

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
流计算引擎
灾难恢复
系统配置参数
索引
扩展
SQL 参考
常见问题(FAQ)
YMatrix 自动模拟出多种业务场景,并根据业务参数生成测试数据,你无需准备业务数据,也无需输入任何 SQL 语句,即可体验数据边入边查。
你需要保持图形化界面的登录状态,如果你不小心在初始化完成后关闭了页面,你需要在浏览器里输入主节点 IP 及端口号,重新进入:
http://<IP>:8240
选择“快速体验”部分的“轻松上手”模块。
我们准备了三个相对常见的物联网场景,你可以选择其中一个感兴趣的场景,点击“下一步”,本步骤以“车联网”为例。
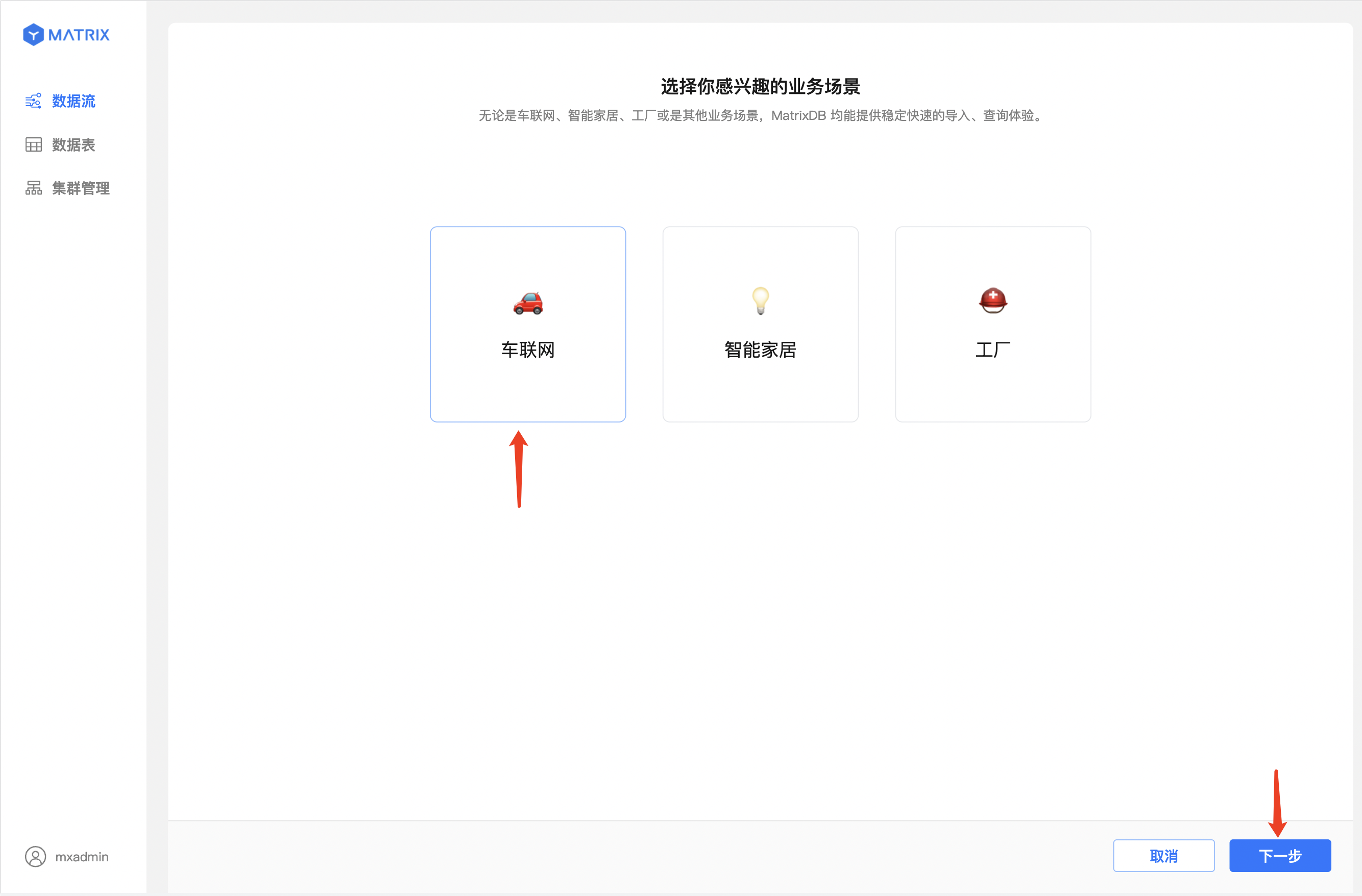
车联网场景已准备好了对应的业务数据,其中
