
Для адаптации к различным сценариям в YMatrix предусмотрены три режима записи, которые определяются совместно табличными параметрами prefer_load_mode и rowstore_size.
Процесс записи в различных режимах
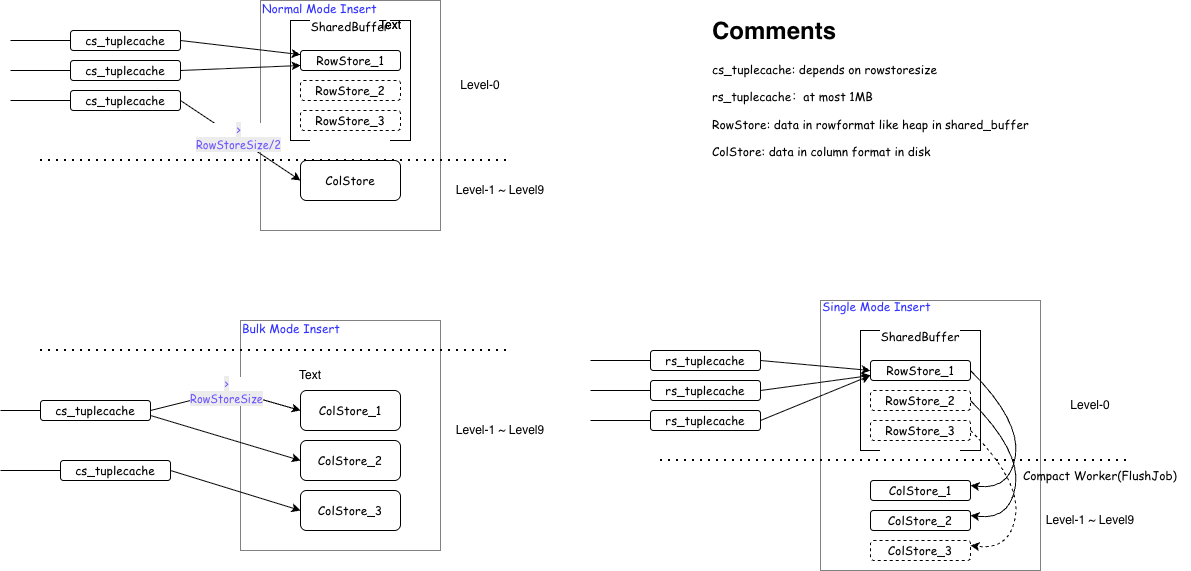
В режиме Single данные накапливаются в локальной памяти до объёма 1 МБ, после чего напрямую записываются в строкувое хранилище (rowstore). Процесс аналогичен традиционной записи в структуру Heap в PostgreSQL: данные размещаются непосредственно в Shared Buffers.
Стратегия вытеснения в Shared Buffers
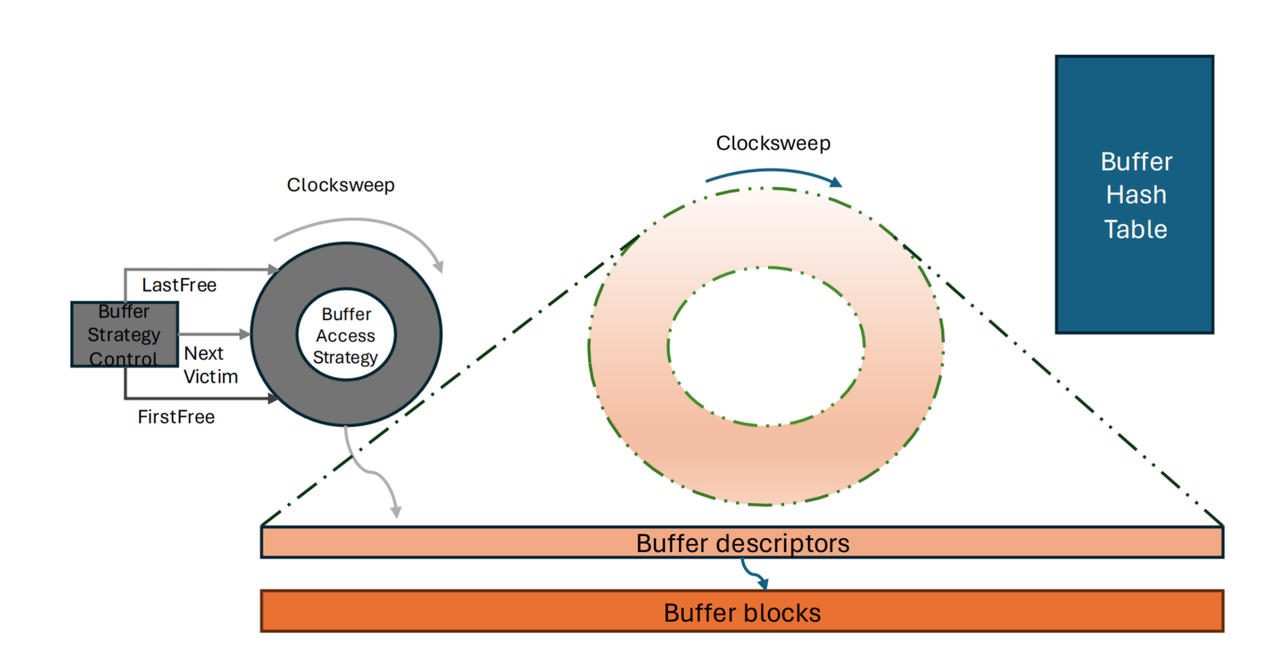
Преимущества: минимальная задержка вставки, низкое потребление памяти.
