本文档介绍了 Prometheus 监控面板中 YMatrix、 MatrixGate、主机节点监控等相关指标及参考报警阈值。
告警级别说明
注意!
无参考报警阈值的指标,请根据实际情况判断并配置告警条件。

此版块显示了集群的整体运行状态,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 集群状态 | 集群节点状态,包括: 0:正常 1:无 Standby 2:无 Mirror 10:分布不均衡(部分节点宕机恢复后,没有重新平衡主从角色) 11:存在主从不同步节点(部分 Mirror 节点与 Primary 不同步) 12:只有 Master(集群只启动了 Master 节点,通常在诊断时使用) 20:Segment 宕机(存在不可用的 Segment 节点,集群不可用) |
short | p0 | 20:Segment 宕机为严重事件,需要报警 |
| 运行时间 | 包括 YMatrix 自启动以来的运行时间和 Master 宿主机操作系统运行时间 | seconds(s) | ||
| 版本 | YMatrix 的版本 | |||
| 连接状态 | 连接状态显示了数据库系统中的连接数统计,包括:连接总数(Total)、连接查询被阻塞数(Blocked)、空闲连接数(Idle)、事务中空闲数(Idle in TXN) | short | ||
| 慢查询数 | 当前系统中,执行时间超过 1 天的查询数量 | short | 大于 0 则说明有特别慢的查询,需要报警 | |
| 事务 | 事务提交与回滚数量统计 | short | ||
| Disk Space in Use | 磁盘使用量。Master 节点或 Segment 节点实例的磁盘使用量 | 0-1 | ||
| 节点状态 | 每个节点的状态,包括: 0:UP(正常) 10:Switched(角色互换,说明出现过主从切换,需要重新平衡) 11:Resync(主从同步中) 20:Down(宕机) |
short | p2/p1 | 持续时间超过 5 分钟不为 0 时需要报警 p2 20 值需要增加报警 p1 |
此版块展示了数据库性能,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Page Hit Ratio | HEAP 表读操作命中块缓存次数与读操作总数的比值。(缓存仅包括 HEAP 表自己维护的缓存,不包括操作系统缓存) 显示的数值为当前值,曲线为历史值 通常要求数值在 90% 以上 |
0-1 | ||
| Temp Size | 数据库中查询写入临时文件的数据总量。不管创建临时文件的原因和 log_temp_files 设置,所有临时文件都会被统计 | bytes | ||
| Sessions Per Database | 每个数据库的会话数 | short | ||
| Activities | 各个状态会话数 | short | ||
| Deadlocks | 发生死锁数量 | short | p3 | 发生死锁时,YMatrix 自动解锁,失败的查询可以重试,可以配置告警 |
| Checksum Failures | 数据库数据页校验失败次数,如果没有开启则为 NULL | short | p3 | |
| Rows Read | 读取数据行数 | short | ||
| Checkpoints | 检查点统计。橘色为主动请求生成检查点的操作次数,绿色为因为超时而自动生成检查点的操作次数 | short | ||
| Page Cache Hit | blks_hit:读取数据页时命中缓存次数 blks_read:未命中缓存而要读磁盘的次数 |
|||
| Replication Latency | write_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL 成功(但尚未刷新或应用它)之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 remote_write 时,提交产生的延迟 flush_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL 并刷盘成功(但尚未应用它)之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 on 时,提交产生的延迟 replay_lag - 本地刷盘最新的 WAL 和接收到 Standby/Mirror 写入 WAL,刷盘并成功应用之间经过的时间。如果配置了 Standby/Mirror,可用于测量当 synchronous_commit 配置为 remote_apply 时,提交产生的延迟 |
milliseconds(ms) | p3 | 默认情况下,Primary 与 Mirror 间为同步复制,如果大于 1s,会导致事务提交变得很慢。如果为异步复制,则可以适当调大告警阈值 |
| Rows Insert/Update/Delete | 数据 INSERT 或 UPDATE 或 DELETE 的数量 | short | ||
| Checkpoint buffers | buffers_checkpoint - 检查点生成时写入的缓存数 buffers_clean - 后台写进程写入的缓存数 buffers_backend - 工作进程直接写入的缓存数 |
