
在大规模分析型数据库中,并行扫描通常意味着更多计算资源参与处理,因此从理论上来说,应该查询得更快。但在真实业务场景中,查询性能不仅取决于扫描本身快不快,还取决于数据要不要“搬家”。很多时候,扫描本身已经足够快,真正拖慢查询的,是执行过程中的中间数据搬运、额外重分布,以及由此带来的执行链路复杂化。
MARS3 Bucket 的目标,正是解决这一问题,其并不是简单把数据切成更小的块,也不是传统意义上的逻辑分桶,而是一种让并行扫描与本地计算更协同的数据组织方式,使得并行扫描之后,数据仍然能够保持良好的本地性,从而减少不必要的数据搬运,让并行收益更容易真正体现在端到端查询性能上。测试表明,使用 MARS3 Bucket 之后,对于复杂的分析查询场景,比如 TPCH、TPCDS 等,相比 YMatrix 上一个版本性能提升约一倍。
在理解问题本质之前,我们需要了解一下数据共生、并行扫描这两个概念。
数据共生
在 YMatrix 数据库中,数据是按照一定规则分散存储在各个数据节点 (segment) 上的,所有数据节点上的数据共同构成完整的数据集。每张表在定义时都需要指定分布键,数据在写入时根据分布键计算哈希值,然后将哈希结果映射到某个数据节点。因此,当表具有相同的分布键时,相同数据可以确保存储在同一个数据节点上,因此基于分布键的关联、聚集等操作将会以最⾼效的⽅式将绝⼤部分⼯作在节点本地完成,不需要数据移动,这种现象我们将其称为数据共生 (co-locality)。
并行扫描
首先 YMatrix 采用 MPP (Massively Parallel Processing) 架构,从整个表的数据角度看,每个数据节点同时扫描,所以本身就属于并行执行的范畴,这一层并行指的是整个实例范围内的并行。
另一层并行,指的是节点内并行,即从某一个特定数据节点中的表数据角度看,是否采用了并行扫描。在 YMatrix 里,某一个特定数据节点中的数据可以有多个进程同时参与扫描,这一层并行指的是节点内的并行。
首先,并行扫描本身就有一定的代价,比如多个扫描进程间的协同和数据交换,创建与管理进程的开销等等。在分布式数据库中,事情会变得更加复杂,查询性能不仅取决于扫描本身,还取决于扫描之后的数据是否还能继续“就地计算”。
前文也提到,如果一张表已经按某个分布键做了哈希分布,那么基于这个分布键展开的 GROUP BY 和 JOIN 等,就可以在本地完成,因为相同键值的数据天然已经落在同一个数据节点上,主节点只需要等待各个数据节点计算完成,做最后的汇总即可。
但是一旦采用并行扫描之后,问题会变得些许复杂 —— 并行扫描关注的是多个扫描进程一起将数据扫出来,但它并不能天然保证相同键值的数据仍然待在一起,因为并行扫描通常是按页面块或扫描区间去领取任务,因此一旦相同键值的数据被不同扫描进程分别处理,后续为了完成正确的聚合或连接,数据库就需要额外做一次数据传输。
于是,原本可以本地完成的工作,被迫变成“先并行扫描,再重新搬数据,再继续计算”。
让我们看个实际例子:假设某个数据节点上有 1、2、2、3 条数据,并且每一条数据分别位于一个数据页面上:
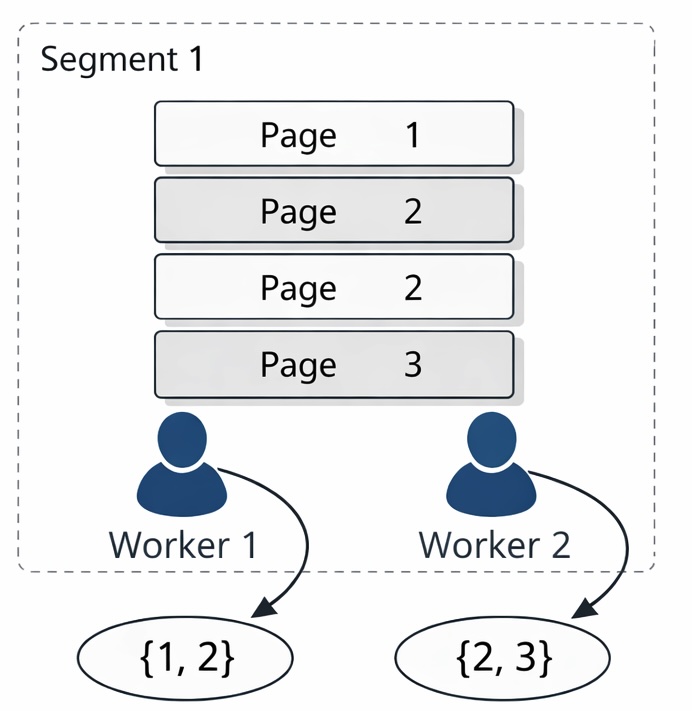
假设有两个进程参与扫描,worker1 扫描到了 1 和 2 数据,worker 2 扫描到了 2 和 3 数据,这种场景下,就不能确保同一个值 (此例中的 2) 只由一个 worker 独占输出,所以为了确保结果的一致性和正确性,就必须把这些分散的中间结果重新汇集、重新分配,再继续后续计算,于是数据库将 2 的结果再次传输到一个数据节点上进行运算。不难想象,假如需要传输几万条甚至上百万千万的量级,这种“数据搬家”的代价会极其可观,也会让整条执行路径变得更长、更复杂。