Недостатки:
При массовой загрузке требуется дополнительный этап слияния.
Если данные долго не переводятся в колоночное хранилище, размер таблицы визуально завышен.
Эффективность аналитических запросов (AP) и индексов BRIN ниже, чем у columnstore.
Отсутствие сжатия приводит к увеличению объёма данных и логов WAL в несколько раз.
В режиме Bulk данные сначала копируются в локальную память до достижения размера rowstore_size, затем сразу преобразуются в колоночное хранилище и сбрасываются на диск. По завершении вставки данные, не достигшие порога, также преобразуются и записываются на диск.
Преимущества:
Сжатие данных снижает нагрузку на диск и I/O.
Высокая эффективность аналитических запросов и BRIN.
Отсутствие дополнительного этапа преобразования, ниже write amplification.
Недостатки:
Потребление памяти значительно выше, чем у rowstore.
Задержка одиночной вставки выше, чем в режиме Single.
Умный режим вставки. Данные копируются в локальную память. При достижении размера rowstore_size они напрямую преобразуются в columnstore и сбрасываются на диск. Если по окончании вставки объем данных в локальной памяти не достигает значения (rowstore_size / 2), они записываются в текущий rowstore; в противном случае преобразуются в columnstore и сбрасываются на диск. Режим по умолчанию — normal.
Одиночная вставка (single insert)
| Тип теста | Количество транзакций на клиент | Количество клиентов | Количество потоков | Средняя задержка (мс) | TPS (включая подключение) | TPS (не включая подключение) |
|---|---|---|---|---|---|---|
| single_insert.sql | 100 000 | 1 | 1 | 1.98 | 505.03 | 505.06 |
| bulk_insert.sql | 100 000 | 1 | 1 | 15.282 | 65.44 | 65.44 |
| normal_insert.sql | 100 000 | 1 | 1 | 1.968 | 508.02 | 508.05 |
Малая пакетная вставка
| Режим | Общее время выполнения | Общее количество секунд (с) | Количество строк в секунду (строк/с) |
|---|---|---|---|
| single | 2 мин 27 с | 147 | ≈ 680 |
| normal | 2 мин 28 с | 148 | ≈ 676 |
| bulk | 4 мин 55 с | 295 | ≈ 339 |
Массовая загрузка (COPY из CSV)
| Режим | Количество строк | Время выполнения (секунд) |
|---|---|---|
| bulk | 50 000 000 | 69.287 |
| single | 50 000 000 | 50.868 |
| normal | 50 000 000 | 70.612 |
Сравнение MARS3 Single с Heap
Сжатие достигает примерно 10 раз, производительность TPS ниже, чем у Heap, примерно на 25%.
| Имя таблицы | Коэффициент сжатия | Экономия хранилища |
|---|---|---|
| fi_voucher | 7:01 | 86% |
| fi_voucher_b | 15:01 | 93% |
| aai_voucher | 4,5:1 | 78% |
| aai_voucher_record | 8,9:1 | 89% |
При вставке одинакового объёма данных скорость генерации WAL совпадает, но общий объём логов в MARS3 составляет примерно 1/3 от объёма для Heap, что существенно экономит место на диске.
Поскольку сжатие в формате Range использует переменную длину данных, невозможно применить готовый механизм Shared Buffers. Поэтому был разработан кэш только для чтения, поддерживающий данные переменной длины. Он предназначен для обработки запросов, поступающих по пути сканирования индекса — такие запросы чувствительны к задержке. С помощью кэширования мы снижаем эффект увеличения объема чтения (read amplification), возникающий при работе с колоночным хранилищем. При этом в кэше хранится формат, оптимизированный для сканирования индекса: скан точно знает, какой кортеж требуется, поэтому формат кэша и механизм чтения позволяют быстро найти нужную строку.
Для движка MARS3 реализован кэш, аналогичный Shared Buffers, называемый varbuffer. Varbuffer в основном используется для оптимизации сканирования индексов. Поскольку в columnstore все данные записываются и считываются напрямую, varbuffer кэширует распакованные данные stripe. На диске при этом хранятся только сжатые блоки. Если в рабочей нагрузке преобладает сканирование индексов, данный параметр можно настроить под конкретные условия (требуется перезапуск системы).
① Сначала проверяется varbuffer
Попадание → напрямую используется распакованный stripe (отображается как stripe до сжатия)
② Промах → выполняется buffer io
↓
Попадание в OS cache?
Да → получен сжатый stripe (без дискового IO)
Нет → реальное чтение с диска
③ Получен сжатый stripe
→ распаковка
→ помещение в varbufferpostgres=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
1GB
(1 row)Согласно теоретическим оценкам, чем больше размер varbuffer, тем выше эффективность сканирования индексов, при этом влияние на последовательное сканирование менее существенное. Также необходимо учитывать влияние OS cache: перед каждым тестом следует очистить OS cache и перезапустить базу данных.