short | ||
| Top 10 Replication Lag Size | Top 10 复制延迟 WAL 大小 | bytes | p3 | 默认情况下,Primary 与 Mirror 间为同步复制,如果大于 1GB,会导致事务提交变得很慢。如果为异步复制,则可以适当调大告警阈值 |
此版块展示了存储相关的统计,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Top 10 Database | 数据库大小 Top10 | bytes | ||
| Top 10 Users | 用户数据量大小 Top10 | bytes | ||
| Top 10 Aging Database | 数据库年龄 Top10 | short | p2 | 数据库最大使用年龄为 21E,当只剩 1E 时,YMatrix 实例会强制停止,属于 5E 时,日志中会有提示,建议告警配置为 6E 和 2E。 |
| Top 10 Big Tables | 表大小 Top10 | bytes | ||
| Top 10 Big Partitions | 分区表大小 Top10 | bytes | ||
| Top 10 Growth Today | 当天数据量增长最快的 10 张表 | bytes | ||
| Top 10 Growth Last 7 Days | 7天内数据量增长最快的 10 张表 | bytes |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 版本 | mxgate 版本号 | |||
| 运行时间 | mxgate 运行时长 | seconds(s) | ||
| 进程号 | mxgate 后台进程 PID | short | p2 | 无进程号,可能是 mxgate 宕机 |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 目标表 | 该任务数据插入的目标表 | |||
| 总入库行数 | 该任务自 mxgate 启动以来,入库成功的数据总数 | short | ||
| 总错误行数 | 该任务自 mxgate 启动以来,入库失败的数据总数 | short | p3 | 可以根据情况设置报警阈值 |
| 总入库大小 | 该任务自 mxgate 启动以来,入库成功的数据量大小 | short | ||
| 并发度 | 并发总量:值为配置项 stream - prepared + 1,并发的上限配置 工作数量:实际工作的并发量,某些线程会进入休眠状态,所以实际工作的并发度可能小于配置 |
short | ||
| 事务时间粒度 | 数据事务提交的时间跨度 | short | ||
| 目标表阻塞 | 目标表阻塞数量 | short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 提交行数 | 该 job 已提交行数 | short | ||
| 入库行数 | 该 job 已入库行数 | short | ||
| 阻塞行数 | 该 job 被阻塞行数 | short | p3 | 可以根据情况设置报警阈值 |
| 失败行数 | 该 job 写入失败行数 | short | p3 | 可以根据情况设置报警阈值 |
| 写入数据量 | 该 job 写入字节总数 | bytes |

数据入库经历的各个阶段延时,为一段时间的统计值,包括:
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 总延时统计 | 该延时为下面几个延时之和 | nanoseconds(ns) | p3 | 30s |
| insertStart 延时统计 | 从执行 INSERT 到第一条数据发送给 Segment 的延时 | nanoseconds(ns) | ||
| write 延时统计 | mxgate 将该批次数据发送给 Segment 的耗时 | nanoseconds(ns) | ||
| insertDone 延时统计 | 最后一条数据发送到 Segment 到 INSERT 语句执行完毕(数据在各个 Segment 之间重分布落盘结束)的延时 | nanoseconds(ns) | ||
| commit 延时统计 | 执行 commit 命令的延时 | nanoseconds(ns) |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| CHECKPOINT 次数 | 一分钟内 CHECKPOINT 执行的次数 | short | ||
| CHECKPOINT 写延时 | 在文件被写入磁盘的检查点处理部分花费的总时间,以毫秒计 | milliseconds(ms) | ||
| CHECKPOINT 同步延时 | 在文件被同步到磁盘中的检查点处理部分花费的总时间,以毫秒计 | milliseconds(ms) | ||
| 申请缓存块数 | 被分配的缓冲区数量 | short | ||
| 写入磁盘缓存块数 | 分为三类: 1.在检查点期间被写的缓冲区数目 2.被后台写进程写的缓冲区数目 3.被一个后端直接写的缓冲区数量 |
short | ||
| 刷脏页达到上限次数 | 后台写进程由于已经写了太多缓冲区而停止清洁扫描的次数 | short | ||