所以对于客户而言,这意味着一个很现实的问题:并行开了,CPU 使用率也上去了,但中间的数据搬运变多了,整体查询的效率也不一定会有所提升。
为了解决上述问题, MARS3 Bucket 应运而生。MARS3 Bucket 不是简单的分桶功能,也不是一个面向语法层的逻辑切分手段。其核心目标,是让并行扫描之后,数据仍然保持良好的本地性,让更多计算继续在本地完成。
如果把传统分布理解为“先决定数据落到哪个数据节点”,那么 MARS3 Bucket 做的,就是在这个基础上更进一步:不仅决定数据落到哪个数据节点,还进一步在该节点内做更有组织的 bucket 划分。
这样一来,当多个进程在同时扫描时,不再只是“谁先抢到哪一页就扫哪一页” 这样的简单机制,而是“每个 worker 扫描自己所负责的一组 bucket”,这就是它与普通并行扫描最本质的区别。

在 MARS3 Bucket 模式下,数据在数据节点内部先经过更有组织的 bucket 划分,扫描时多个 worker 分别处理不同 bucket。由于 key 到 bucket 的映射是确定性的,相同 key 的数据更容易沿着同一条处理路径向下流动。这样,下游算子就更容易直接在本地完成计算,而不必再做一次数据搬家。对于客户来说,最直观的收益就是:不是把并行只用在“扫”上,而是把并行真正延续到“算”上。
让我们看个例子:假设有一张 t_sales 表,分布键是 c1。现有如下 SQL:select c1,count(*) from t_sales group by c1; SQL 很简单,按 c1 分组,统计每个 c1 值出现了多少行。在非并行扫描的情况下,每个数据节点本地顺序扫描完之后直接做哈希聚集,因为表本身就是按 c1 分布的,所以在数据节点级别上,可以确保相同 c1 的行一定在同一个数据节点上,不会跨节点传输,每个节点本地做完聚集之后,结果已经是正确的全量结果,最终将结果汇总到 master 即可。
Gather Motion 4:1
-> HashAggregate
Group Key: c1
-> Seq Scan on t_sales但是一旦启用了并行扫描,执行计划就变成了如下这种形式:
Gather Motion 12:1
-> Finalize HashAggregate
Group Key: c1
-> Redistribute Motion 12:12
Hash Key: c1
-> Partial HashAggregate
Group Key: c1
-> Parallel Seq Scan on t_sales由于 worker 是按页面竞争的方式读数据 (随机竞争页面进行读取),所以对优化器来说:从 worker 的输出流看,已经不能保证同一个 c1 只有一个 worker 独占输出,接着第二步 Partial HashAggregate,每个 worker 先对自己扫描到的数据做局部聚合,第三步 Redistribute Motion Hash Key: c1,也就是数据移动,因为 partial agg 之后,同一个 c1 仍然存在于多个 worker 的局部结果中,所以必须按 c1 再次重分布,才能确保结果的最终一致性。
简而言之,问题不在于表的分布策略,而在并行扫描路径没有保留可继续用于上层聚合规划的数据分布语义;为弥补这一点,优化器只能插入额外的 Redistribute Motion 算子,而这正是导致并行模式收益被侵蚀的核心原因。