Формирование набора данных
CREATE TABLE t_m3 (
id bigint,
ts timestamptz,
v double precision,
pad int
)
USING MARS3
DISTRIBUTED BY (id);
INSERT INTO t_m3
SELECT
(g % 1000000)::bigint AS id,
'2026-01-01'::timestamptz + (g || ' seconds')::interval AS ts,
(random()*1000)::float8 AS v,
(g % 1000)::int AS pad
FROM generate_series(1, 20000000) g;
ANALYZE t_m3;
CREATE INDEX idx_t_m3_id_ts ON t_m3 (id, ts);
ANALYZE t_m3;Проверка результатов
adw=# show mx_varbuffer_size;
mx_varbuffer_size
-------------------
64MB
(1 row)
adw=# \q
[mxadmin@sdw ~]$ /usr/bin/time -f "pass1: %e s" bash -c '
> for i in $(seq 1 20000); do
> psql -X -qAt -c "SELECT v FROM t_m3 WHERE id=$i AND ts='\''2026-01-02 00:00:00+00'\'';" >/dev/null
> done'
pass1: 238.07 s
adw=# show mx_varbuffer_size;
mx_varbuffer_size
-------------------
1GB
(1 row)
adw=# \q
[mxadmin@sdw ~]$ /usr/bin/time -f "pass2: %e s" bash -c '
> for i in $(seq 1 20000); do
> psql -X -qAt -c "SELECT v FROM t_m3 WHERE id=$i AND ts='\''2026-01-02 00:00:00+00'\'';" >/dev/null
> done'
pass2: 238.72 s
adw=# select * from t_m3 where ts = '2026-01-02 00:00:00+00';
id | ts | v | pad
--------+------------------------+-------------------+-----
115200 | 2026-01-02 08:00:00+08 | 681.0068987279756 | 200
(1 row)Поскольку каждый запрос возвращает не более 0–1 строк и практически не происходит повторного использования stripe, не формируется рабочий набор, пригодный для кэширования, поэтому разница между двумя вариантами незначительна.
Перепроектирование должно удовлетворять 4 условиям:
Стабильное срабатывание сканирования индексов
За один запрос возвращается средний объем данных
Повторяющиеся запросы многократно попадают в одну и ту же партию stripe, формируя горячую область
Размер горячего рабочего набора находится в диапазоне между 64MB и 1GB
Из-за влияния OS cache перед каждой проверкой необходимо выполнить очистку OS cache командой echo 3 > /proc/sys/vm/drop_caches и перезапустить базу данных
Вывод теста: При условиях холодного запуска (с очисткой OS page cache и перезапуском базы данных) при выполнении 1000 агрегированных запросов MxVIndexScan на одном и том же горячем окне увеличение параметра mx_varbuffer_size с 64MB до 1GB снизило общее время выполнения с 87.986 с до 17.514 с (примерно 5.02-кратное ускорение, снижение времени выполнения на 80.1%). Данный результат показывает, что объем varbuffer играет определяющую роль в повторном использовании распакованных колонковых данных при сканировании индексов в MARS3; при недостаточном объеме возникают значительные накладные расходы на повторную распаковку и вытеснение из кэша.
DROP TABLE IF EXISTS t_m3_vb_test;
CREATE TABLE t_m3_vb_test (
device_id int, -- один из ключевых столбцов запроса (высокая кардинальность)
ts timestamptz, -- временной измерение (второй столбец индекса)
metric_id smallint, -- идентификатор метрики (низкая кардинальность)
v1 double precision, -- часто используемый числовой столбец
v2 double precision, -- часто используемый числовой столбец
v3 double precision, -- часто используемый числовой столбец
status int, -- столбец состояния (низкая кардинальность)
tag int -- заполнительный столбец (увеличивает размер рабочего набора)
)
USING MARS3
DISTRIBUTED BY (device_id);
CREATE INDEX idx_t_m3_vb_test_dev_ts ON t_m3_vb_test (device_id, ts);
ANALYZE t_m3_vb_test;
-- Около 30 миллионов записей
INSERT INTO t_m3_vb_test
SELECT
d.device_id,
t.ts,
m.metric_id,
(random() * 1000)::float8 AS v1,
(random() * 1000)::float8 AS v2,
(random() * 1000)::float8 AS v3,
(random() * 10)::int AS status,
(random() * 100000)::int AS tag
FROM generate_series(1, 100) AS d(device_id)
CROSS JOIN generate_series(
'2026-01-01 00:00:00+00'::timestamptz,
'2026-01-01 23:59:59+00'::timestamptz,
'1 second'::interval
) AS t(ts)
CROSS JOIN generate_series(1, 4) AS m(metric_id);64 MB varbuffer
При каждом выполнении index scan происходит многократный доступ к одним и тем же stripe / range. Объем varbuffer недостаточен для размещения распакованных колонковых данных, относящихся к данному горячему окну, поэтому на каждой итерации возникает большое количество:
Повторных чтений stripe
Повторных распаковок
Повторного формирования исполнительных пакетов
Это приводит к увеличению нагрузки на процессор и память.
adw=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
64MB
(1 row)
adw=# set enable_seqscan to off;
SET
adw=# set enable_bitmapscan to off;
SET
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts < '2026-01-01 14:00:00+00';
END LOOP;
END$$;
DO
Time: 87986.026 ms (01:27.986)1 GB varbuffer
При размере varbuffer 1GB:
Распакованные колонковые данные, относящиеся к горячему окну, с высокой вероятностью могут длительное время храниться в varbuffer
Первый выполненный запрос осуществляет прогрев кэша
Последующие 999 запросов в основном попадают в varbuffer
Исключаются повторная распаковка и повторная подготовка колонковых пакетов
Поэтому общее время выполнения значительно снижается.
adw=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
1GB
(1 row)
adw=# set enable_seqscan to off;
SET
adw=# set enable_bitmapscan to off;
SET
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts < '2026-01-01 14:00:00+00';
END LOOP;
END$$;
DO
Time: 17514.349 ms (00:17.514)В предыдущих тестах мы вручную устанавливали параметры enable_seqscan и enable_bitmapscan, чтобы принудительно использовать сканирование по индексу. В этой проверке параметры не устанавливаются, и оценивается влияние varbuffer на последовательное сканирование. Результаты теста показывают, что разница практически отсутствует.
varbuffer в основном оптимизирует случайный/горячий доступ через индексы, а не основной путь последовательного сканирования.
