

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
部署数据库
使用数据库
管理集群
最佳实践
高级功能
高级查询
联邦查询
Grafana 监控
备份恢复
灾难恢复
图数据库
管理手册
性能调优
故障诊断
工具指南
系统配置参数
SQL 参考
YMatrix 是一款基于 PostgreSQL 系的企业级分布式数据库产品。YMatrix 融合时序(Time-series)、分析(OLAP)、事务(OLTP)、AI 全场景能力于一体,具备全场景、低成本、高性能、高可用、易扩展、 安全合规等核心优势,以「超融合」理念破解传统架构复杂、运维成本高的难题,为企业提供“一站式”的数据存储方案。
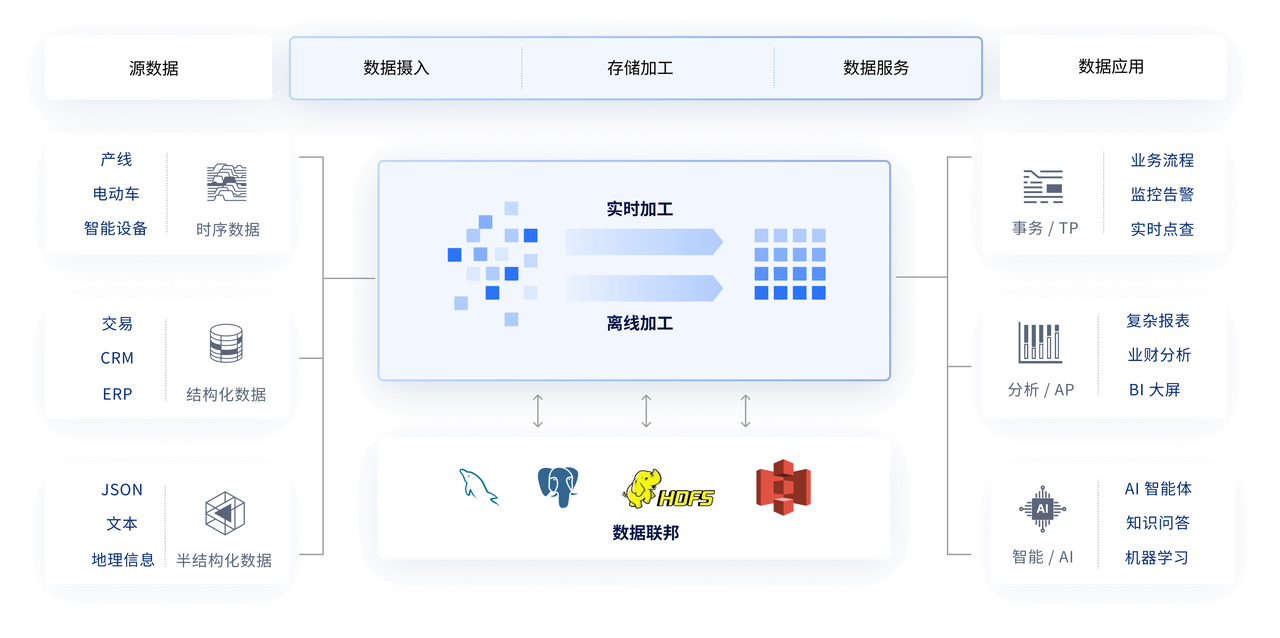
专研时序场景,提供强大高并发能力,为智能网联汽车、智慧工厂等时序场景深度优化。支持 CTE、窗口函数等高级语法及原生时序专用函数,针对复杂网络环境特别支持乱序、分批写入;支持 0 业务中断集群水平扩容,灵活应对数据增长;支持冷数据降级至对象存储,可大幅降低存储成本。
