

400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
流计算引擎
灾难恢复
系统配置参数
索引
扩展
SQL 参考
常见问题(FAQ)
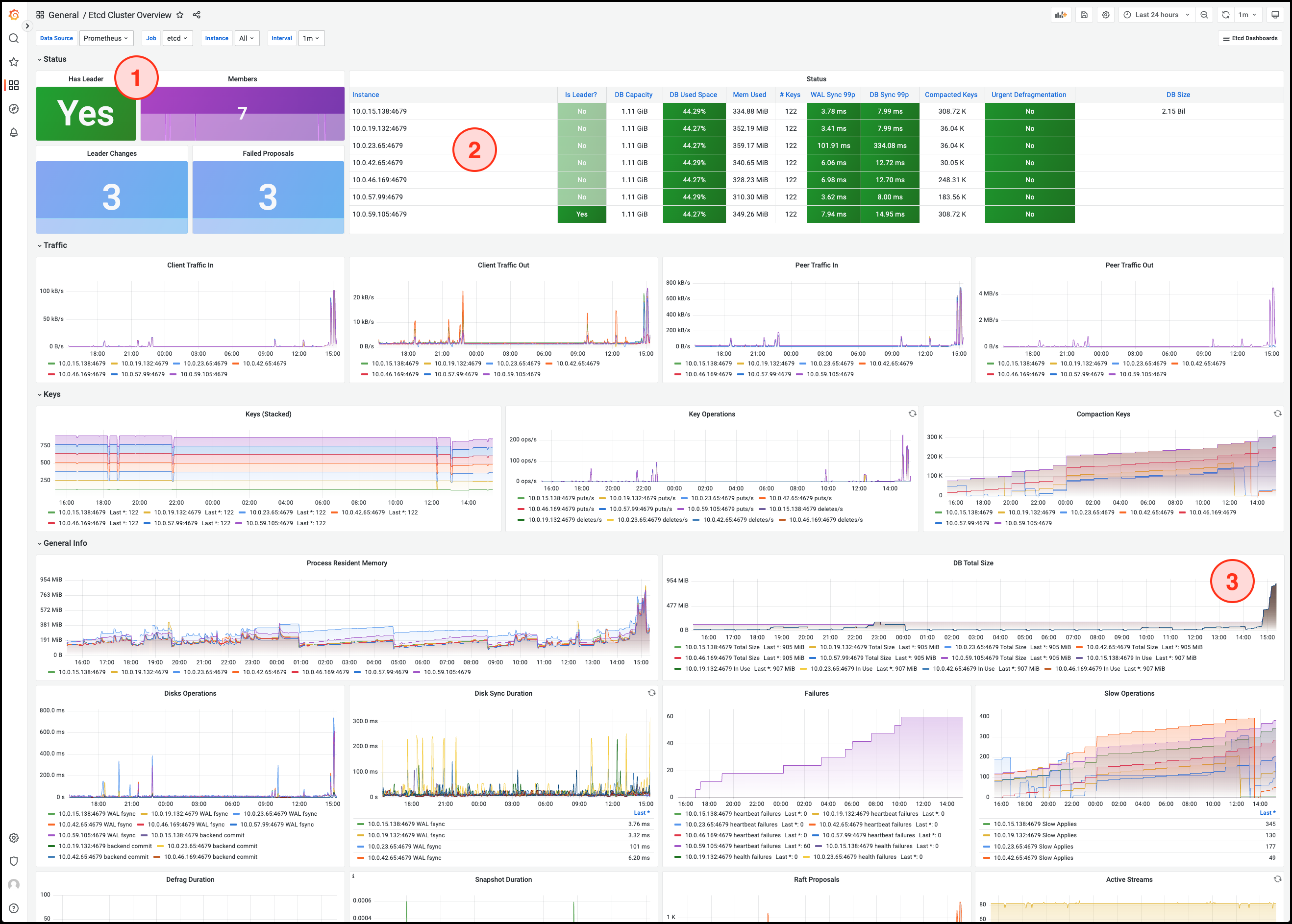
YMatrix 6 引入 etcd 存放集群的配置和状态信息。etcd 非常关键,如果出现异常,会导致数据库的不稳定甚至崩溃。
本文介绍安装和部署etcd监控的方法,推荐生产环境的集群都安装此监控,因为 etcd 状态正常是数据库健康运行的前提。
请进入 Prometheus 官网 下载以下内容:
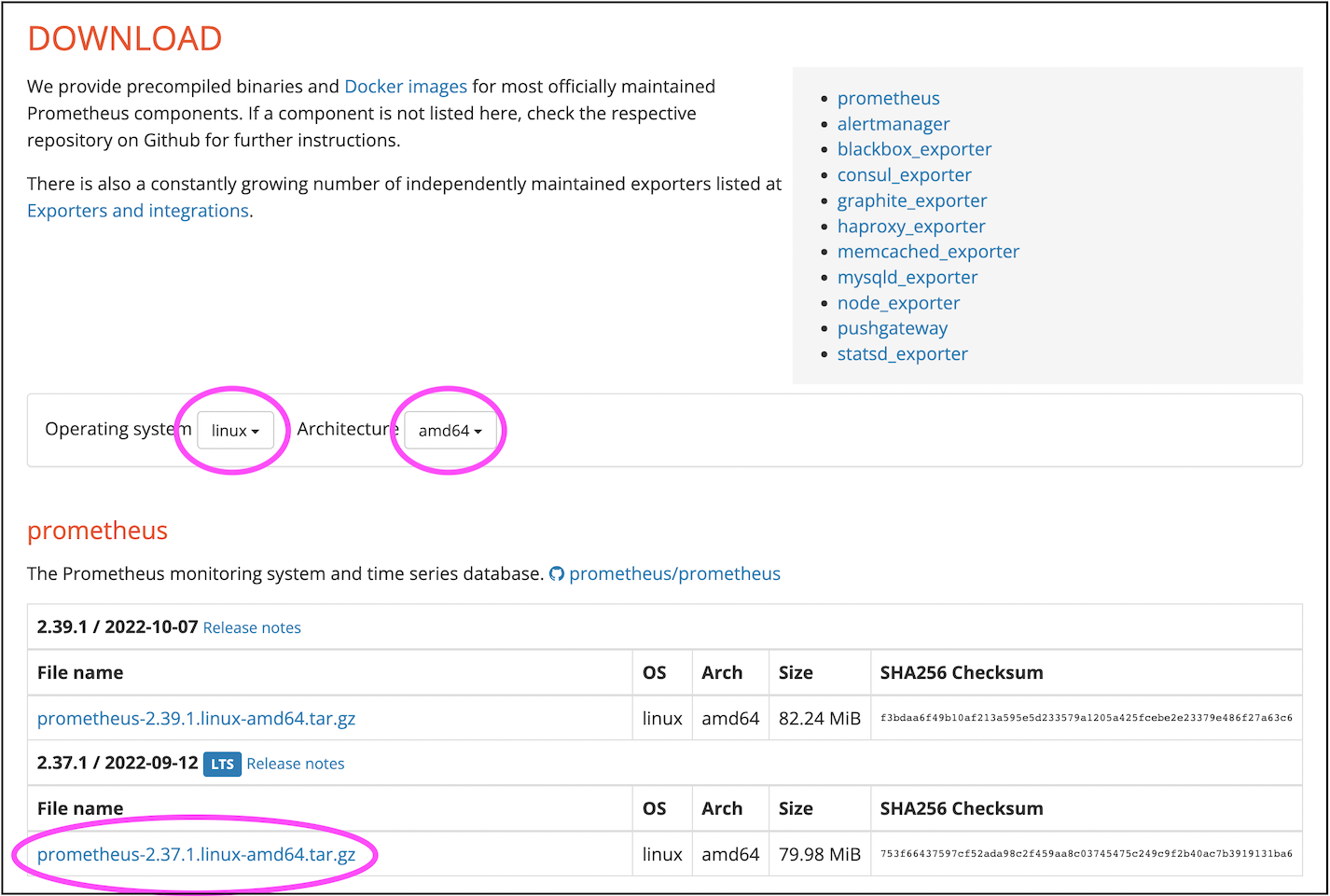
将下载到的 tar 包上传到 Linux 服务器上。如果条件允许,推荐使用单独的服务器运行 Prometheus,如果服务器有限,也可以临时放在主节点备用节点(Standby)或者主节点(Master)主机上。
$ tar xvfz prometheus-*.tar.gz可以将解压出来的 prometheus-* 目录移动到 /usr/local/ 下。
编辑配置文件。
$ cd prometheus-*
sudo vi prometheus.yml在文件末尾,追加如下内容:
- job_name: "etcd"
static_configs:
- targets: ["172.31.33.128:4679", "172.31.45.253:4679", "172.31.35.134:4679"]其中,targets 里是一个数组,需要替换成集群里每一个etcd 节点的地址。
该信息可以在 Master 主机上的 /etc/matrixdb6/physical_cluster.toml 文件中找到。
$ cat physical_cluster.toml
cluster_id = '79LhQxjuwmXgSWZCjcdigF'
supervisord_grpc_port = 4617
deployer_port = 4627
etcd_endpoints = ['http://10.0.159.1:4679', 'http://10.0.172.185:4679', 'http://10.0.170.90:4679', 'http://10.0.146.2:4679', 'http://10.0.146.195:4679', 'http://10.0.150.110:4679', 'http://10.0.169.149:4679']注意!
