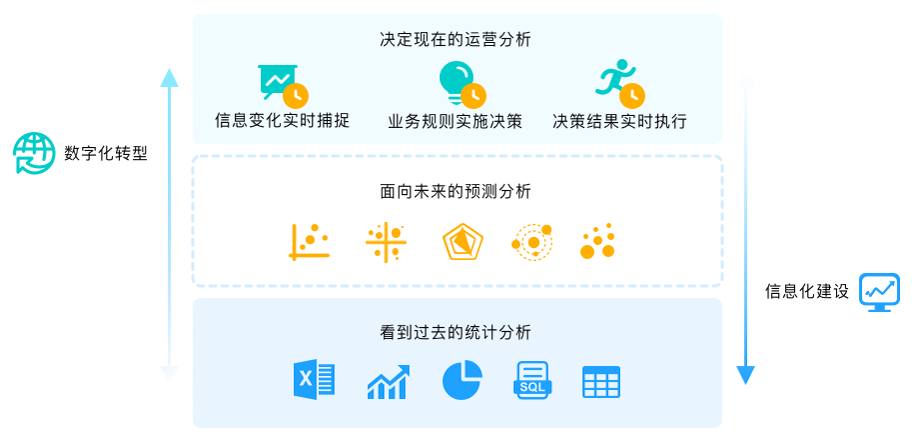
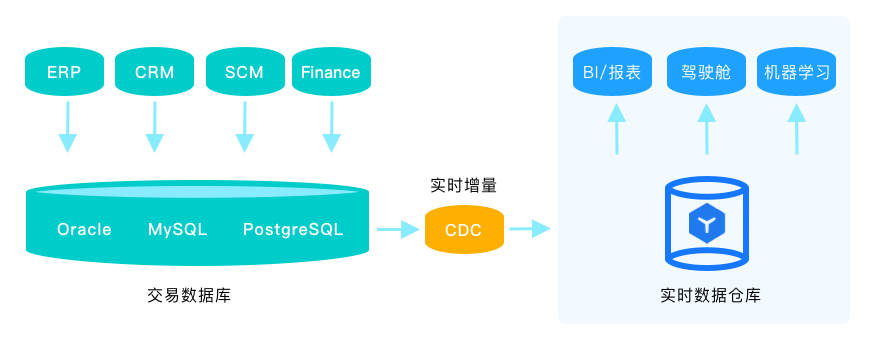
为了更好支持业务实时分析和数据驱动决策,实时数据仓库成为企业数据分析和决策支持的标准配置。相比传统的隔天T+1离线数据分析,实时数据仓库可以在业务交易后立即将数据流式注入数据仓库,实现T+0计算、分析和决策。相比依赖多种产品组件搭积木的方式构建的实时数据仓库,MatrixDB简洁而高效。
基于强大的实时数据处理能力,MatrixDB可以为企业提供全方位的分析能力:
某大型金融机构采用实时数据仓库方案,通过秒级交易数据注入,实现反欺诈反洗钱等合规检查,保护人民财产安全。

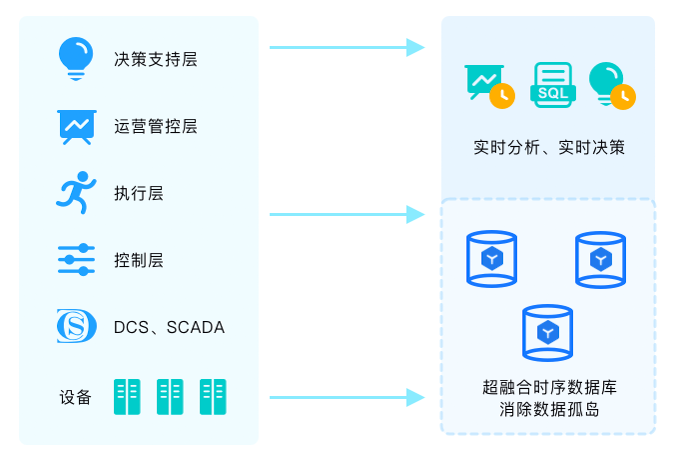
两化融合指技术、产品、业务和产业四个方面的融合,涉及企业生产和运营的方方面面。由于我国工业水平参差不齐,两化融合推行起来比较缓慢。MatrixDB创新性的提出两化数据融合先行战略,从推进IT域数据和OT域数据融合着手,建立对企业的360度感知和管理,进而逐步实现技术、产品、业务和产品的融合。