支持 TB ~ PB 量级海量数据,为大型企业报表、BI 等分析型应用提供可靠、高性能的数据加工、数据服务能力;不但性能强大,多表 JOIN 表现出色,更支持窗口函数、物化视图等高级分析能力;除具备传统数仓批处理能力外,独创 Domino 流计算引擎,通过 SQL 即可替换 Flink、Spark 实现数据的实时流式加工。
完备的 ACID 特性,可提供金融级数据可靠性保障,满足财务、ERP 等重要系统对数据库性能和数据正确性、一致性的要求;同时支持存储过程、触发器、异地灾备等高级功能,广泛适用于各类复杂事务型场景。
可为大语言模型 (LLM) 提供向量检索能力,帮助企业基于业务数据快速构建“AI 智能体”;无需 Spark, 数据库内可直接执行 PL/Python ,充分利用硬件资源,并能提升机器学习效率;支持多模数据管理、混合搜索等能力。
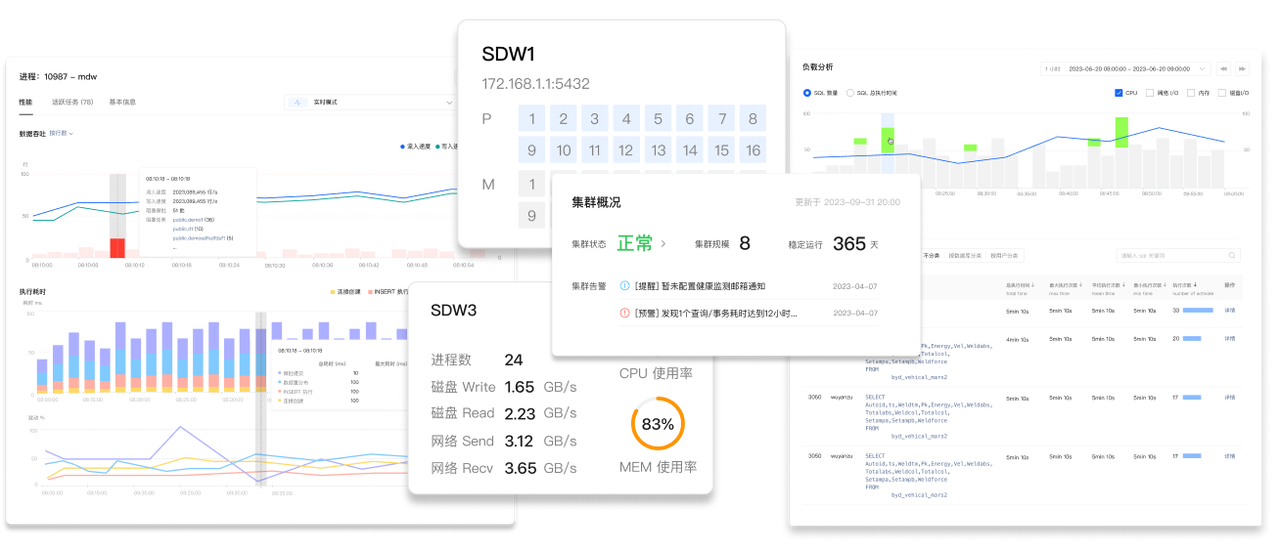
