это универсальный индекс на основе сбалансированного многоуровневого дерева, который упорядочивает узлы индекса по ключевым значениям и обеспечивает быстрое точное позиционирование отдельных строк или небольших диапазонов данных. Сложность запроса стабильно составляет O(logN). Он поддерживает как запросы на точное совпадение, так и эффективные сканирования по диапазонам и операции сортировки.
Благодаря тому, что он не зависит от физического распределения данных, BTREE обладает высокой стабильностью в сценариях высокопараллельной транзакционной обработки и является предпочтительным типом индекса по умолчанию для первичных ключей, уникальных ограничений и высокоселективных запросов. Однако он не подходит для столбцов с низкой селективностью и широких сканирований по крупным таблицам.
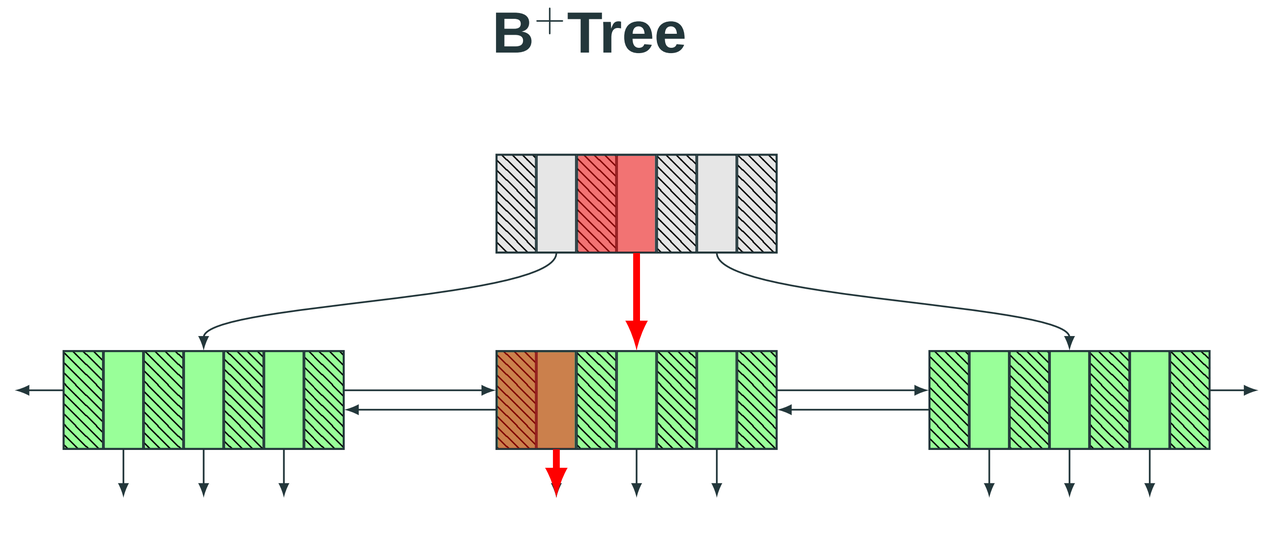
mars3btree — это специализированная реализация B‑дерева для движка хранения MARS3. Внутренние страницы индекса остаются стандартными страницами B‑дерева. mars3btree поддерживает два типа:
NORMAL: стандартное строчное B‑дерево (для RowStore), без сжатия.
COMPRESSED: колоночное сжатое B‑дерево (для ColumnStore), со сжатием.
Для колоночного сжатого BTREE общая архитектура выглядит следующим образом:
Метаданные Min/Max: при построении поддерживаются минимальные и максимальные значения, записываемые в metapage. Их назначение — выполнить глобальную обрезку по условию запроса перед реальным доступом к B‑дереву: фактически добавить сверхлёгкий каталог к индексу. Если условие запроса находится за пределами диапазона Min/Max, сразу делается вывод о невозможности попадания в индекс.
Фильтр Блума: строится только для уникальных индексов и индексов первичного ключа, с ограничением не более 10 миллионов записей. Для запросов на точное совпадение по уникальному/первичному ключу или запросов на проверку существования фильтр Блума позволяет быстро определить невозможность попадания и сократить лишние чтения и распаковки листовых страниц.
Проверка Fast Path: включается только для ColumnStore. При неудаче сразу возвращается nullptr. Проверка превращает оценку целесообразности распаковки листовых страниц в сверхлёгкую операцию (Min/Max + фильтр Блума). При отсутствии попадания распаковка и чтение листовых страниц не выполняются.