| 主从延迟日志量 | Master 与 Standby 或 Primary 与 Mirror 之间的 WAL 延迟量 | bytes | ||
| 主从延迟时间 | Master 与 Standby 或 Primary 与 Mirror 之间的延时时间 | milliseconds(ms) | ||
| 目标表阻塞事件趋势图 | 分为四类: 1.锁相关 2.复制相关 3.资源组相关 4.资源队列相关 |
short |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| CPU Busy | 收集所有 CPU 内核 Busy 状态占比 | 0-1 | ||
| Sys Load(5m avg) | 5 分钟内 CPU 所有内核的平均负载率 | 0-1 | p3/p2 | CPU核数 3 / CPU核数 5 |
| Sys Load(15m avg) | 15分钟内 CPU 所有内核的平均负载率 | 0-1 | p3/p2 | CPU核数 3 / CPU核数 5 |
| RAM Used | 已使用的内存大小(内存总量 - 空闲的内存大小 - Buffer缓存和Cached缓存占的内存大小) | 0-1 | ||
| SWAP Used | 已使用的交换内存的大小 | 0-1 | p3 | 80% |
| Root FS Used | 根文件系统使用率 | 0-1 | p3/p2 | 60%/80% |
| CPU Cores | 物理 CPU 的核数 | short | ||
| RootFS Total | 根文件系统总空间 | bytes | p3/p2 | 60%/80% |
| Uptime | 系统正常运行的时间 | seconds(s) | ||
| RAM Total | 内存大小 | bytes | ||
| SWAP Total | 交换分区的大小 | bytes |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| CPU Basic | CPU 的基本信息 /proc/stat | 0-1 | ||
| Memory Basic | 内存基本信息 | bytes | ||
| Network Traffic Basic | 每个接口的基本网络信息 | bit | p3/p2 | 网卡最大带宽 60% 80% |
| Disk Space Used Basic | 所有挂载的文件系统的磁盘空间占比 | 0-1 | p3 | 磁盘使用率 60% 80% |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| CPU | CPU 在内核模式下执行的进程占比 | short | ||
| Memory Stack | 内存堆栈 /proc/meminfo | bytes | ||
| Network Traffic | 各个网络接口的传输速率 | bytes/sec | ||
| Disk Space Used | 所有挂载的文件系统的磁盘空间大小 | bytes | ||
| Disk IOps | 磁盘读写 | I/O ops/sec(iops) | ||
| I/O Usage Read / Write | 磁盘读写速率 | bytes | ||
| I/O Utilization | I/O 利用率 | 0-1 | p3/p2 | 60% / 80% |
| CPU spent seconds in guests(VMs) | 运行一个带 nice 值的 guest 花费的时间 | milliseconds(ms) |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Memory Active / Inactive | 最近使用频繁/较少的内存 | |||
| Memory Active / Inactive Detail | Inactive_file - LRU list 上长时间未被访问过的与文件对应的内存页 /proc/meminfo LRU_INACTIVE_FILE Inactive_anon - 上长时间未被访问过的匿名页和交换区缓存(包括 tmpfs) /proc/meminfo LRU_INACTIVE_ANON Active_file - LRU list 最近被访问过的与文件对应的内存页 /proc/meminfo LRU_ACTIVE_FILE Active_anon - 最近被访问过的匿名页和交换区缓存(包括 tmpfs) /proc/meminfo LRU_ACTIVE_ANON |
bytes | ||
| Memory Shared an Mapped | Mapped - mapped 缓存页占用的内存 /proc/meminfo Mapped Shmem - 共享内存 /proc/meminfo Shared |
bytes | ||
| Memory Vmalloc | VmallocChunk - vmalloc 可分配的最大的逻辑连续的内存大小 /proc/meminfo VmallocChunk VmallocTotal - vmalloc 可使用的总内存大小 /proc/meminfo VmallocTotal VmallocUsed - vmalloc 已用的总内存大小 /proc/meminfo VmallocUsed |