SQL : 2016 标准MatrixUI 是旨在为运维工程师提供简洁易用、信息全面的图形化运维管理工具。
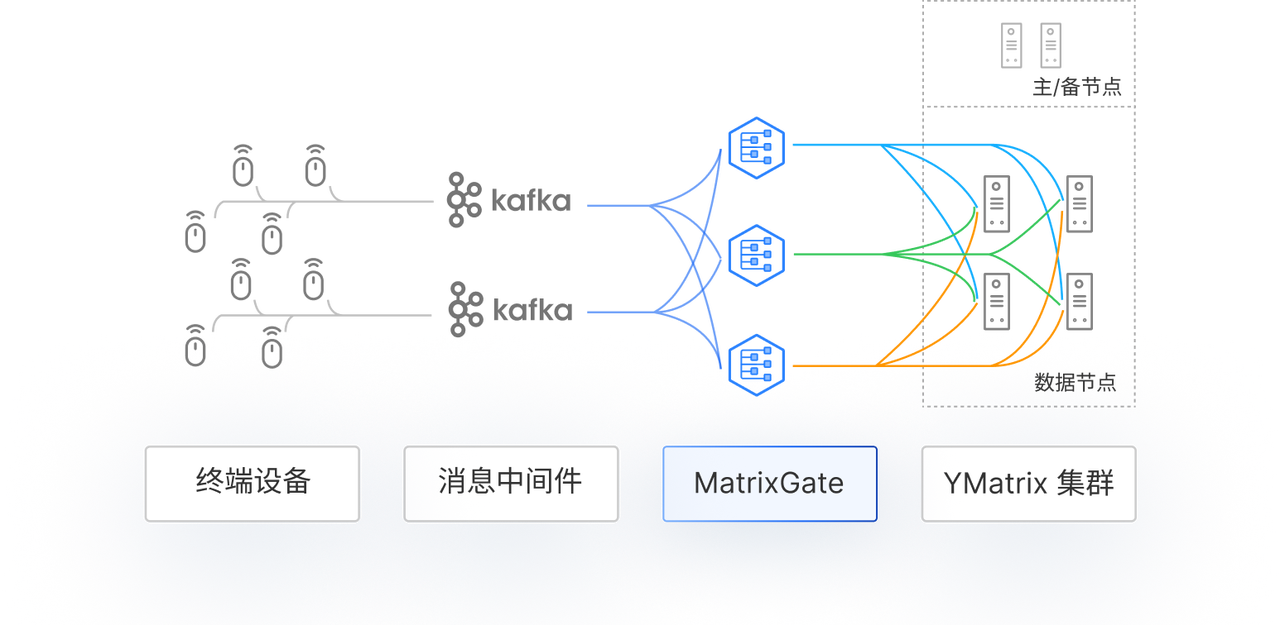
MatrixGate 是高性能数据加载工具,可将数据均匀分发至所有数据节点实现并行写
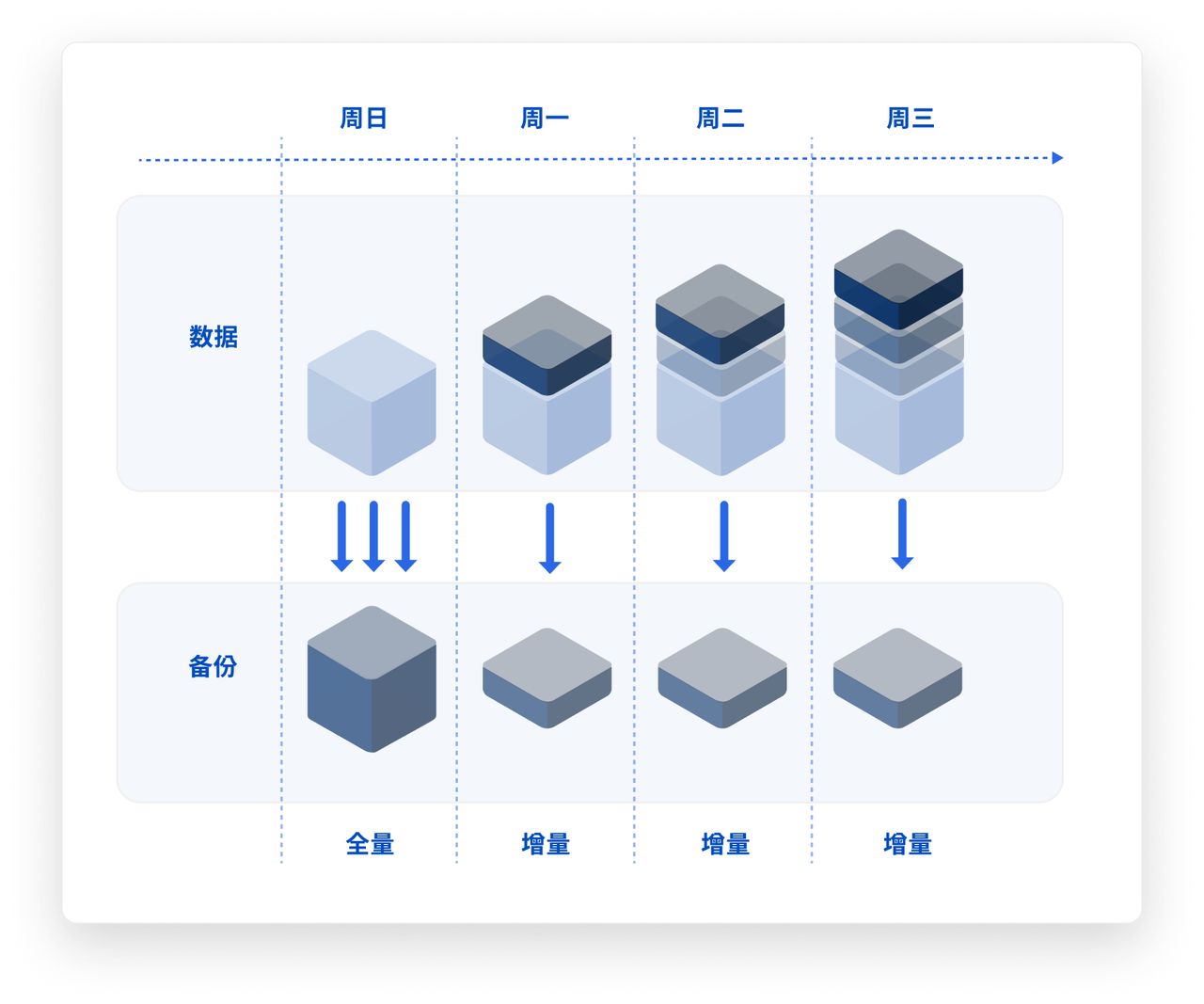
MatrixArchive是将一个正常运行的 YMatrix 数据库集群在特定时间点保存的所有数据按照一定的规则保存成文件来进行数据备份。备份的数据可以保证在该特定时间点的数据完整性和一致性。 另外,从一个给定备份的所有文件,可以恢复出一个可用的 YMatrix 数据库集群,其中的内容和原集群在特定时间点的数据一致。
MatrixShift 是专用数据迁移工具,支持从各版本 Greenplum 及 YMatrix 之间的全量、增量、条件迁移,具备高效(点对点传输、小表优化、传输压缩)、灵活配置等特点。