64 MB varbuffer
adw=# set enable_bitmapscan to off;
SET
adw=# set enable_indexscan to off;
SET
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts < '2026-01-01 14:00:00+00';
END LOOP;
END$$;
DO
Time: 29928.241 ms (00:29.928)1 GB varbuffer
adw=# set enable_bitmapscan to off;
SET
adw=# set enable_indexscan to off;
SET
adw=# show mx_varbuffer_size ;
mx_varbuffer_size
-------------------
1GB
(1 row)
adw=# \timing on
Timing is on.
adw=# DO $$
DECLARE i int;
DECLARE s1 float8;
DECLARE s2 float8;
DECLARE s3 float8;
BEGIN
FOR i IN 1..1000 LOOP
SELECT sum(v1), avg(v2), max(v3)
INTO s1, s2, s3
FROM t_m3_vb_test
WHERE device_id = 42
AND ts >= '2026-01-01 10:00:00+00'
AND ts < '2026-01-01 14:00:00+00';
END LOOP;
END$$;
DO
Time: 28216.994 ms (00:28.217)Каждые compress_threshold строк (по умолчанию 1200) мы называем один Range; данные одного столбца в пределах одного Range (включая compress_threshold строк) называются stripe; если данные этого столбца слишком большие, то stripe разбивается на несколько блоков по 1 МБ, и при чтении не считывается сразу весь объем данных на compress_threshold строк. Более подробные детали см. в разделе Range и Stripe.
compress_threshold также оказывает определенное влияние на степень сжатия: при увеличении объема данных, сжимаемых за одну партию, эффект сжатия может быть лучше. Принцип заключается в том, что повторяющиеся данные сжимаются более эффективно, чем если бы они находились в двух разных партиях и не были сжаты вместе.
| id | compress_threshhold=1200 | 3600 | 10000 | 50000 |
|---|---|---|---|---|
| 1 | 8.8032 | 7.7846 | 6.6471 | 6.6824 |
| 2 | 0.981 | 0.997 | 2.2284 | 2.2322 |
| 3 | 3.3512 | 3.3143 | 3.3184 | 3.3177 |
| 4 | 7.7059 | 7.7326 | 6.6034 | 5.5994 |
| 5 | 5.5732 | 5.5042 | 5.5939 | 6.633 |
| 6 | 0.478 | 0.38 | 0.545 | 0.545 |
| 7 | 1.1908 | 1.1917 | 2.2172 | 2.2222 |
| 8 | 3.3602 | 3.3129 | 3.3018 | 3.3227 |
| 9 | 8.8429 | 7.74 | 7.7751 | 7.7795 |
| 10 | 3.3835 | 4.4239 | 5.5496 | 5.5499 |
| 11 | 0.845 | 0.743 | 2.2307 | 2.2299 |
| 12 | 1.1998 | 1.1887 | 2.2164 | 2.2138 |
| 13 | 6.6514 | 6.6351 | 6.6784 | 6.6424 |
| 14 | 0.837 | 0.776 | 1.1364 | 1.1275 |
| 15 | 1.1436 | 1.1359 | 1.183 | 1.1783 |
| 16 | 1.1768 | 1.1787 | 2.2673 | 2.2757 |
| 17 | 9.9419 | 8.8705 | 8.8922 | 8.8771 |
| 18 | 11.11337 | 11.11522 | 10.10384 | 10.10647 |
| 19 | 4.4792 | 3.3942 | 4.4918 | 4.467 |
| 20 | 2.2668 | 2.2389 | 3.3475 | 3.3346 |
| 21 | 11.11391 | 10.10633 | 11.1119 | 10.10742 |
| 22 | 3.3009 | 2.2864 | 3.372 | 3.3377 |
| sum | 97.73958 | 92.05015 | 100.81134 | 99.78189 |
| Тестовый сценарий | compress_threshold | 1200 | 3600 | 10000 | 50000 |
|---|---|---|---|---|---|
| Производительность записи | Партиционированная таблица (строк/с) | 852334 | 919031 | 1055371 | 1057424 |
| Производительность записи | Непартиционированная таблица (строк/с) | 991463 | 1033751 | 1054292 | 1076714 |
| Производительность запросов | time_bucket=1h (диапазон 1 день) | 357 мс | 342 мс | 333 мс | 324 мс |
| Производительность запросов | time_bucket=1d (диапазон 1 месяц) | 7384 мс | 6312 мс | 6008 мс | 6025 мс |
| Производительность запросов | time_bucket=30d (диапазон 1 год) | 94278 мс | 75101 мс | 68184 мс | 69006 мс |
| Производительность запросов | Точечный запрос | 19.416 мс | 20.043 мс | 23.692 мс | 37.844 мс |
CREATE INDEX idx_name ON table_name
USING mars3btree (column_list)
WITH (
compresstype = 'lz4',
compresslevel = 1,
compressctid = true,
minmax = true
);compresstype: lz4 (быстрое сжатие/распаковка), zstd (высокая степень сжатия).
compresslevel: 1–9 (1 — скорость, 6–9 — степень сжатия).
compressctid: сжатие столбца CTID (рекомендовано включать).