如果你的主机上没有/etc/matrixdb6/physical_cluster.toml文件,且找不到 etcd 进程,说明你的集群不是用 6.x 架构部署的,不涉及监控 etcd。
./prometheus --config.file=prometheus.yml注意!
通常我们希望将 Prometheus 作为系统服务在后台运行,这需要将其配置为 systemd 服务。
请参照官方文档 安装 Grafana 软件。
注意!
需要安装 Grafana 8.2.5 或更高版本。
首先登陆 Grafana 页面,默认地址如下:
http://<安装节点的IP或者域名>:3000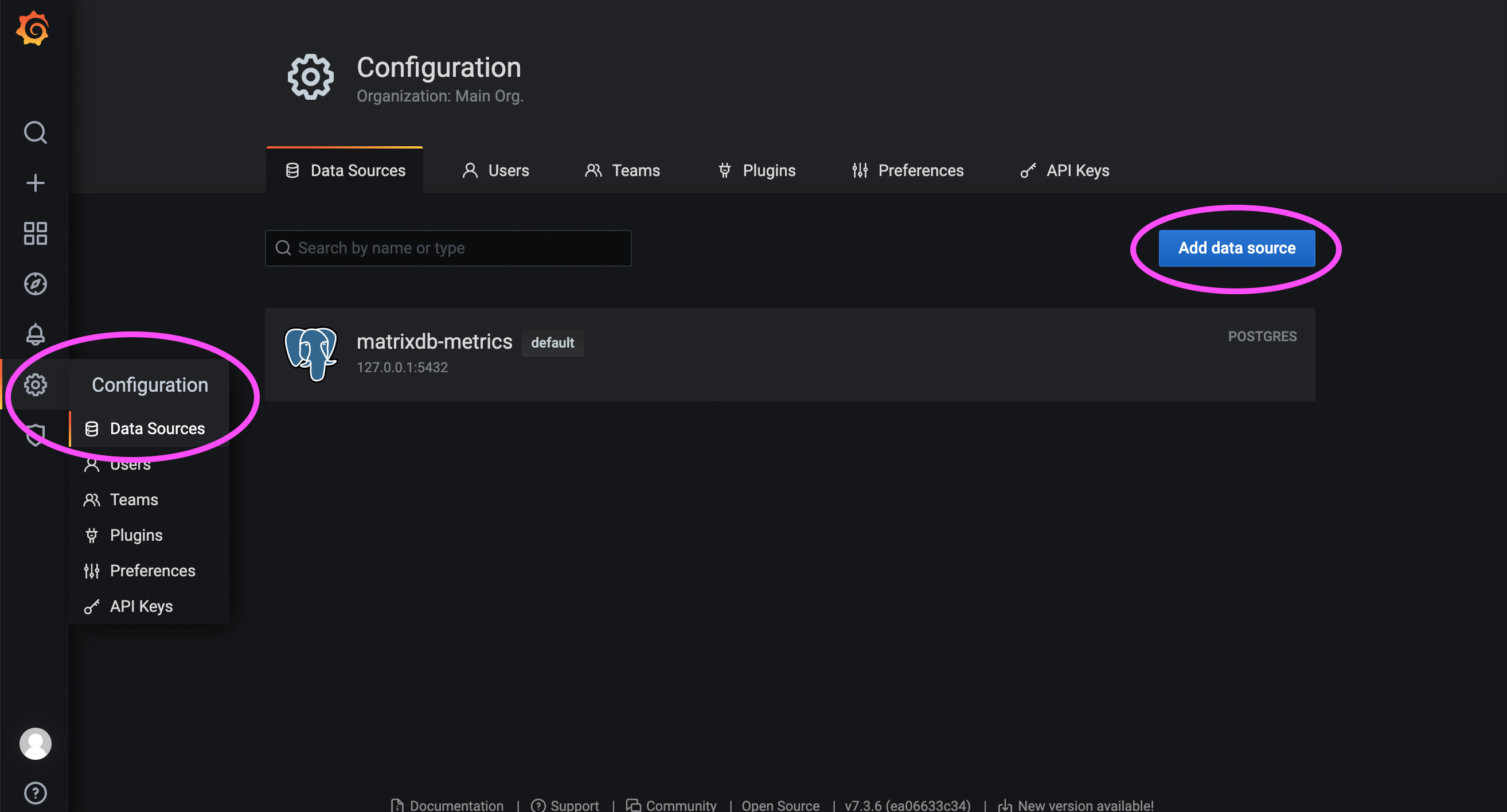