而对于 MARS3 bucket,执行计划则变成了如下:
Gather Motion 12:1
-> HashAggregate
Group Key: c1
-> Parallel Custom Scan (MxVScan) 数据由于按照 Bucket 进行组织,所以扫描时每个 worker 只扫描一个或多个 bucket,这样扫描输出就可以继续保持分布特性,知晓分布语义,因此执行计划中便无需再显式添加 Redistribute Motion,无需数据传输,各个数据节点本地计算完成之后,最后再向上汇总即可。这样一来,搭配并行,便可以充分利用 CPU 资源,大幅度地提升 SQL 执行效率。
MARS3 Bucket 的使用语法如下,在建表时需要指定分桶粒度:
create table foo (c1 int, c2 int) using mars3 with (mars3options='nbuckets = 2').nbuckets 的有效值为 1 ~ 128,默认值为 1,说明只有 1 个桶,也就是不进行分桶。
Bucket 的最终目标是让 segment 内多个 worker 有各自可扫的 bucket。因此,推荐 nbuckets 至少要不小于希望的 segment 内并行 worker 数,但这也并不意味着 bucket 越多越好,因为 bucket 会导致写入、维护、内部导航等变得更为复杂。根据最佳实践:
表大小 < 50 GB:不分桶,nbuckets=1,适用于不常参与大查询的维表和小结果集表,这类表基本不走并行扫描,更多是点查、小范围查询的场景
50 GB ~ 500 GB:优先从 nbuckets=4 或 8 开始,适用于几十 GB 到几百 GB 级别的大事实表,经常做聚集和复杂分析查询
500 GB ~ 2 TB:优先考虑 nbuckets=8 或 16,往往已经能较好匹配常见数据节点内的并行度,同时不会把 Bucket 数拉得太高
2 TB:根据数据节点内实际并行度和压测结果,在 16 或 32 中选择,或者可以考虑更激进的值
在分布式查询场景里,很多查询慢并不是慢在计算本身,而是慢在数据移动。MARS3 Bucket 的核心价值就是尽量减少那些原本不必发生的数据重分布,让更多处理中间结果可以直接在本地完成。
当中间数据搬运减少后,查询执行路径也会更简洁。对复杂分析型 SQL 而言,这种收益通常不只是体现在某一个扫描节点上,而是体现在整条执行链路上:更少的中间环节、更少的额外调度、更少的中间处理成本。
扫描更快,并不自动等于查询更快。MARS3 Bucket 在于让并行能力不只是停留在扫描阶段,而是更容易转化成整个查询路径的实际收益。对客户而言,这意味着性能提升更可能直接体现在最终查询耗时上,而不是只体现在局部算子看起来更忙、更热闹。
在 MPP 查询场景中,真正昂贵的往往不只是扫描和计算本身,更是数据在执行过程中的数据传输成本。并行扫描如果不能保住数据原有的分布语义,就很容易把更多算力转化成更多的数据传输,而不是更高的查询效率。
MARS3 Bucket 的意义就在于尽可能避免这种情况。它让并行扫描不再只是更多扫描进程一起读数据,而是让数据节点内部的并行处理也变得更有组织、更可利用,真正将并行延续到“算”上。对于那些依赖本地聚合和本地连接能力的大规模分析场景来说,这意味着更少的数据搬运、更少的执行切片,以及更有机会把并行能力真正转化为端到端性能收益,能够大幅减少客户的使用成本。