В сценарии работы одного из клиентов после включения сжатия индексов:
На кластере TOB влияние оказалось незначительным: нагрузка на CPU и память узлов практически не изменилась, при этом удалось сэкономить 24% места в разделах Ymatrix. На кластере TOC эффект оказался выраженным: за счет некоторого увеличения нагрузки на CPU и память удалось сэкономить 63% места в разделах Ymatrix. При запросе GPS‑данных за 1 день по 50 автомобилям пропускная способность сервиса с включенным сжатием индексов в 3,3 раза выше, чем без сжатия.При запросе GPS‑данных за 3 дня по 50 автомобилям пропускная способность сервиса с включенным сжатием индексов в 1,1 раза выше, чем без сжатия.
Как уже упоминалось ранее, сжатие (будь то алгоритмы zstd/lz4 или кодирования RLE/dict/bitpack) опирается на ключевой факт: чем более регулярными являются данные внутри одного блока или одного stripe, тем выше эффективность сжатия. Методы lz4/zstd полагаются на повторяющиеся подстроки и повторяющиеся паттерны. После сортировки комбинации полей внутри одного блока становятся более похожими, особенно в широких таблицах. Когда данные близких сущностей или близких моментов времени сгруппированы в одном stripe, диапазон значений внутри блока сужается, усиливаются повторения и последовательные повторения, уменьшается размер словаря, а также снижается разрядность (bit‑ширина) при использовании delta/bitpacking.
Всё это повышает эффективность кодирования и универсального сжатия.
adw=# CREATE TABLE t_sort_good (
device_id int NOT NULL,
ts timestamptz NOT NULL,
site_id int NOT NULL,
status smallint NOT NULL,
v1 double precision NOT NULL,
v2 double precision NOT NULL,
attrs jsonb NOT NULL
)
USING MARS3
WITH (compresstype=zstd,compresslevel=3,mars3options='prefer_load_mode=bulk')
ORDER BY (device_id, ts);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'device_id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE
adw=# CREATE TABLE t_sort_bad (
device_id int NOT NULL,
ts timestamptz NOT NULL,
site_id int NOT NULL,
status smallint NOT NULL,
v1 double precision NOT NULL,
v2 double precision NOT NULL,
attrs jsonb NOT NULL
)
USING MARS3
WITH (compresstype=zstd,compresslevel=3,mars3options='prefer_load_mode=bulk')
ORDER BY (ts, device_id);
NOTICE: Table doesn't have 'DISTRIBUTED BY' clause -- Using column named 'device_id' as the Greenplum Database data distribution key for this table.
HINT: The 'DISTRIBUTED BY' clause determines the distribution of data. Make sure column(s) chosen are the optimal data distribution key to minimize skew.
CREATE TABLE Затем генерируется исходный источник данных, и данные одновременно вставляются в обе таблицы.
DROP TABLE IF EXISTS t_src;
CREATE UNLOGGED TABLE t_src AS
WITH
dev AS (
SELECT d AS device_id,
(d % 200) AS site_id,
(1000 + (d % 500))::double precision AS base
FROM generate_series(1, 10000) AS d
),
pts AS (
SELECT device_id, site_id, base,
g AS seq,
(timestamp '2026-01-01' + (g || ' seconds')::interval) AS ts
FROM dev
CROSS JOIN generate_series(1, 1000) AS g
)
SELECT
device_id,
ts,
site_id,
-- status: изменение каждые 300 секунд, формирование длинного сегмента
((seq / 300) % 4)::smallint AS status,
-- v1/v2: базовое значение устройства + небольшие колебания
(base + (seq % 10) * 0.1)::double precision AS v1,
(base * 0.1 + (seq % 20) * 0.01)::double precision AS v2,
-- attrs: ключи имеют схожие шаблоны, значения изменяются по устройству/времени
jsonb_build_object(
'fw', '1.2.' || (device_id % 10),
'model', 'm' || (device_id % 50),
'tag', 'S' || site_id,
'k', seq % 5
) AS attrs
FROM pts;
INSERT INTO t_sort_good SELECT * FROM t_src;
INSERT INTO t_sort_bad SELECT * FROM t_src;Для обеспечения точности данных после завершения вставки выполняются несколько команд VACUUM FULL + VACUUM.