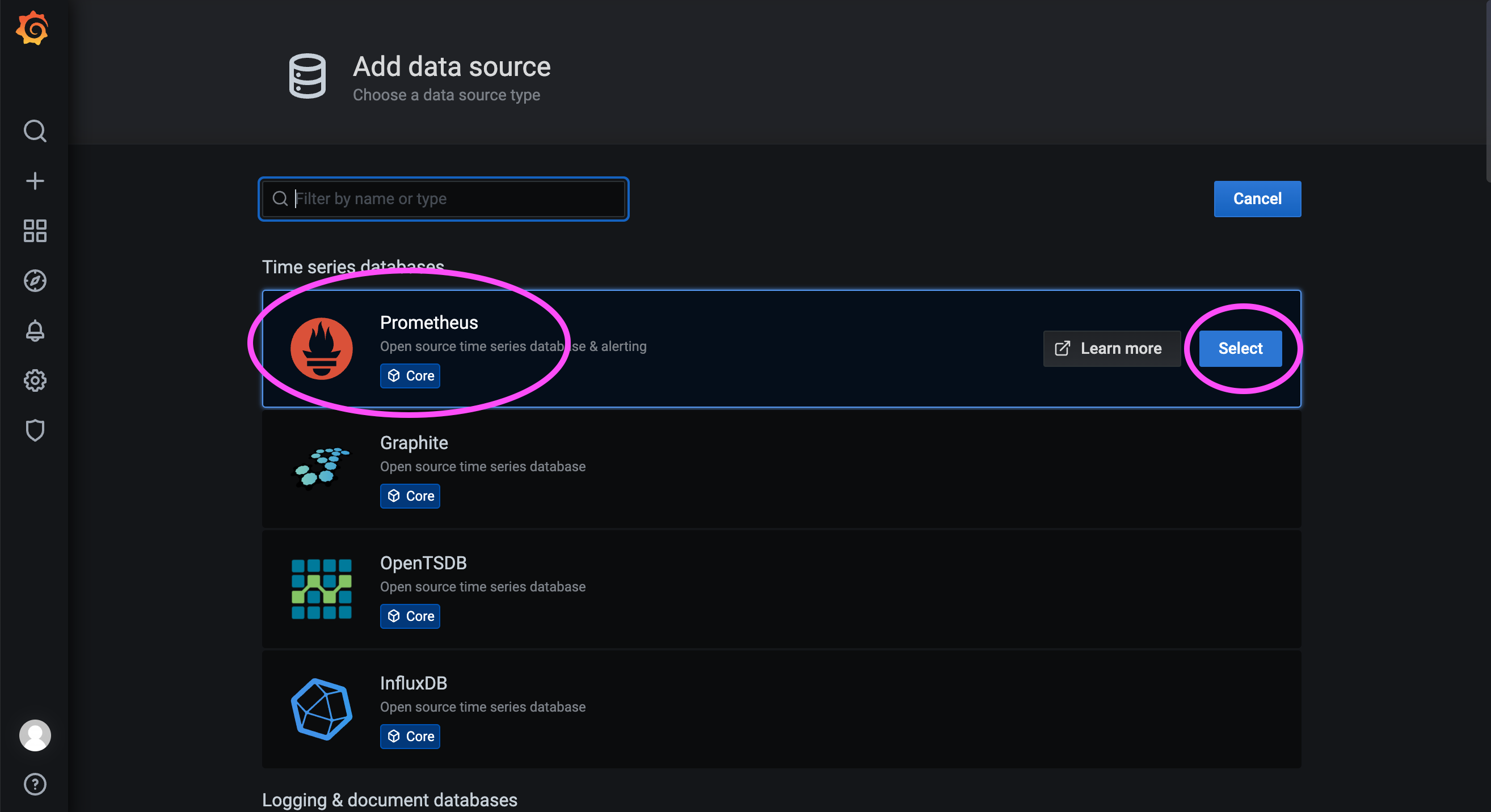

172.31.23.21:9090 是前一步部署的 Prometheus 的服务端口。
访问Grafana社区:
https://grafana.com/grafana/dashboards/?search=Etcd+Cluster+Overview