某大型制造业企业采用MatrixDB打通IT运营域数据(包括ERP、SCM、CRM、人事、财务等)和OT生产域数据(包括设备数据、SCADA、MES等),彻底消除数据孤岛问题和数据质量低下问题,让企业管理者对企业内外部的各种事件了如指掌,进而基于数据进行科学决策。
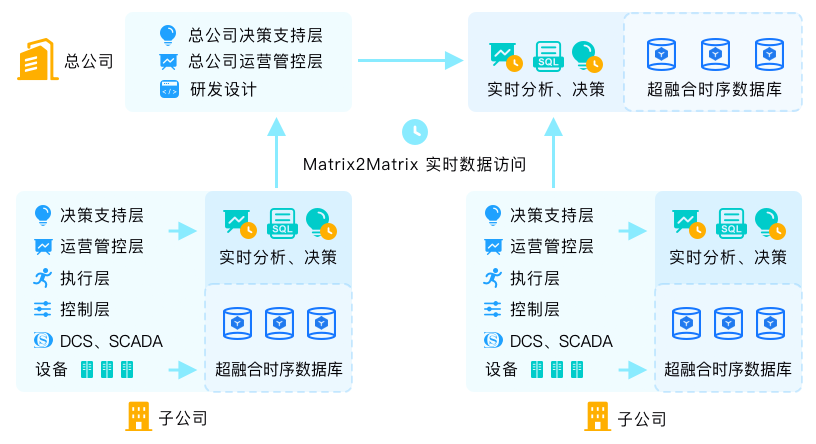
大型企业通常有众多子公司,每个子公司分布在不同城市,这给总公司的管理带来诸多挑战。通过原创的matrix2matrix技术,企业总部可以对各个工厂数据了如指掌,从而进行及时高效的管理,大幅提升了企业效率,降低了生产管理运营成本。
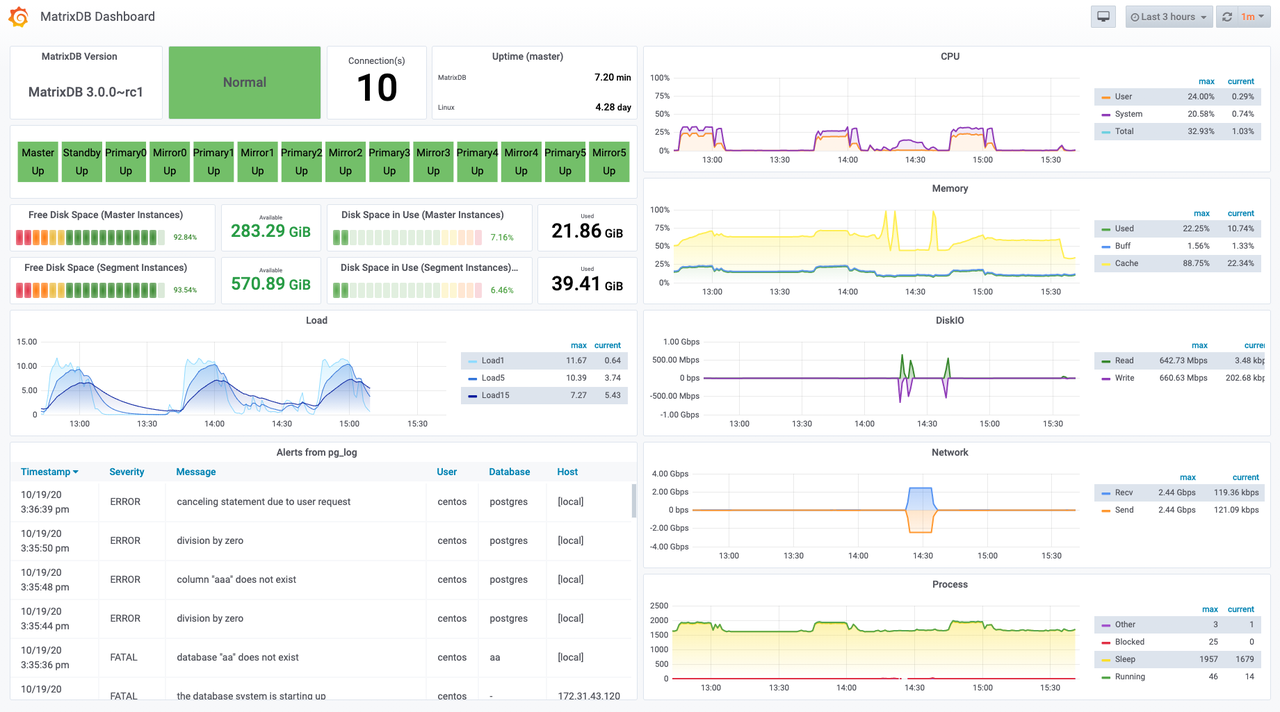
目前运维主要以实时数据为主,使用telegraf、普罗米修斯、grafana、Zabbix作为套件,底层存储多使用内存、PostgreSQL、InfluxDB等数据库,主要问题是无法支持海量数据的存储、查询和分析。
MatrixDB提供了开箱即用的智能运维方案,不仅可以存储和查询监控相关的指标、事件、日志等度量数据,也可以管理服务器、网络、后台服务等元数据、运营数据同时进行融合分析,捕捉系统变化的所有细节,为问题根因分析、预测性维护以及运维流程改进提供了数据依据。
集群的数据扩展和监控对象扩展能力可以支撑成千上万不同软硬件的监控和分析,可定制的监控面板提供了不同场景需要的可视化表示,是数据中心和运维团队的得力助手。