adw=# select segid,level,total_nruns,visible_nruns,invisible_nruns,level_size from matrixts_internal.mars3_level_stats('t_sort_good') where level_size '0 bytes';
segid | level | total_nruns | visible_nruns | invisible_nruns | level_size
-------+-------+-------------+---------------+-----------------+------------
0 | 1 | 1 | 1 | 0 | 8839 kB
1 | 1 | 1 | 1 | 0 | 8933 kB
3 | 1 | 1 | 1 | 0 | 8552 kB
2 | 1 | 1 | 1 | 0 | 8728 kB
(4 rows)
adw=# select segid,level,total_nruns,visible_nruns,invisible_nruns,level_size from matrixts_internal.mars3_level_stats('t_sort_bad') where level_size '0 bytes';
segid | level | total_nruns | visible_nruns | invisible_nruns | level_size
-------+-------+-------------+---------------+-----------------+------------
0 | 2 | 1 | 1 | 0 | 26 MB
1 | 2 | 1 | 1 | 0 | 26 MB
3 | 2 | 1 | 1 | 0 | 25 MB
2 | 2 | 1 | 1 | 0 | 25 MB
(4 rows)
adw=# \dt+ t_sort_bad
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+------------+-------+---------+---------+--------+-------------
public | t_sort_bad | table | mxadmin | mars3 | 103 MB |
(1 row)
adw=# \dt+ t_sort_good
List of relations
Schema | Name | Type | Owner | Storage | Size | Description
--------+-------------+-------+---------+---------+-------+-------------
public | t_sort_good | table | mxadmin | mars3 | 35 MB |
(1 row)
adw=# select * from t_sort_good limit 10;
device_id | ts | site_id | status | v1 | v2 | attrs
-----------+------------------------+---------+--------+--------+--------------------+-----------------------------------------------------
3 | 2026-01-01 00:00:01+08 | 3 | 0 | 1003.1 | 100.31000000000002 | {"k": 1, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:02+08 | 3 | 0 | 1003.2 | 100.32000000000001 | {"k": 2, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:03+08 | 3 | 0 | 1003.3 | 100.33000000000001 | {"k": 3, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:04+08 | 3 | 0 | 1003.4 | 100.34000000000002 | {"k": 4, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:05+08 | 3 | 0 | 1003.5 | 100.35000000000001 | {"k": 0, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:06+08 | 3 | 0 | 1003.6 | 100.36000000000001 | {"k": 1, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:07+08 | 3 | 0 | 1003.7 | 100.37 | {"k": 2, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:08+08 | 3 | 0 | 1003.8 | 100.38000000000001 | {"k": 3, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:09+08 | 3 | 0 | 1003.9 | 100.39000000000001 | {"k": 4, "fw": "1.2.3", "tag": "S3", "model": "m3"}
3 | 2026-01-01 00:00:10+08 | 3 | 0 | 1003 | 100.4 | {"k": 0, "fw": "1.2.3", "tag": "S3", "model": "m3"}
(10 rows)
adw=# select * from t_sort_bad limit 10;
device_id | ts | site_id | status | v1 | v2 | attrs
-----------+------------------------+---------+--------+--------+--------------------+-------------------------------------------------------
1 | 2026-01-01 00:00:01+08 | 1 | 0 | 1001.1 | 100.11000000000001 | {"k": 1, "fw": "1.2.1", "tag": "S1", "model": "m1"}
12 | 2026-01-01 00:00:01+08 | 12 | 0 | 1012.1 | 101.21000000000001 | {"k": 1, "fw": "1.2.2", "tag": "S12", "model": "m12"}
15 | 2026-01-01 00:00:01+08 | 15 | 0 | 1015.1 | 101.51 | {"k": 1, "fw": "1.2.5", "tag": "S15", "model": "m15"}
20 | 2026-01-01 00:00:01+08 | 20 | 0 | 1020.1 | 102.01 | {"k": 1, "fw": "1.2.0", "tag": "S20", "model": "m20"}
23 | 2026-01-01 00:00:01+08 | 23 | 0 | 1023.1 | 102.31000000000002 | {"k": 1, "fw": "1.2.3", "tag": "S23", "model": "m23"}
35 | 2026-01-01 00:00:01+08 | 35 | 0 | 1035.1 | 103.51 | {"k": 1, "fw": "1.2.5", "tag": "S35", "model": "m35"}
38 | 2026-01-01 00:00:01+08 | 38 | 0 | 1038.1 | 103.81000000000002 | {"k": 1, "fw": "1.2.8", "tag": "S38", "model": "m38"}
40 | 2026-01-01 00:00:01+08 | 40 | 0 | 1040.1 | 104.01 | {"k": 1, "fw": "1.2.0", "tag": "S40", "model": "m40"}
44 | 2026-01-01 00:00:01+08 | 44 | 0 | 1044.1 | 104.41000000000001 | {"k": 1, "fw": "1.2.4", "tag": "S44", "model": "m44"}
47 | 2026-01-01 00:00:01+08 | 47 | 0 | 1047.1 | 104.71000000000001 | {"k": 1, "fw": "1.2.7", "tag": "S47", "model": "m47"}
(10 rows) Проще говоря:
В таблице t_sort_good похожие данные сгруппированы вместе, поэтому данные, записанные на диск одной партией, более упорядочены и повторяющиеся, и компрессору легче работать. В таблице t_sort_bad совершенно разные данные смешаны вместе, поэтому каждая партия на диске получается разнородной и случайной, и компрессору сложно сжимать.
Одинаковый объем данных, отличается только ключ сортировки:
Общий размер t_sort_good: 35 МБ
Общий размер t_sort_bad: 103 МБ (примерно в 3 раза больше)
По статистике run/level: каждый сегмент содержит только один run, но:
У t_sort_good run находится на уровне 1, размер каждого seg: около 8.5–8.9 МБ
У t_sort_bad run находится на уровне 2, размер каждого seg: около 25–26 МБ
Для t_sort_good сортировка по (device_id, ts) → группировка похожих данных → благоприятно для сжатия.
В пределах одного stripe/блока находятся данные «одного устройства за непрерывный период времени».
Это дает:
Длинные повторяющиеся сегменты в столбцах device_id, site_id, status (отлично подходит для RLE/словарного кодирования)
Малые приращения внутри блока для столбцов ts, v1, v2 (изменяются медленно во времени, отлично подходит для delta/bitpacking)
Высокая схожесть шаблонов ключей в attrs (jsonb) внутри одного устройства (также благоприятно для zstd/lz4)
Поэтому при одинаковом количестве строк физический размер значительно меньше.