点击“下一步”。

按照“生成数据流”的业务参数设定,程序会使用 mxbench 生成模拟数据,数据流成功生成后,页面自动跳转至“执行查询”页面。
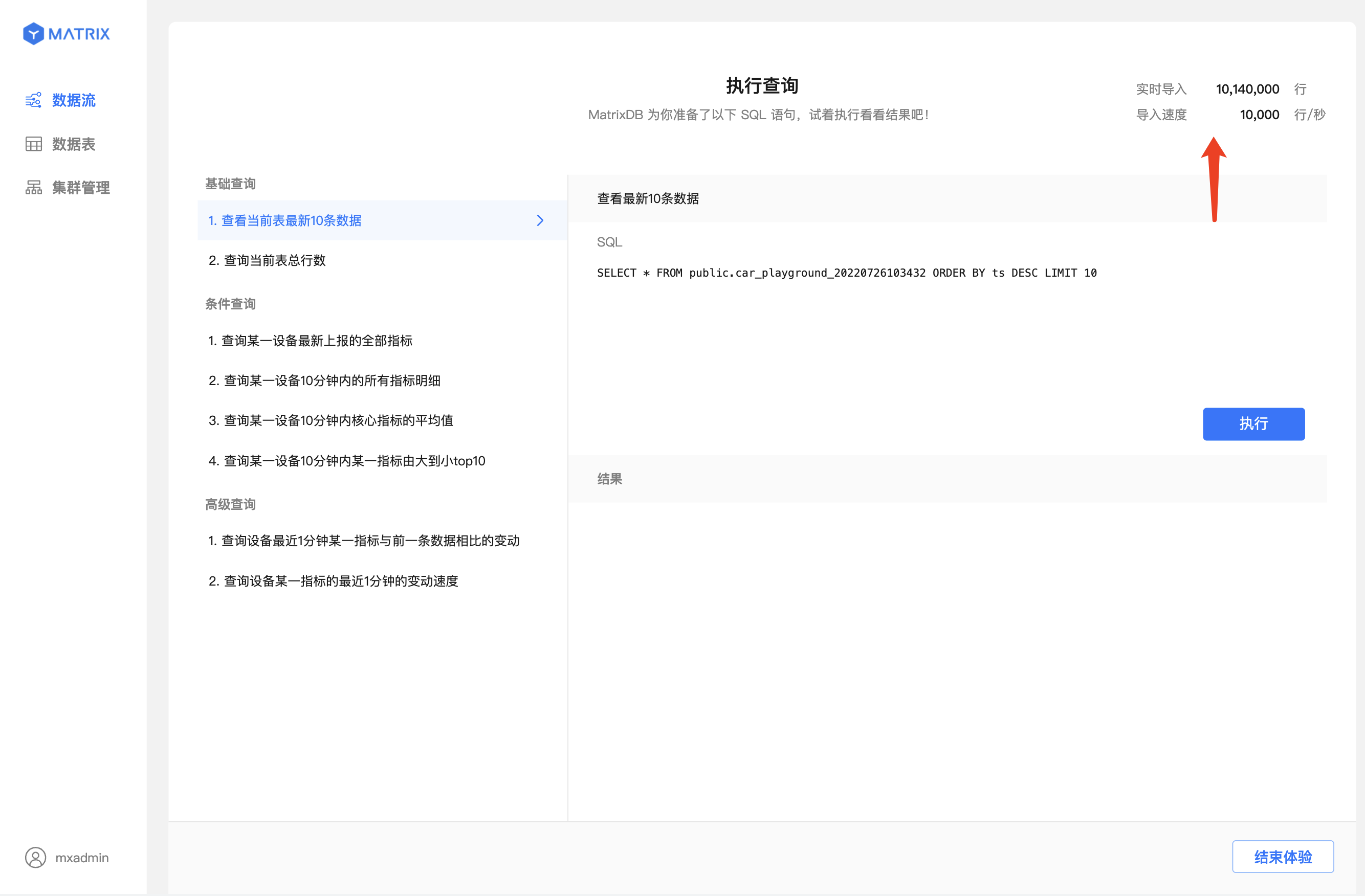
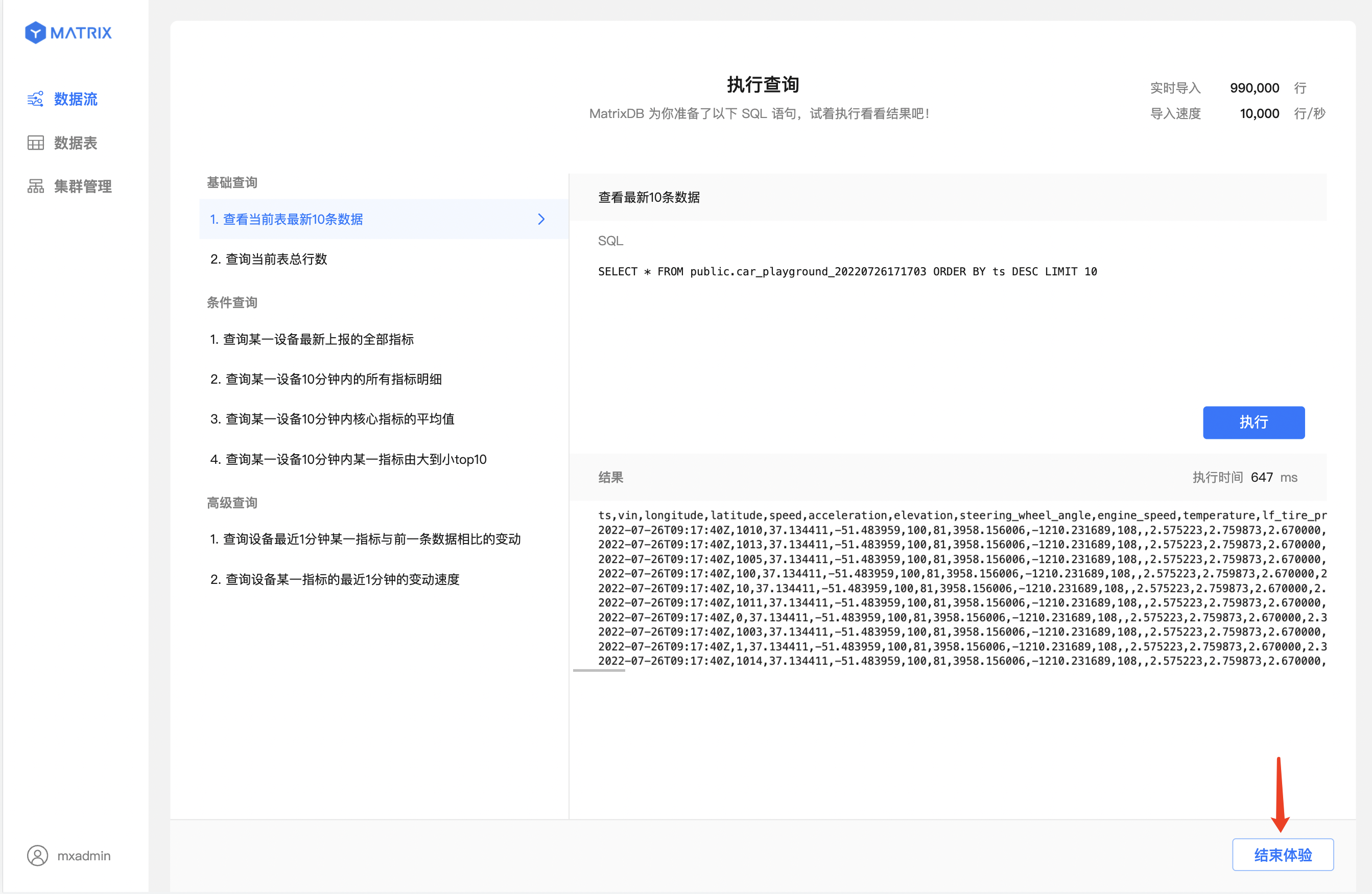
我们准备了共 8 条典型的查询语句,包含 2 条基础查询,4 条条件查询,2 条高级查询。