Как и в PostgreSQL, в YMatrix операции обновления и удаления не выполняются путем непосредственного изменения исходного пространства данных, а реализуются через механизм множественных версий кортежей:
В MARS3 операции обновления и удаления не используют способ непосредственного изменения данных, а управляют видимостью данных путем маскировки старых данных с помощью файлов DELTA и информации о версиях.
При удалении с помощью оператора DELETE в MARS3 запись производится в файл DELTA соответствующего Run; физическое удаление данных выполняется только во время слияния Run.
При обновлении с помощью оператора UPDATE в MARS3 сначала выполняется удаление исходных данных, а затем повторная вставка новой записи.
В MARS3 ключ сортировки является основным элементом проектирования, от которого зависит эффективность сканирования и долгосрочная стабильность работы движка. Упорядоченные данные в сочетании с надежными метаданными на уровне блоков позволяют значительно повысить эффективность сканирования. При правильном выборе ключа сортировки данные внутри Run и на более высоких уровнях обладают лучшей локальностью, условия фильтрации в запросах с большей вероятностью попадают в непрерывные диапазоны, и пропуск данных работает эффективнее. При неправильном выборе ключа сортировки распределение данных становится более «разбросанным», условия фильтрации не сужают область сканирования, и система ведет себя так, «будто индекс и метаданные есть, но чтение все равно идет как полное сканирование».
Основные преимущества от использования ключа сортировки делятся на пять категорий:
Повышение эффективности фильтрации и запросов по диапазонам: при высокой связи условий WHERE с ключом сортировки (например, диапазоны времени, идентификаторов устройств) данные на слое хранения обладают большей локальностью, запрос может раньше и точнее пропускать нерелевантные блоки данных, сокращая операции ввода-вывода и нагрузку на процессор.
Повышение надежности и эффективности пропуска метаданных: ценность метаданных на уровне блоков (min/max, BRIN и т.д.) зависит от распределения данных. Если внутри одного блока диапазон ключей слишком широкий или данные разбросаны, покрытие min/max становится шире, и пропуск данных работает «осторожнее» (приходится читать больше блоков). Правильный ключ сортировки делает диапазон значений в каждом блоке более компактным, повышая различимость метаданных.
Влияние на фоновое слияние и долгосрочные эксплуатационные затраты: ключ сортировки также влияет на форму Run и эффект слияния. Чем упорядоченнее и компактнее данные, тем правильнее получаются Run после слияния, тем легче сходятся пространство и путь чтения. При неправильном ключе сортировки данные «изначально разбросаны», даже после слияния сложно сформировать хорошую локальность, и долгосрочная эксплуатация требует больше затрат на поддержание производительности.
Влияние на сжатие: сжатие (zstd/lz4, а также RLE, словарное, битовое упаковка) опирается на один ключевой факт: чем регулярнее данные внутри одного блока или stripe, тем лучше сжатие. При группировке данных близких сущностей или близких временных точек внутри одного stripe диапазон значений внутри блока сужается, увеличивается количество повторяющихся и последовательно повторяющихся фрагментов, уменьшается размер словаря, снижается битовая ширина для delta/bitpacking, что улучшает эффективность кодирования и общего сжатия.
Влияние на производительность записи: подробнее см. раздел «Влияние ключа сортировки на производительность записи».
Данные организуются по самым частым и эффективным условиям запросов. На практике ключ сортировки обычно выбирается как комбинация двух измерений:
Измерение времени (Time): почти во всех нагрузках с временными рядами и логами используется фильтрация по диапазону времени.
Измерение сущности (Entity): первичный ключ или часто используемое поле фильтрации для «проверки отдельной сущности» (оборудование, транспорт, пользователь, рабочая станция).
В ключе сортировки столбцы, часто используемые в условиях фильтрации, должны располагаться ближе к началу.
Правило 1: столбец, наиболее часто встречающийся в условиях WHERE, использовать как самый левый префикс ключа сортировки.
Правило 2: столбцы с высокой кардинальностью и высокой селективностью располагать в начале ключа сортировки.
Правило 3: при использовании индекса BRIN чем ближе столбец к началу ключа сортировки, тем важнее его роль — он сильнее влияет на способность индекса пропускать нерелевантные блоки данных.