如上链接可搜索到社区提供的 Dashboard:
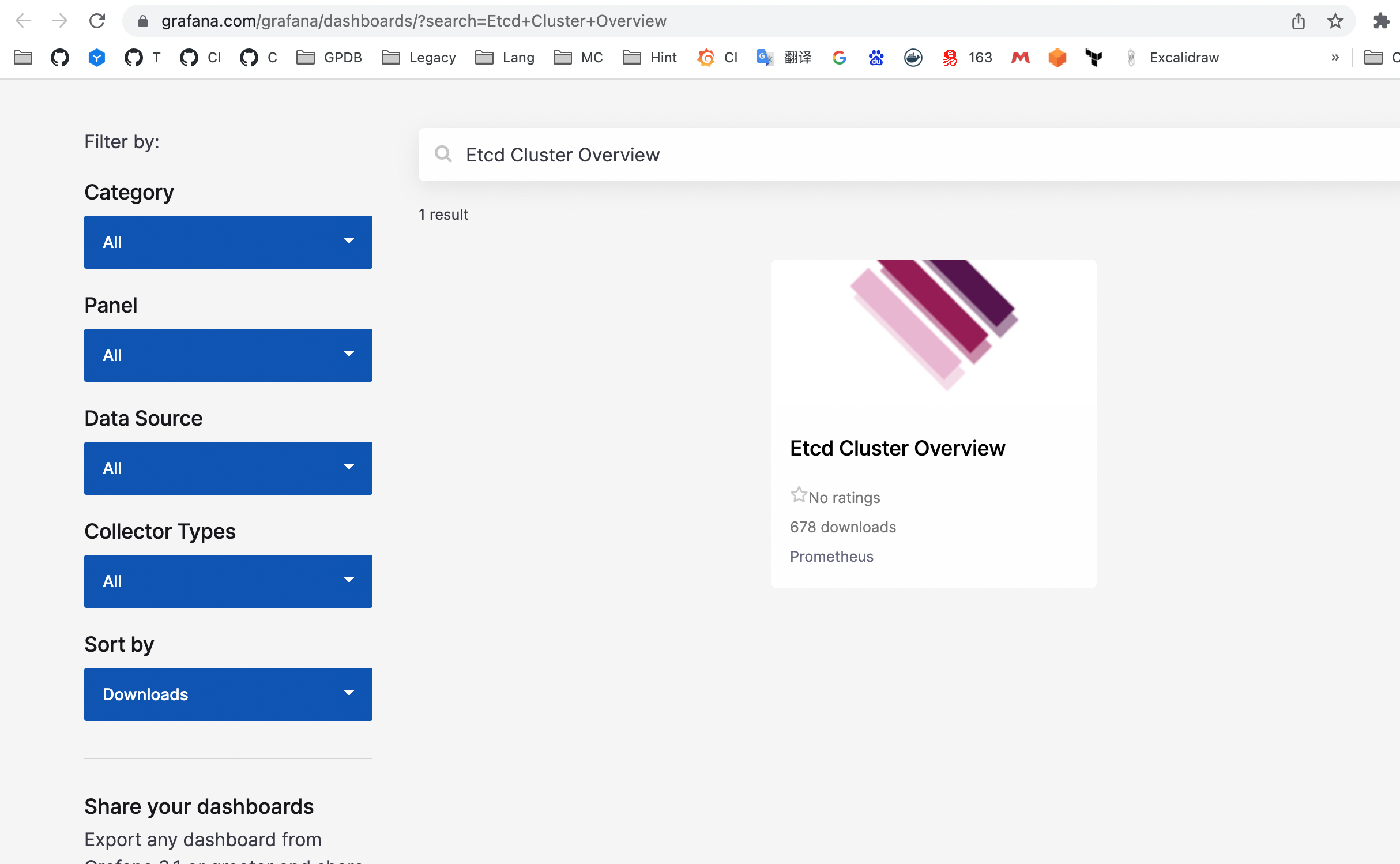
点击进入,获得该 Dashboard 的 ID:
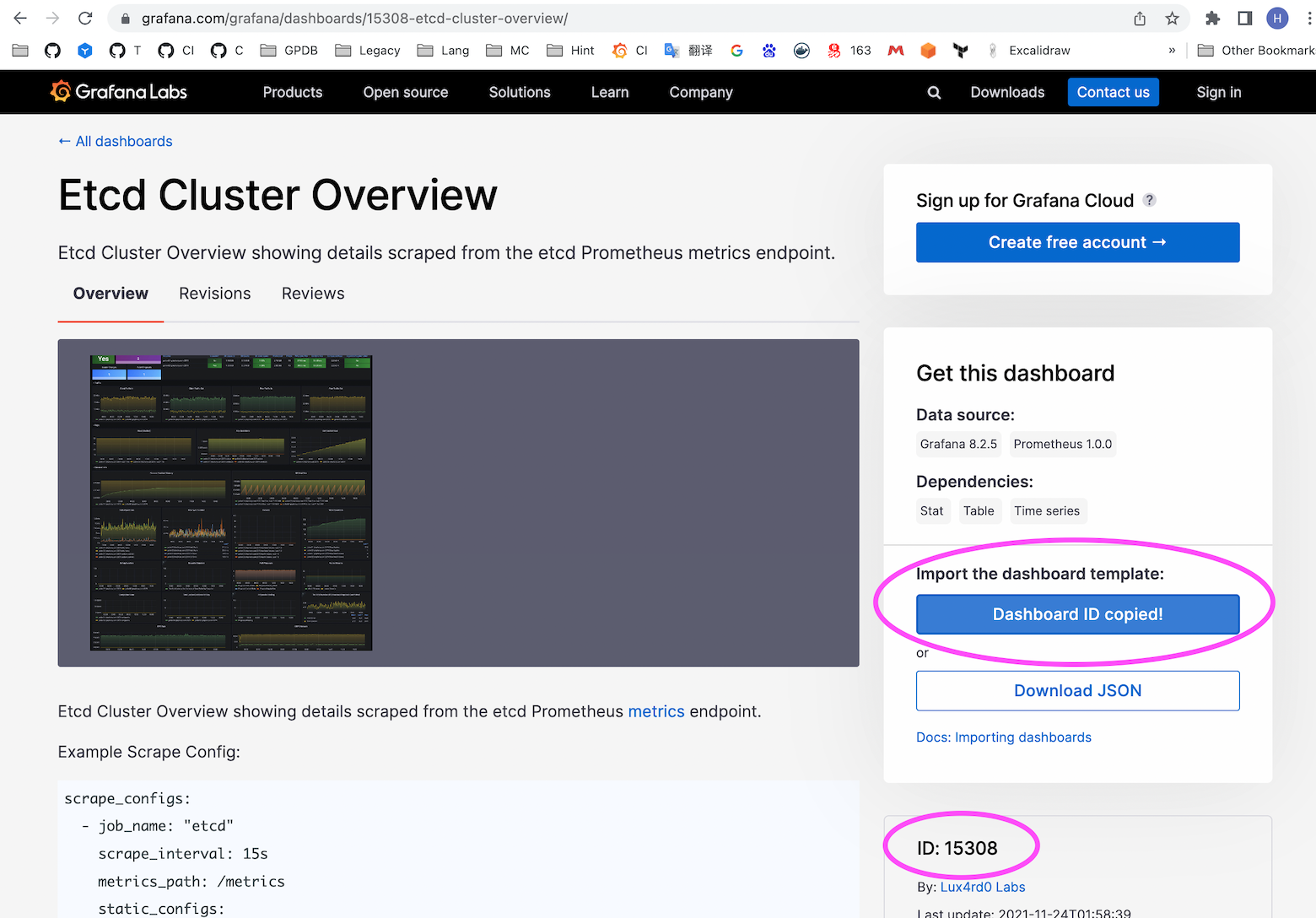
注意!