bytes | ||
| Memory Anonymous | Active_anon - pages最近被使用过的匿名虚拟内存页 /proc/vmstat nr_active_anon Active_file - 最近被使用过的文件虚拟内存页 /proc/vmstat nr_active_file |
bytes | ||
| Memory HugePages Counter | HugePages_Free - 系统当前总共拥有的空闲 HugePages 数目 /proc/meminfo HugePages_Free HugePages_Rsvd - 系统当前总共保留的HugePages数目,更具体点就是指程序已经向系统申请,但是由于程序还没有实质的HugePages读写操作,因此系统尚未实际分配给程序的HugePages数目 /proc/meminfo HugePages_Rsvd HugePages_Surp - 指超过系统设定的常驻HugePages数目的数目 /proc/meminfo HugePages_Surp |
bytes | ||
| Memory DirectMap | DirectMap1G - 映射为 1G 的内存页的内存数量 DirectMap2M - 映射为 2M 的内存页的内存数量 DirectMap4K - 映射为 4kB 的内存页的内存数量 |
bytes | ||
| Memory NFS | NFS Unstable - 发给 NFS server 但尚未写入硬盘的缓存页 | bytes | ||
| Memory Commited | 当前系统已经分配的内存量,包括已分配但尚未使用的内存大小 当前系统可分配的内存量 |
bytes | p3/p2 | 60%/80% |
| Memory Writeback an Dirty | Writeback - 正准备主动回写硬盘的缓存页 /proc/meminfo Writeback WritebackTmp - FUSE用于临时写回缓冲区的内存 /proc/meminfo WritebackTmp Dirty - 需要写回磁盘的数据大小 /proc/meminfo Dirty |
bytes | ||
| Memory Slab | Reclaimable - 可回收的 slab 虚拟内存页 /proc/vmstat nr_slab_reclaimable Unreclaimable - 不可回收的 slab 虚拟内存页 /proc/vmstat nr_slab_unreclaimable |
bytes | ||
| Memory Bounce | Bounce - bounce buffers 占用的内存 /proc/meminfo Bounce | bytes | ||
| Memory Kernel / CPU | KernelStack - 内核栈大小(常驻内存,不可回收) PerCPU - 每个 CPU 加载模块分配的内存大小 |
bytes | ||
| Memory HugePages Size | HugePages - 系统当前总共拥有的HugePages数目 /proc/meminfo HugePages Hugepagesize - 每一页 HugePages 的大小 /proc/meminfo Hugepagesize |
bytes | ||
| Memory Unevictable MLocked | Unevictable - 不可被回收的内存 /proc/meminfo Unevictable MLocked - 被 mlock() 系统调用锁定的内存大小 /proc/meminfo MLocked |
bytes |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Memory Pages In / Out | Pagesin - 数据从硬盘读到物理内存的速率(5分钟内) /proc/vmstat pgpgin Pagesout - 数据从物理内存写到硬盘的速率(5分钟内) /proc/vmstat pgpgout |
short | ||
| Memory Page Faults | Pgfault - 一级页面和二级页面的平均错误数(5分钟内) /proc/vmstat pgfault Pgmajfault - 一级页面的平均错误数(5分钟内) /proc/vmstat pgmajfault Pgminfault - 二级页面的平均错误数(5分钟内) |
short | ||
| Memory Pages Swap In / Out | Pswpin - 数据从磁盘交换区装入内存的速率(5分钟内) /proc/vmstat pswpin Pswpout - 数据从内存转储到磁盘交换区的速率(5分钟内) /proc/vmstat pswpout |
short | ||
| OOM Killer | OOM Killer 调用次数 | short | p3 | 有变化就告警 |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Time Syncronized Drift | 估算误差(秒) 本地系统和参考时钟之间的时间偏移 最大误差(秒) |
short | ||
| Time Syncronized Status | 时钟是否与一个可靠的服务器同步 估算误差(秒) |