点击选择你感兴趣的查询语句,右侧“SQL”部分即展示对应的查询语句。
例如选择“基础查询”中的第一条。
选中目标查询语句后,点击“执行”,即可得到该条语句的查询执行结果
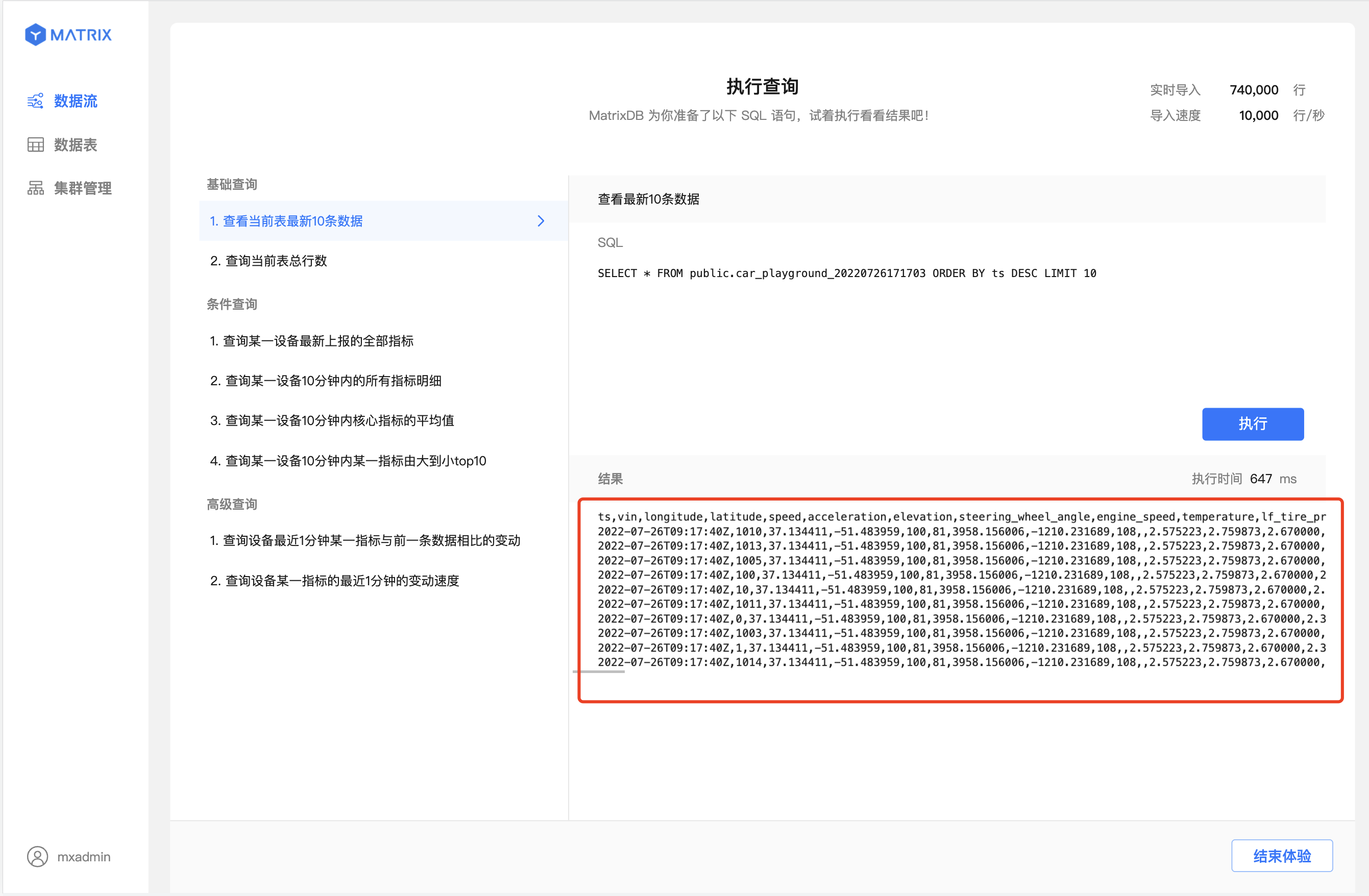
点击“结束体验”,将自动删除“轻松上手”部分系统产生的数据和表
点击“返回首页”即跳转至“数据流”列表页
体验完毕!