此 ID 对应的 Dashboard 不排除会发生变化的可能。目前为 15308,用户请以自身搜索结果为准。
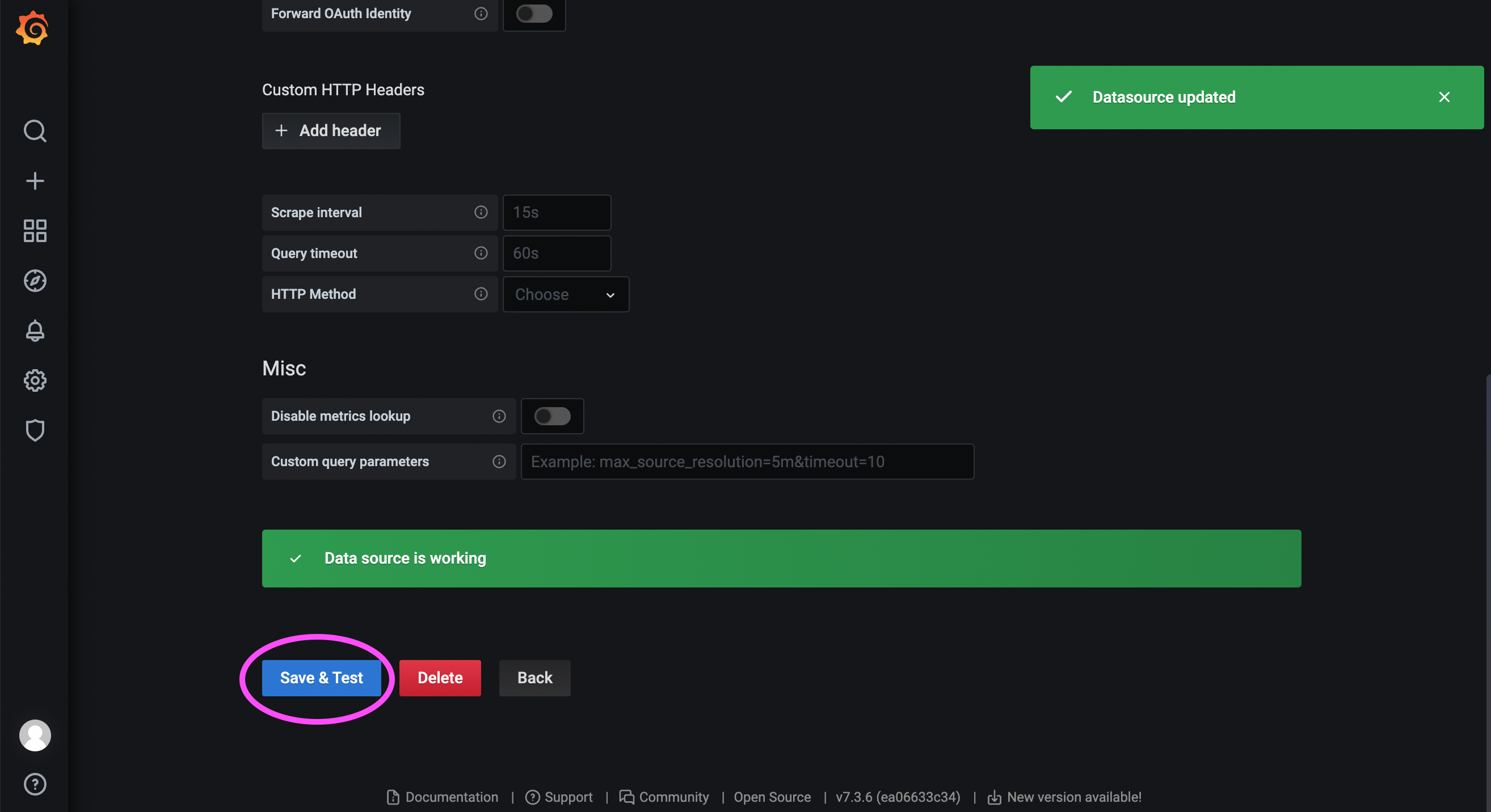
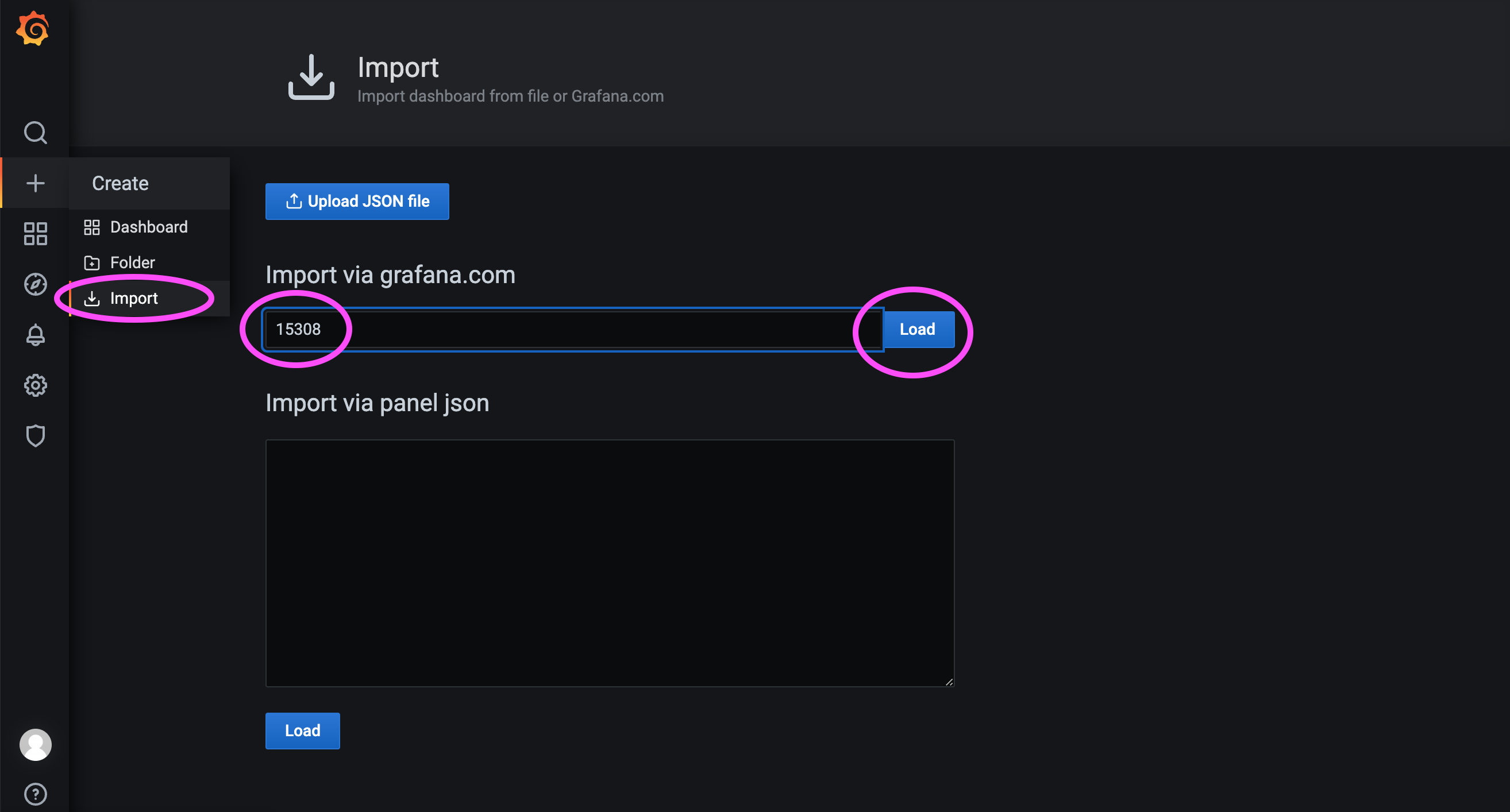
如下图,这里我们导入 15308 号 Dashboard。