short | ||
| Time PLL Adjust | 锁相环时间调整 | short | ||
| Time Misc | 时钟滴答之间的秒数 国际原子时 (TAI) 偏移量 |
short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Processes Status | Processes blocked - 当前被阻塞的任务的数目 /proc/stat procs_blocked Processes in runnable state - 当前运行队列的任务的数目 /proc/stat procs_running |
short | p3 | blocked:10 |
| Processes Forks | Processes forks second - 每秒创建的进程个数 | short | ||
| PIDS Number and Limit | 当前主机运行进程数 主机限制最大进程数 |
short | p3/p2 | 15000/20000 |
| Processes Memory | 进程占用的虚拟内存的大小 进程可用最大虚拟内存大小 |
bytes | ||
| Process schedule stats Running / Waiting | 启动一个进程花费的时间 CPU处理等待时间 |
ms | ||
| Threads Number and LImit | 当前线程总数 主机最大线程数 |
short |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Vontext Switches / Interrupts | Context switches - CPU 的 context switch 平均次数(5分钟内) Interrupts - 服务的平均中断总数(5分钟内) |
short | ||
| Interrupts Detail | 当前系统的软中断列表和对应的中断号平均中断次数(5分钟内) /proc/interrupts | short | ||
| Entropy | 可用于随机数生成器 | short | ||
| File Descriptors | 最大打开文件描述符数 打开文件描述符数 |
short | ||
| Schedule timeslices executed by each cpu | 调度每个 CPU 执行的时间片 | short | ||
| CPU time spent in user and system contexts | 在用户和系统上下文中花费的 CPU 时间 | short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Hardware temperature monitor | 硬件的温度监控 | Celsius(℃) | ||
| Power supply | 是否供电 | short | ||
| Throttle colling device | 冷却设备状态 | short |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Systemd Sockets | sockets 已接受连接总数 | short | ||
| Systemd Units State | inactive - 不活跃的 Systemd 单元 failed - 失败的 Systemd 单元 deactivating - 停用的 Systemd 单元 active - 忙碌的 Systemd 单元 activating - 激活 Systemd 单元 |
short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Disk IOps Completed | Reads completed 每个磁盘分区每秒读完成次数 Writes completed 每个磁盘分区每秒写完成次数 |
I/O ops/sec(iops) | ||
| Disk Average Wait Time | Read wait time avg 每个磁盘读平均等待时间 Write wait time avg 每个磁盘平均写等待时间 |
Milliseconds(ms) | p3 | 1s |
| Disk R/W Merged | Read merged 每个磁盘分区每秒合并读完成次数 Write merged 每个磁盘分区每秒合并写完成次数 |
I/O ops/sec(iops) | ||
| Instantaneous Queue Size | 瞬时队列大小, 采样时未处理的请求数。随着请求被提供给适当的结构 request_queue 而递增,随着请求完成而递减 | short | ||
| Disk R/W Data | Read bytes 每个磁盘分区每秒读取的字节数 Written bytes 每个磁盘分区每秒写入的字节数 |
bytes/sec | ||
| Average Queue Size | 向设备发出的请求的平均队列长度 | short | ||
| Time Spent Doing I/Os | 向设备发出 I/O 请求的运行时间百分比(设备的带宽利用率)。对于串行提供请求的设备,当该值接近 100% 时,会出现设备饱和。但对于并行提供请求的设备,如 RAID 阵列和现代 SSD,这个数字并不能反映其性能限制 | 0-1 | ||