Для t_sort_bad сортировка по (ts, device_id) → смешение разных устройств → неблагоприятно для сжатия.
В один момент времени попадают данные множества устройств, поэтому внутри одного блока:
device_id меняется почти в каждой строке (словарь больше, длина RLE‑сегментов близка к 1)
site_id и status также разрознены (run‑length нарушен)
Шаблоны в attrs более разнообразные (уменьшается число повторяющихся фрагментов)
Даже при возрастающем ts «случайность» других столбцов сводит на нет общую выгоду от сжатия
Поэтому коэффициент сжатия значительно ухудшается, а увеличение физического размера в 3 раза является нормальным.
Другими словами: плохая сортировка не только увеличивает размер, но и усложняет обслуживание — данные стабилизируются только на верхних уровнях.
В MARS3 ключ сортировки определяет степень схожести данных внутри блоков записи (run/stripe). При группировке похожих данных диапазон значений внутри блока сужается, повторы концентрируются, и все механизмы: словарное кодирование, RLE, delta, а также универсальное сжатие — работают максимально эффективно, обеспечивая меньший физический объем. Напротив, при смешении данных из-за неверного ключа сортировки распределение внутри блока становится разрозненным, повторы разбиваются, эффективность сжатия и кодирования резко падает, что даже увеличивает сложность и стоимость фоновой обработки.
Unique Mode — это режим, предоставляемый MARS3 для специфических моделей записи: он преобразует задачу «обновить запись» в «повторную вставку новой записи по уникальному ключу», а движок автоматически выполняет замену старой и новой версии для одного и того же ключевого значения. Основная ценность этого режима — позволить бизнесу использовать более простой и унифицированный способ записи (INSERT) для выражения семантики обновления в сценариях с высокочастотной записью, сократить использование и затраты явного оператора UPDATE, а также сохранить управляемость организации данных при непрерывной записи.
Сценарии применения:
Непрерывная запись последнего состояния по ключу сущности: сильное измерение сущностей (устройства, транспортные средства, пользователи, заказы), повторная запись последнего значения по одному ключу
Высокочастотная запись малыми партиями: потребность в простом, стабильном и устойчивом пути записи
Запросы в основном на последние значения/последние снимки: например, панели последнего состояния, статусы оповещений, панели последних метрик
Отсутствие необходимости в семантике физического удаления: бизнесу не требуется частый DELETE (или недействительность/истечение срока действия можно выразить другими способами)
В режиме Unique Mode уникальный ключ определяется ключом сортировки ORDER BY (...) при создании таблицы: при вставке новых данных с тем же уникальным ключом, что и у существующей записи, движок воспринимает это как обновление данных по этому ключу — достаточно выполнить простой INSERT без явного UPDATE. В отличие от традиционного upsert (insert .. on conflict), Unique Mode выполняет слияние при чтении: данные записываются в хранилище при вставке, а при чтении гарантируется получение актуальной версии через цепочку версий и правила видимости, дубликаты удаляются при компактации. Upsert же выполняет слияние при записи: при вставке сразу проверяется возможное повторение, что приводит к дополнительным затратам на запись.
Такая предварительная проверка позволяет избежать затрат на вставку кортежа в кучу с последующим удалением при его дублировании. HEAP_INSERT_IS_SPECULATIVE — так называемая спекулятивная вставка: при обнаружении конфликта она отменяется без отмены всей транзакции. Другие сеансы могут ожидать подтверждения спекулятивной вставки (превращения в обычный кортеж) или её отмены.
Поэтому производительность записи в Unique Mode значительно выше, чем у традиционного upsert: по результатам тестов она примерно в 1,5 раза выше.
При повторной записи по одному ключу в режиме Unique Mode скалярные столбцы по умолчанию перезаписываются новыми значениями. Но для столбцов типа JSONB движок поддерживает семантику инкрементного слияния: новая версия JSONB не записывается напрямую, а формируется по правилу:
postgres=# SELECT jsonb_concat('[1,2]'::jsonb, '[2,3]'::jsonb);
jsonb_concat
--------------
[1, 2, 2, 3]
(1 row)
postgres=# SELECT jsonb_concat('{"k":1,"x":2}'::jsonb, '{"k":null}'::jsonb);
jsonb_concat
---------------------
{"k": null, "x": 2}
(1 row)
postgres=# SELECT jsonb_concat('{"a":1,"b":2}'::jsonb, '{"b":99,"c":3}'::jsonb);
jsonb_concat
---------------------------
{"a": 1, "b": 99, "c": 3}
(1 row) new_jsonb = jsonb_concat(old_jsonb, incoming_jsonb)
База данных внутри вызывает функцию jsonb_concat для выполнения слияния.
Это позволяет бизнесу записывать только инкрементный JSONB при работе с динамическими атрибутами, расширениями или тегами, а слияние выполняет движок — исключается дополнительная сложность и конкурентные конфликты при чтении старого значения, слиянии и записи обратно на уровне приложения.
Риск идемпотентности при слиянии массивов: добавление элементов в JSONB-массив без дедубликации может привести к накоплению повторяющихся элементов при повторных попытках записи. Рекомендуется избегать долгосрочного добавления деталей событий в массив; при необходимости идемпотентности введите event_id и гарантируйте уникальность на верхнем уровне, либо используйте структуру object/map с перезаписью по ключу.
Управление ростом JSONB: слияние JSONB постепенно увеличивает размер полей, что может повысить затраты на чтение и нагрузку на фоновое обслуживание. Рекомендуется выполнять управление объёмом JSONB (обрезка, разделение таблиц, сегментация, хранение только последних N записей).