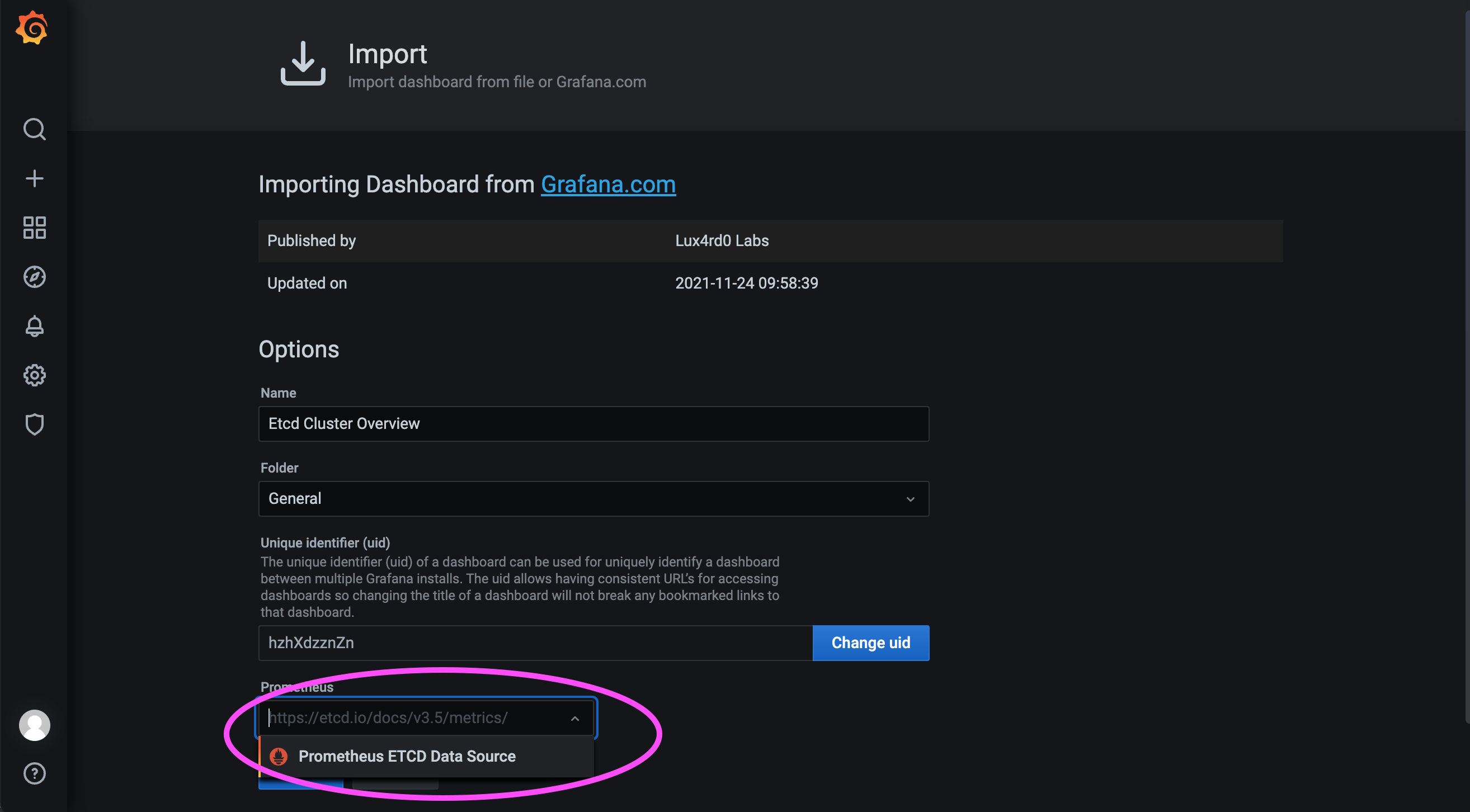
如下图,选择我们刚才配置的数据源名称,最后加载 Dashboard。
如果服务器处于内网,可能无法通过编号 15308 导入。需要在其他可上网的电脑上 下载 Dashboard 的 JSON 文件再导入。
注意!
更多指标和详细介绍,可以参照 etcd 官方文档。