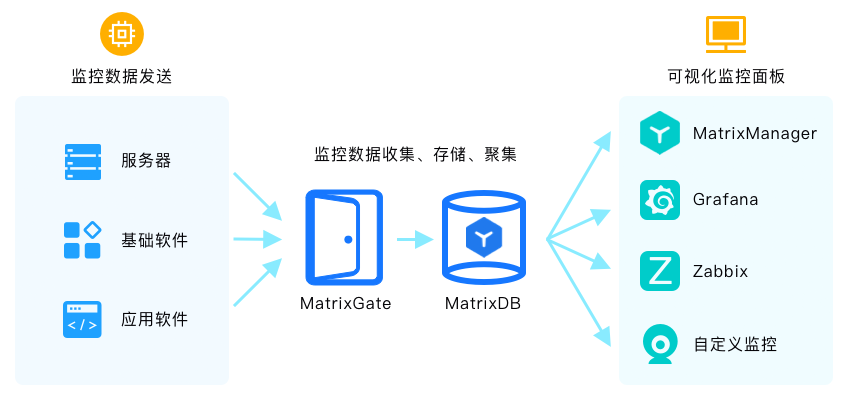
也可以将MatrixDB作为可扩展的监控和设备数据存储模块,无缝对接第三方的可视化产品,例如Zabbix和Grafana,或者是通过应用程序标准接口JDBC/ODBC和自行开发的监控管理工具集成。
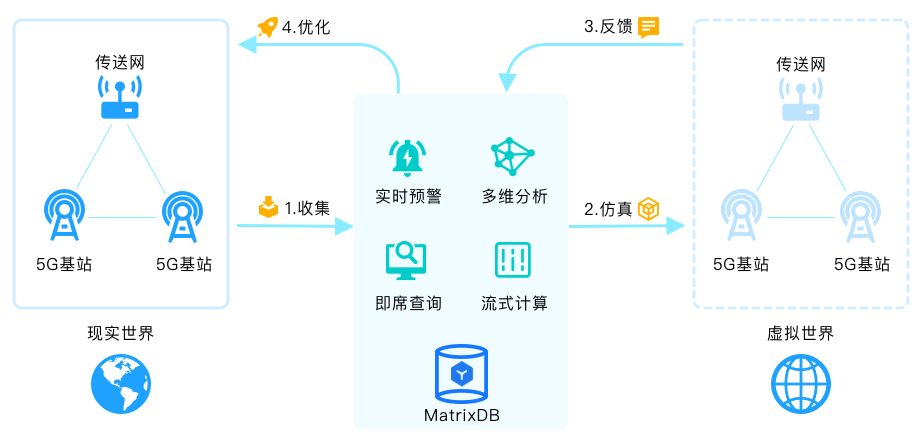
5G是新一代的信息通信的核心,随着5G的发展,网络设备会生成海量时序数据,通过近实时全方位的数据采集,形成实时的网络数字拓扑,构建数字孪生。在数据库内并行对数据进行清洗,借助机器学习,对遗漏数据、噪声数据和不一致数据及时识别和处理,进行深度分析,流程优化。优化的过程可以在数字孪生的模型中迭代实验,快速反馈效果和问题,将筛选出的成熟优化方案应用到产品设计、制造和运营中。
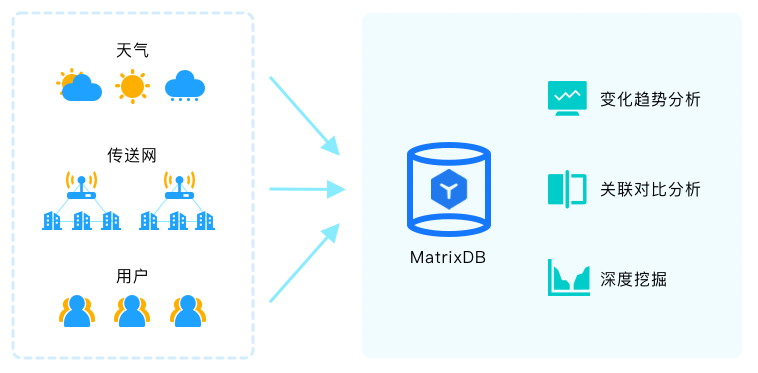
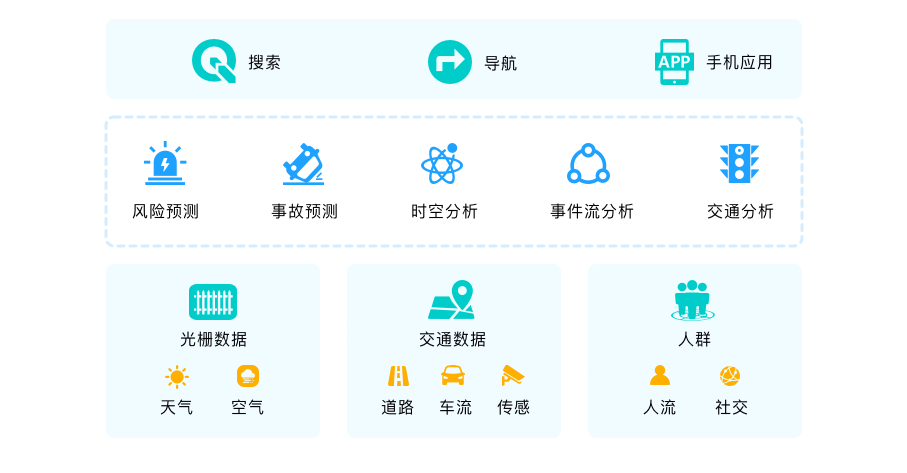
现代都市人、车、设备等每天都产生大量数据包括各种传感数据,这些数据的收集和及时分析可以帮助城市管理更加高效、智能。通过接入不同设备、应用的不同格式的数据,为城市管理提供实时全景视图,为智慧交通、智慧教育、智慧社区、智慧医疗等方方面面提供简单易用而又功能强大的数据支撑。