| Disk IOps Discards completed / merged | 磁盘 Discards 完成 IOps 磁盘 Discards 合并 IOps |
I/O ops/sec(iops) |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Filesystem space available | 挂载的文件系统可用空间 挂载的文件系统剩余空间 挂载的文件系统占用空间 |
bytes | p3/p2 | 60%/80% |
| File Descriptor | Maximum open file descriptors - 最大打开文件描述符数 Open file descriptors - 打开文件描述符的数量 |
short | ||
| Filesystem in ReadOnly / Error | ReadOnly 只读模式挂载的文件系统 Device error 设备错误次数 |
short | p3 | |
| File Nodes Free | Free file nodes:挂载的文件系统的 inode 剩余使用数量 | short | p3 | 60% |
| FIle Nodes Size | File nodes total:挂载的文件系统的文件节点大小 | short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Network traffic by Packets | Receive 各个接口每秒接收的数据包总数 Transmit 各个接口每秒发送的数据包总数 |
packets/sec | ||
| Network Traffic Drop | Receive drop 各个接口每秒接收的丢弃的数据包总数 Transmit drop 各个接口每秒发送的丢弃的数据包总数 |
packets/sec | p3 | 100 |
| Network Traffic Multicast | Receive multicast 各个接口每秒接收的多播包数 | packets/sec | ||
| Network Traffic Frame | Receive frame 各个接口每秒接收的帧数 | packets/sec | ||
| Network Traffic Colls | Transmit colls 各个接口上检测到的冲突数 | short | ||
| ARP Entries | ARP entries 各个接口上 ARP 表中包的统计 | short | ||
| Speed | Speed 网卡最大带宽 | bytes | ||
| Softnet Packets | Processed 每个 CPU 处理的包数 Droped 每个 CPU 丢弃的包数 |
|||
| Network Operational Status | Physical link state 每个网卡的物理连接状态 | short | ||
| Network Traffic Errors | Receive errors 监测到各个接口每秒接收的错误数据包总数 Rransmit errors 监测到各个接口每秒发送的错误数据包总数 |
packets/sec | p3 | 100 |
| Network Traffic Compressed | Receive compressed 各个接口每秒接收的压缩数据包总数 Transmit compressed 各个接口每秒发送的压缩数据包总数 |
packets/sec | ||
| Network traffic Fifo | Receive fifo 各个接口每秒接收的 fifo 包总数 Transmit fifo 各个接口每秒发送的 fifo 包总数 |
packets/sec | ||
| Network Traffic Carrier | Statistic transmit_carrier 由各个接口检测到的载波损耗的数量 | short | ||
| NF Contrack | NF conntrack entries 跟踪连接数 NF conntrack limit |
short | ||
| MTU | 各个接口接收的最大数据包的值 | bytes | ||
| Queue Length | 各个结构传输队列长度 | short | ||
| Softnet Out of Quota | 各个 CPU 积压情况 | 0-1 |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Sockstat TCP | TCP_alloc - 已分配(已建立、已申请到 sk_buff)的 TCP 套接字数量 TCP_inuse - 正在使用(正在侦听)的 TCP 套接字数量 TCP_mem - TCP 套接字缓冲区使用量 TCP_orphan - 无主(不属于任何进程)的 TCP 连接数(无用、待销毁的 TCP socket 数) TCP_tw - 等待关闭的 TCP 连接数 |
short | ||
| Sockstats FRG / RAW | FRAG_inuse - 正在使用的 Frag 套接字数量 FRAG_memory - 使用的 Frag 缓冲区 RAW_inuse - 正在使用的 Raw 套接字数量 |