Проще говоря, наиболее частые условия запроса должны максимально сужать область сканирования до непрерывных, компактных интервалов.
Приведен реальный клиентский случай — сценарий временных рядов. Результаты показывают, что разные ключи сортировки существенно влияют на производительность индексного сканирования по принципу, аналогичному работе составных индексов.
При расположении поля времени на первом месте кортежи с одинаковым ID распределяются по пространству хранения с течением времени. Поэтому индексное сканирование при получении соответствующих блоков данных выполняет большое количество операций случайного чтения.
Однако при расположении ID на первом месте все кортежи, относящиеся к одному ID, хранятся рядом. Это значительно сокращает количество операций случайного ввода-вывода, поскольку индексному сканированию достаточно прочитать небольшое количество непрерывных блоков.
Данные сортируются при преобразовании из RowStore в ColumnStore. Сам RowStore не сортируется. Если на RowStore есть индекс BTREE, он также упорядочен. При указании ключа сортировки:
Требуется вычисление ключа (получение значений столбцов, обработка NULL, возможное преобразование типов/правил сортировки).
Требуется сравнение ключей (сортировка, слияние, вставка в упорядоченную структуру).
Чем больше столбцов в ключе, чем сложнее тип, тем чаще выполняются сравнения.
Без указания ключа сортировки эти операции отсутствуют, поэтому запись обычно происходит легче. Однако ключ сортировки изменяет естественную правильность данных при записи на диск:
При совпадении сортировки с режимом поступления данных формируются более правильные Run и меньше последующих перезаписей — запись стабильнее в долгосрочной перспективе.
При несоответствии сортировки режиму поступления возрастает фоновая нагрузка на ресурсы (чаще и интенсивнее слияние), что конкурирует за ввод-вывод и процессор и замедляет переднюю запись.
CREATE TABLE t_w0_nosort (
id bigint NOT NULL,
k1 bigint NOT NULL, -- высокая кардинальность
k2 smallint NOT NULL, -- низкая кардинальность
k3 bigint NOT NULL, -- монотонный столбец (симуляция инкрементного значения с использованием типа bigint)
v1 double precision NOT NULL,
v2 double precision NOT NULL,
payload text NOT NULL -- Контроль объема записываемых данных: рекомендуется 256 байт / 1024 байт
) USING mars3;
CREATE TABLE t_w1_1key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3);
CREATE TABLE t_w3a_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k1, k3, k2);
CREATE TABLE t_w3b_3key (LIKE t_w0_nosort INCLUDING ALL)
USING mars3
ORDER BY (k3, k1, k2);Формирование промежуточного набора данных
DROP TABLE IF EXISTS t_src_s;
CREATE TABLE t_src_s USING MARS3 AS
SELECT
g AS id,
(hashint8(g)::bigint) AS k1,
(g % 64)::smallint AS k2,
g AS k3,
(g % 1000) * 0.01 AS v1,
(g % 10000) * 0.001 AS v2,
repeat('x', 256) AS payload
FROM generate_series(1, 200000000) g;
TRUNCATE t_w0_nosort;
\timing on
INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w1_1key;
\timing on
INSERT INTO t_w1_1key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3a_3key;
\timing on
INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
\timing off
TRUNCATE t_w3b_3key;
\timing on
INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
\timing offПосле каждого теста база данных перезапускается, и производится сравнение времени записи.
adw=# TRUNCATE t_w0_nosort;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w0_nosort SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 76859.371 ms (01:16.859)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w1_1key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w1_1key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 82864.008 ms (01:22.864)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3a_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3a_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 106929.500 ms (01:46.930)
adw=# \timing off
Timing is off.
adw=# TRUNCATE t_w3b_3key;
TRUNCATE TABLE
adw=# \timing on
Timing is on.
adw=# INSERT INTO t_w3b_3key SELECT * FROM t_src_s;
INSERT 0 200000000
Time: 83456.346 ms (01:23.456)
adw=# \timing off Пропускная способность:
Накладные расходы относительно варианта без сортировки:
Размещение монотонного столбца k3 первым в ключе сортировки практически снижает издержки записи при многостолбцовой сортировке до уровня одностолбцовой.
Первое место высококардинального случайного столбца k1 значительно увеличивает издержки записи.
Отсутствие операций сортировки, сравнения и поддержки упорядоченности → минимальные издержки на запись на переднем плане, поэтому он дает базовую пропускную способность (2,60 млн строк/с).