Null не равно удалению: запись {"k": null} устанавливает значение k в null, но не удаляет ключ. Для семантики удаления требуется отдельная схема (например, специальное поле-маркер, отдельная таблица удалений, договоренность на бизнес-уровне).
Назначение UpdateChain — обеспечить корректность при конкурентном обновлении одной строки. В PG Heap обновление не изменяет строку на месте: старый кортеж помечается как удаленный, вставляется новый, а по ctid старая версия связывается с новой, образуя цепочку обновлений.
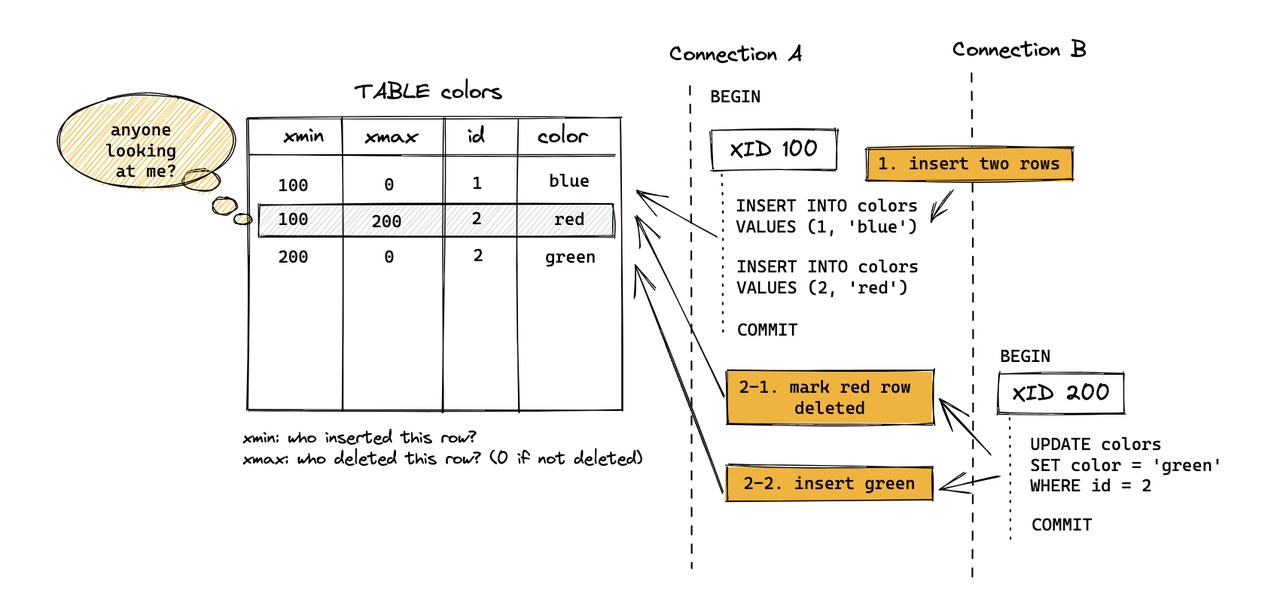
В MARS3 удаление/обновление не записывает xmax в заголовок кортежа, как в Heap: аналогичные метки «удаление/обновление» записываются в файл Delta. Кроме того, для сохранения этих данных после compaction/flush требуется файл Link. Информация xmax/удаления из Heap в MARS3 хранится в Delta, а Link гарантирует сохранность информации об удалении в процессе компактации.
Таким образом:
Heap: цепочка версий в основном опирается на заголовок кортежа + цепочку ctid (указатели версий прямо в данных)
MARS3: семантика версий/удаления вынесена в обходные структуры Delta + Link, поэтому корректность зависит не только от файлов данных, но и от сохранности, целостности и непрерывности Delta/Link при flush/compaction/vacuum.
Ранние версии MARS3 при конкурентном обновлении одной строки сразу завершались с ошибкой без поддержки UpdateChain, что не обеспечивало корректность. После внедрения UpdateChain блокировка логической строки выполняется через TupleLock, а поиск последней версии идет по цепочке обновлений — конкурентные обновления выполняются последовательно, гарантируя корректность семантики UPDATE.
Аналогично PostgreSQL, в YMatrix обновление и удаление не изменяют исходное пространство данных, а реализуются через механизм множественных версий кортежей:
Обновления и удаления в MARS3 не выполняются на месте: старые данные скрываются через файлы DELTA и информацию о версиях, контролируя видимость
Удаление в MARS3 выполняется через DELETE: информация об удалении записывается в файл Delta соответствующего Run, физическое удаление происходит при слиянии Run
Обновление в MARS3 выполняется через UPDATE: сначала удаляется исходная запись, затем вставляется новая
Мертвые кортежи (невидимые runs), образующиеся при обновлении и удалении, периодически очищаются фоновым процессом autovacuum, либо вручную командой vacuum. Кроме того, при компактации малые Run сливаются в один большой, невидимые runs удаляются. Команда vacuum full идет дальше: она сливает множество малых Run в один большой. При отсутствии новых записей выполнение vacuum full обычно объединяет все партии до предела, итоговый размер каждой партии приблизительно равен значению max_runsize (примечание: во время vacuum full также могут образовываться невидимые runs).
Проще говоря:
vacuum выполняет flush + удаление невидимых runs и сброс rowstore
vacuum full дополнительно выполняет слияние поверх операций vacuum