short | ||
| Sockstat Used | Sockets_used - 已使用的所有协议套接字总量 | short | ||
| Sockstat UDP | UDPLITE_inuse - 正在使用的 UDP-Lite 套接字数量 | short | ||
| Sockstat Memory Size | TCP_mem_bytes - TCP 套接字缓冲区比特数 UDP_mem_bytes - UDP 套接字缓冲区比特数 |
bytes |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Netstat IP In / Out Octets | InOctets - 接收的八位字节数 OutOctets - 发送的八位字节数 |
short | ||
| ICPM In / Out | InMsgs - 收到的消息,此计数器包括 icmpInErrors 计数的所有计数器 OutMsgs - 试图发送的消息,此计数器包括 icmpOutErrors 计数的所有计数器 |
short | ||
| UDP In / Out | InDatagrams - 平均接收的 UDP 数据包(5分钟内) OutDatagrams - 平均发送的 UDP 数据包(5分钟内) |
short | ||
| TCP In / Out | InSegs - 收到的分段,包括错误收到的分段。此计数包括在当前建立的连接上接收的分段 OutSegs - 发送的分段,包括当前连接上的分段,但不包括仅包含重新传输的八位字节的分段 |
short | ||
| TCP Connections | CurrEstab - 当前状态为 ESTABLISHED 或 CLOSE-WAIT 的 TCP 连接数 | short | ||
| TCP Direct Transition | ActiveOpens - 已从 CLOSED 状态直接转换到 SYN-SENT 状态的 TCP 连接 PassiveOpens - 从 LISTEN 状态直接转换到 SYN-RCVD 状态的 TCP 连接 |
short | ||
| Netstat IP Forwarding | Forwarding - IP 转发报文数 | short | ||
| ICMP Errors | InErrors-接收到且确定为具有 ICMP 特定错误的消息(错误的 ICMP 校验和、错误的长度等) | short | ||
| UDP Errors | InCsumErrors - 具有校验和错误的 UDP 数据包的平均数(5分钟内) InErrors - 本机端口未监听之外的其他原因引起的 UDP 入包无法送达(应用层)的平均数(5分钟内) RcvbufErrors - 接收缓冲区溢出的 UDP 包的平均数(5分钟内) SndbufErrors - 发送缓冲区溢出的 UDP 包的平均数(5分钟内) NoPorts - 未知端口接收 UDP 数据包的平均数(5分钟内) |
short | p3 | 100 |
| TCP Errors | ListenOverflows - 套接字的侦听队列溢出的次数 ListenDrops - 忽略了到 LISTEN 套接字的SYN TCPSynRetrans - SYN-SYN/ACK 重传以中断 SYN 中的重传,快速/超时重传 RetransSegs - 重新传输的段数-也就是说,传输的 TCP 段数包含一个或多个先前传输的八位字节 InErrs - 错误接收的段(例如,错误的 TCP 校验和) OutRsts -使用 RST 标志发送的段 |
short | p3 | 100 |
| TCP SyncCookie | SyncookiesFailed - 接收的无效的 SYN cookies 的数量 SyncookiesRecv - 接收的 SYN cookies 的数量 SyncookiesSent - 发送的 SYN cookies 的数量 |
short |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| Node Exporter Scrape Time | 各个收集器持续时间 | seconds | ||
| Node Exporter Scrape | 各个收集器正常工作数量 | short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 主机五分钟负载 | 展示选中所有主机五分钟内负载 | short | ||
| 主机内存百分率 | 展示选中所有主机内存使用百分率 | 0-1 | ||
| CPU 繁忙百分比 | 展示 CPU 繁忙百分比 | 0-1 | ||
| 磁盘 I/O 使用率 | 展示磁盘 I/O 利用率 | 0-1 | ||
| 剩余空间利用率 | 展示所选主机剩余空间利用率 | 0-1 | ||
| 发送网络流量 | 展示所选主机发送网络流量 | bit | ||
| 接收网络流量 | 展示所选主机接收网络流量 | bit | ||
| SWAP 使用量 | 展示所选主机 SWAP 使用量 | 0-1 |

| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| net dev | 网络设备状态 | short | ||