Поток ввода и так упорядочен по возрастанию k3, ключ сортировки совпадает с порядком ввода → в большинстве случаев запись идет последовательно, добавляются только небольшие издержки на поддержку метаданных, поэтому замедление всего ~8%.
Потому что при сортировке сначала сравнивается k1, а k1 является высококардинальным практически случайным столбцом — это разбивает весь поток записи в пространстве ключей:
Затрудняется использование быстрого пути последовательного добавления / локальной упорядоченности
Значительно увеличивается количество сравнений (многостолбцовые сравнения + почти всегда необходимо сравнивать первый столбец)
Чаще запускаются более тяжелые операции организации данных (буферизация, слияние, поддержка внутренних структур)
Поэтому падение пропускной способности до 1,87 млн строк/с (замедление на 39%) является обоснованным.
Потому что первый столбец сортировки k3 совпадает с потоком ввода, система максимально использует естественную упорядоченность:
Основная часть записи идет последовательно по k3
Столбцы k1/k2 участвуют в более глубоких сравнениями только при совпадении или близости значений k3 (фактическое давление на сравнение / переупорядочивание значительно ниже)
Поэтому производительность почти совпадает с ORDER BY (k3) (2,40 против 2,41 млн строк/с).
adw=# \dt+
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+-------------+-------+---------+---------+---------+-------------
public | t_default | table | mxadmin | mars3 | 160 kB |
public | t_sort_bad | table | mxadmin | mars3 | 103 MB |
public | t_sort_good | table | mxadmin | mars3 | 35 MB |
public | t_src_s | table | mxadmin | mars3 | 3040 MB |
public | t_w0_nosort | table | mxadmin | mars3 | 2769 MB |
public | t_w1_1key | table | mxadmin | mars3 | 2764 MB |
public | t_w3a_3key | table | mxadmin | mars3 | 3453 MB |
public | t_w3b_3key | table | mxadmin | mars3 | 2764 MB |
public | testmars3 | table | mxadmin | mars3 | 160 kB |
(9 rows) Default BRIN — это встроенная функция MARS3, которая автоматически создаёт BRIN-индексы для таблицы без необходимости ручного создания. При этом она не занимает слоты обычных индексов (до 16 индексов остаётся доступным для ручного создания).
| mars3_brin | mars3_default_brin | |
|---|---|---|
| Способ создания | Требует ручного создания | Создается автоматически, без ручных операций |
| Поддержка запросов | Фильтрация данных только при IndexScan | Фильтрация данных при IndexScan и SeqScan |
| Техническая версия | brinV2 | brinV2 |
| Параметризованные запросы | Поддерживает параметризованные запросы (param-IndexScan) | Поддерживает параметризованные запросы (param-SeqScan) |
Пример синтаксиса:
CREATE TABLE t_default(c1 bigint, c2 bigint, c3 bigint)
USING mars3 with (mars3options='default_brinkeys=30');default_brinkeys служит для включения Default BRIN:
-1: система автоматически создает индекс default_brin для всех столбцов, поддерживающих операторы , =;
N: система автоматически создает индекс default_brin для первых N столбцов, поддерживающих операторы , =.
postgres=# \d+ t_default
Table "public.t_default"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+--------+-----------+----------+---------+---------+--------------+-------------
c1 | bigint | | | | plain | |
c2 | bigint | | | | plain | |
c3 | bigint | | | | plain | |
Distributed by: (c1)
Access method: mars3
Options: mars3options=default_brinkeys=30, compresslevel=1, compresstype=zstd Мы можем использовать UDF для проверки того, для каких столбцов создан Default BRIN.
CREATE FUNCTION matrixts_internal.mars3_brinkeys (IN r1 regclass, OUT nbrinkeys int, OUT brinkeys text)
RETURNS SETOF RECORD
AS '$ libdir / matrixts;', 'mars3_brinkeys'
LANGUAGE C
VOLATILE PARALLEL UNSAFE STRICT EXECUTE ON ALL SEGMENTS;
postgres=# select * from matrixts_internal.mars3_brinkeys('t_default'::regclass);
nbrinkeys | brinkeys
-----------+------------
3 | (c1,c2,c3)
3 | (c1,c2,c3)
3 | (c1,c2,c3)
3 | (c1,c2,c3)
(4 rows)