以城市供电和家庭用电为例,可以收集来自传送网和家庭用电数据,结合当地的天气状况,分析电损、用电模式、窃漏电等众多信息,帮助改进电力规划、传送和管理。
某国政府利用PostGIS、时序组件、文本模块等各种特性,实时汇集地理信息、传感数据、交通、天气等各种异构数据,利用数据库内机器学习,及时预测极端天气对区域交通的影响,取得了非常好的社会效果。
越来越多的物联网应用开始进入实际应用,物联网应用往往需要同时处理很多结构化半结构化的元数据和时序数据,现在的方案大多是同时部署使用关系数据库和时序数据库,如果需要进行高级分析时,往往还需要一个分析型数据库,为支持一个物联网应用程序而引入这么多种数据库,给开发和运维带来很多挑战,需要学习和管理多种数据库、使用不同的接口和语法、数据之间的同步和关联给整个系统带来额外的负担,也引入了许多不确定性。MatrixDB创造性的可以在一个数据库内同时支持设备等元数据、指标类时序数据、高效的增删改查、复杂的分析和深度的机器学习,可以极大的简化系统架构和加速应用开发部署过程。
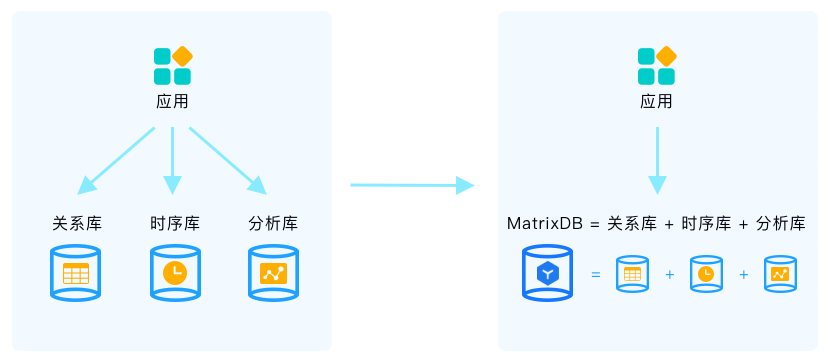