| softnet_stat | 展示选中所有主机内存使用百分率 | short | ||
| hardirq_cpu | CPU 硬件中断次数 | short | ||
| hardirq_cpu_pie | CPU 硬件中断次数饼图 | short | ||
| hardirq_quene | 各个设备硬终端次数 | short | ||
| hardirq_quene_pie | 各个设备硬终端次数饼图 | short | ||
| softirq_rx | 数据接收软件中断次数 | short | ||
| softirq_rx_pie | 数据接收软件中断次数饼图 | short | ||
| softirq_tx | 数据传输软件中断次数 | short | ||
| softirq_tx_pie | 数据传输软件中断次数饼图 | short | ||
| ip | IP 网络层协议的收发包的情况 | short | ||
| udp | UDP 网络协议的收发包的情况 | short |
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| license 过期时间 | LICENSE 过期剩余时间 | seconds(s) | p3/p2 | 剩余时间小于 15 天,需要告警 p3 剩余时间小于 7 天,需要告警 p2,需及时联系 YMatrix 更换 LICENSE |
| 缺少分区策略 range 表 | Range 分区表缺少配置 APM 分区策略 | short | p2 | 需要及时处理,否则数据会写入默认分区,影响性能 |
| Range 分区表创建数 | Range 分区表新建分区表延迟数 | short | p2 | 需要及时处理,否则数据会写入默认分区,影响性能 |
| mars 表最大 runs | MARS2 内部指标 | short | p3/p2 | 超过 1500 告警 p3,需要关注是否还在涨 超过 1800 告警 p2 该值达到 2039 后会导致写入缓慢,甚至不可写入 |
| 最大 block_items 值 | mxgate 写入瞬时批次数 | short | ||
| YMatrix 总进程数 | 所选主机对应 postgres 相关进程总数 | short | p2 | 防止进程数过多,否则会导致内存不够用,按需配置 |
| 重复索引数 | 重复索引数,不需要的索引可以考虑删除 | short | p3 | |
| matrixgate 连接数 | mxgate 进程的连接总数 | short | ||
| 24 小时数据总量变化值 | 最近 24 小时数据变化总量 | bytes | ||
| Top10 子分区数 | 子分区数排名前十的表,按需配置,避免子表数过多,会对查询性能有一定影响,会占用更多内存 | bytes | ||
| Top10 模式大小 | 按模式总大小排名 Top 10 | bytes | ||
| Top10 系统表大小 | 按系统表总大小排名 Top 10 | bytes | ||
| Top10 默认分区表大小 | 按默认分表大小排名 Top 10 | bytes | p3 | 默认分区过大,需要告警,正常情况默认分区不应该存在数据 |
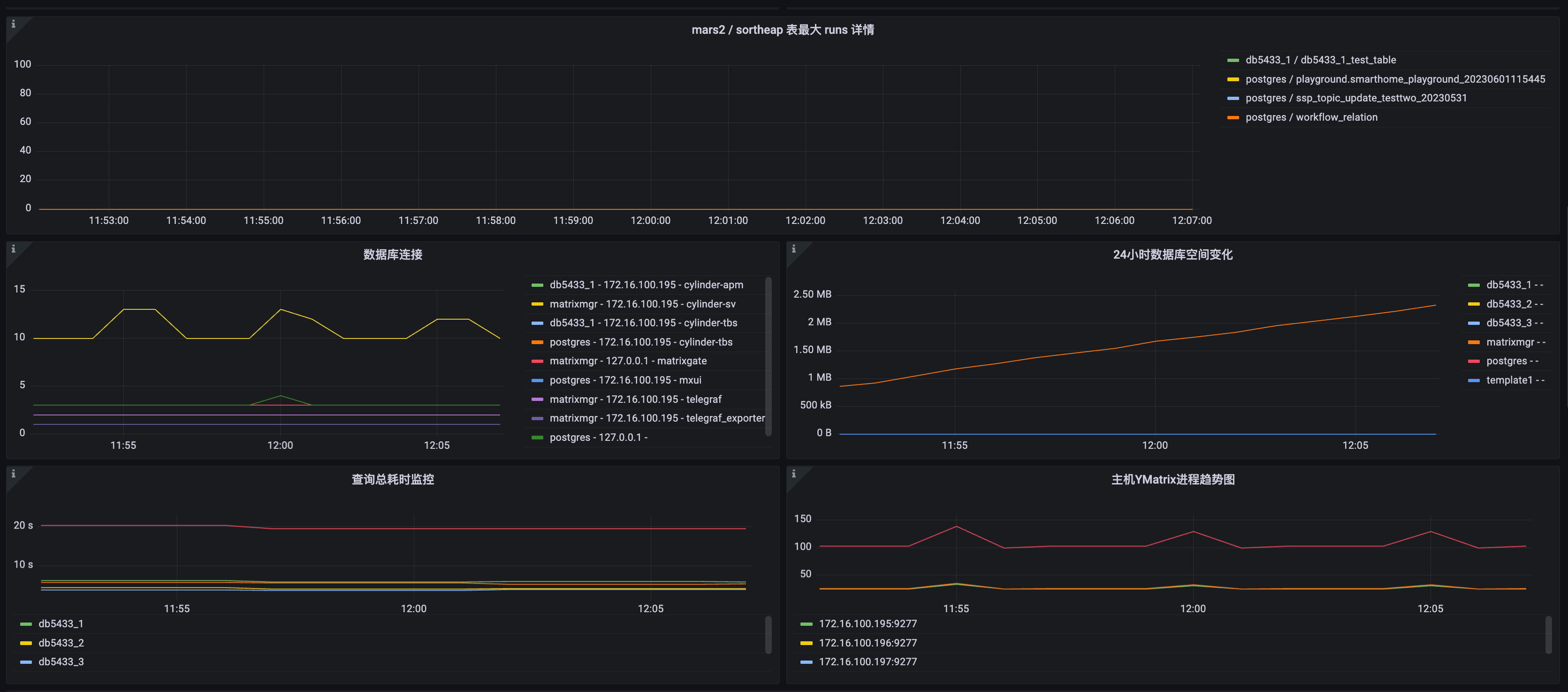
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| mars2 表最大 runs 详情 | MARS2 表 runs 趋势图 | short | ||
| 数据库连接详情 | 按数据库,客户端地址,application_name 分组 | short | ||
| 24 小时数据库空间变化 | 各个数据库 24 小时数据库大小变化 | short | ||
| 查询总耗时查询 | 各个阶段数据库查询总耗时 | millsseconds(ms) | p3 | 按需配置,总时间突变较大时需要关注 |
| 主机 YMatrix 进程趋势图 | 各个主机 postgres 进程总数趋势图 | short |
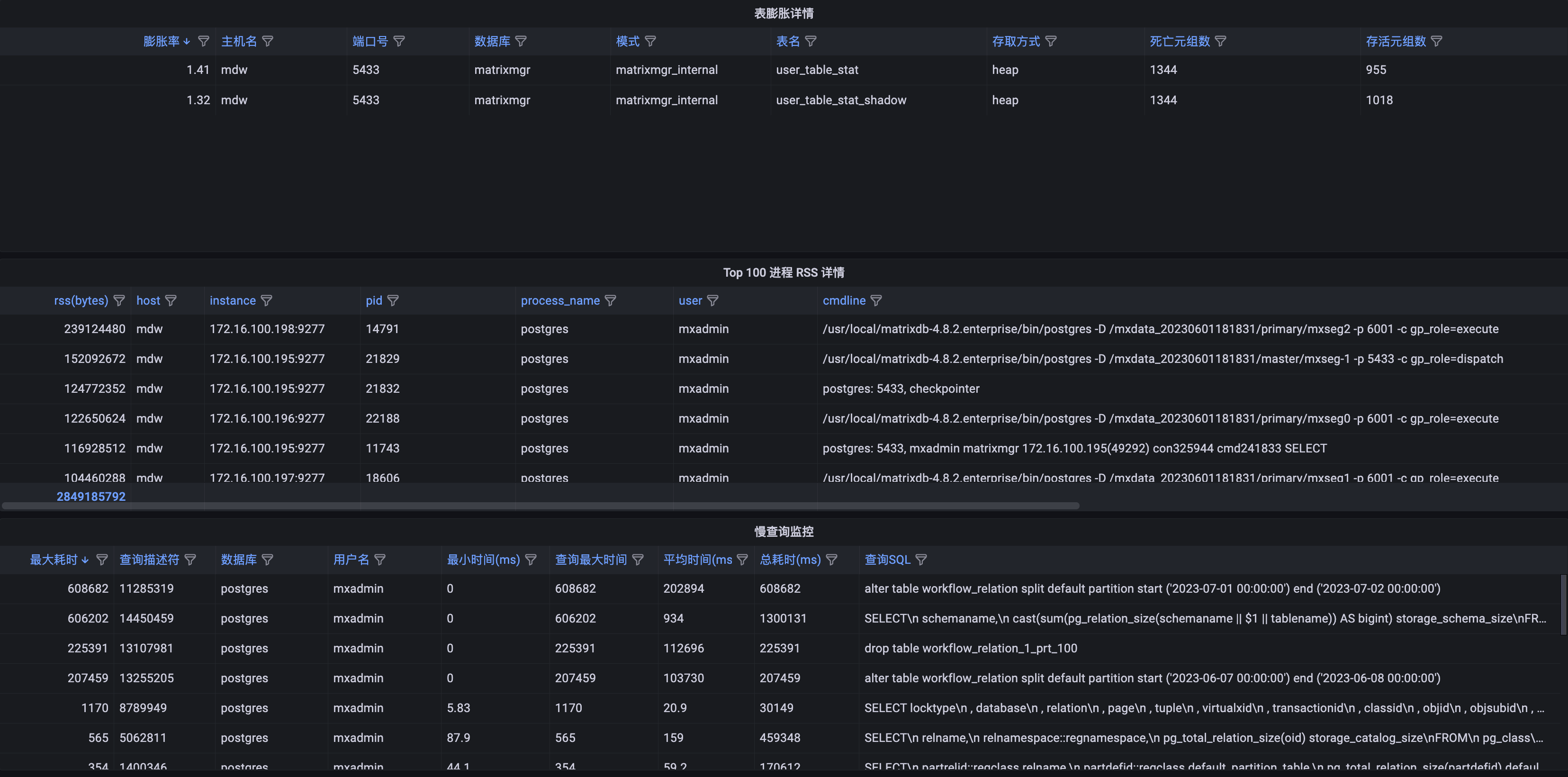
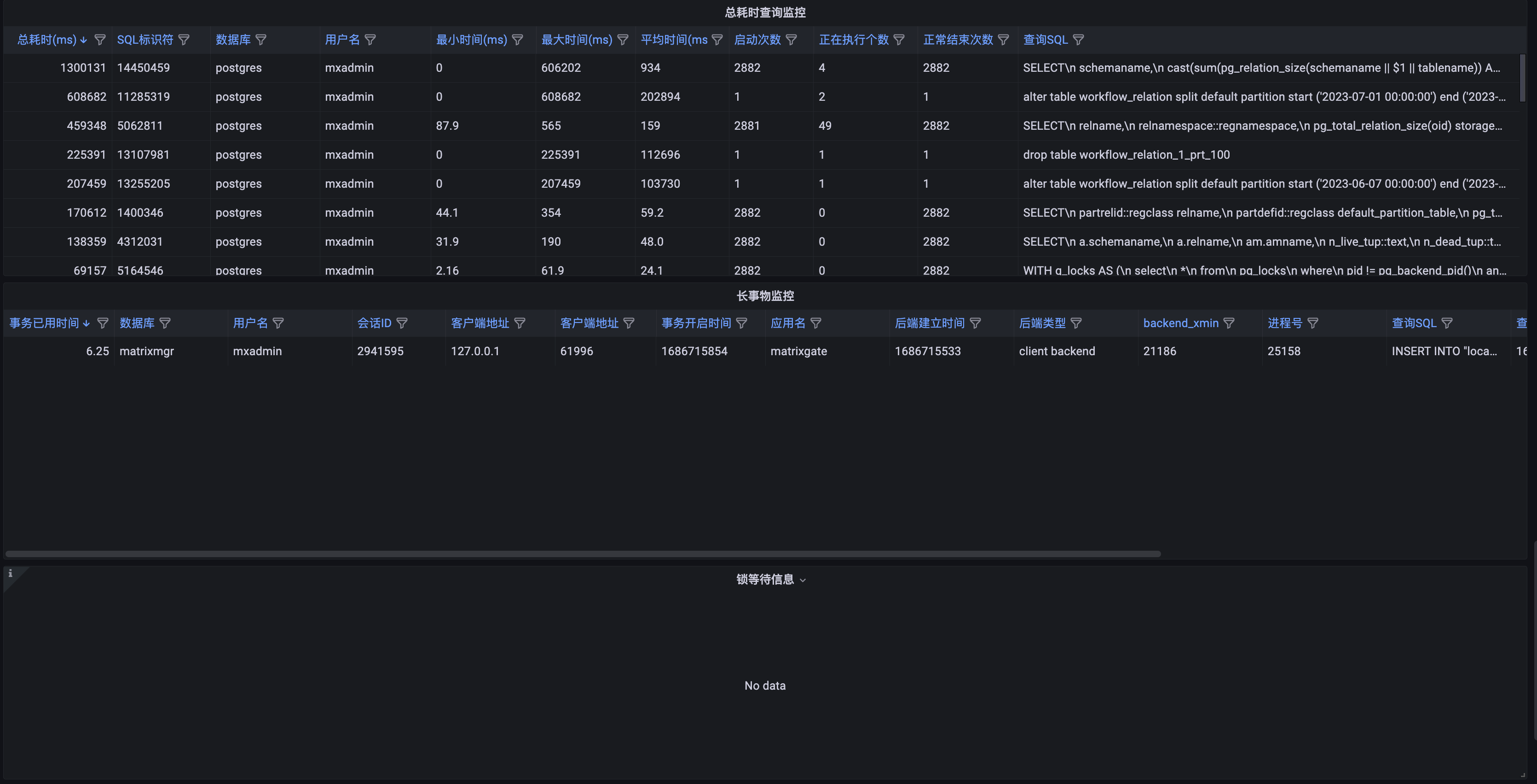
| 指标名 | 描述 | 单位 | 级别 | 参考报警阈值 |
|---|---|---|---|---|
| 表膨胀详情 | 列出 表死亡元组数/存活元组数 > 1.1 的表 | short | ||
| Top 100 进程 RSS 详情 | 按 RSS 排序,列出 postgres 进程占用内存 top 100 | short | ||
| 慢查询监控 | 统计数据库中执行过的慢 SQL | none | p3 | |
| 总耗时查询监控 | 统计 SQL 执行总耗时 | millseconds(ms) | ||
| 耗时统计图(秒) | 统计每五分钟内执行 SQL 总耗时 | millseconds(ms) | ||
| 长事物指标 | 统计 Master/Segment 中长事物详情 | none | p3 | |
| 锁等待信息 | 列出收据信息时刻,数据库锁等待详情 | none | p3 | 按需求配置,可以配置锁超过10min以上的可以告警 |