MatrixDB基于PostgreSQL,兼容流行的开发调试和数据库访问操作工具,开发者可以驾轻就熟,快速迭代。MatrixDB可靠稳定,集群方案成熟,在应用需要时可以自然的扩展到大规模集群支撑大量用户和设备的数据访问。
用户行为分析对于安全管理和改进产品至关重要,网站和应用提供了丰富的用户交互界面,用户和应用的互动产生了大量的日志和数据,通过对这些数据的有效分析,借助用户画像、漏斗分析、多维分析、关联分析等技术,帮助运营者深层次挖掘用户需求,为产品演进、运营和推广决策提供全面的数据支撑。产品具有的实时入库、实时统计、快速的即席查询、强大的复杂SQL能力,支持Python存储过程,使得这一方案在用户行为分析场景中广受欢迎。
热门应用会面临用户、数据和维度爆炸的挑战,当有数亿用户和设备、需要分析超过5000个维度、成百上千个分析师同时交互式查询分析时,许多系统就会不堪重负,MatrixDB以其可扩展的计算和存储、高效的性能,轻松胜任这样的需求。
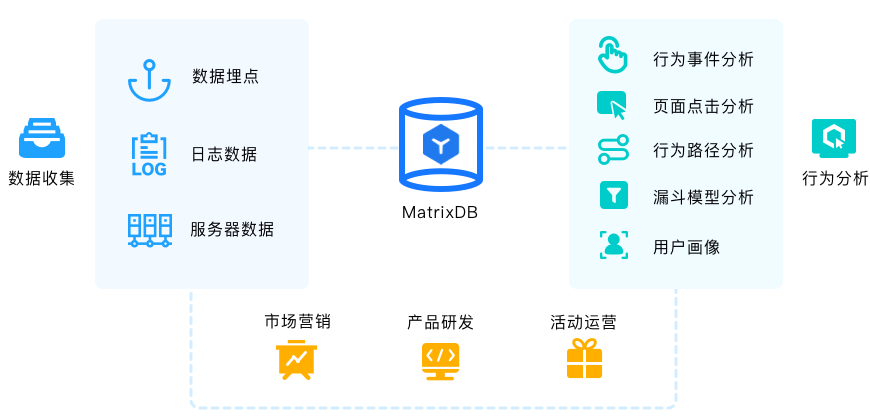
国内一线互联网公司在一个小规模的集群中,就可以每天实时处理几十亿的数据量,通过SQL完成所需要的全部分析需求,完善的工具也让系统的运维管理轻松很多。






