MatrixDB支持kafka无缝连接功能,可将kafka数据持续自动导入到MatrixDB表中,并支持图形化操作。
接入的数据格式包括CSV和JSON。本节将以一个最简单的例子,来介绍如何用MatrixDB管理平台来接入Kafka数据。
假设我们在本地9092端口启动了Kafka服务,通过下面命令创建一个测试Topic:
bin/kafka-topics.sh --create --topic csv_test --bootstrap-server localhost:9092然后写入几个测试数据:
bin/kafka-console-producer.sh --topic csv_test --bootstrap-server localhost:9092
>1,Beijing,123.05,true,1651043583,1651043583123,1651043583123456
>2,Shanghai,112.95,true,1651043583,1651043583123,1651043583123456
>3,Shenzhen,100.0,false,1651043583,1651043583123,1651043583123456
>4,Guangxi,88.5,false,1651043583,1651043583123,1651043583123456
>^C通过上面命令向新创建的csv_test写入了4条数据,分别为4条逗号分割的CSV行。
连接数据库mydb:
[mxadmin@mdw ~]$ psql mydb
psql (12)
Type "help" for help.
mydb=#创建测试表:
CREATE TABLE csv_table (
id SERIAL,
no INT,
city VARCHAR(45),
score DOUBLE PRECISION,
create_time TIMESTAMPTZ
) DISTRIBUTED BY(id);准备工作完毕,下面演示如何使用图形化界面做接入。
在浏览器里输入MatrixGate所在机器的ip(默认是mdw的ip)、端口和datastream后缀:
http://<IP>:8240/datastream进入到如下页面,然后点击“下一步”:
从页面上边的导航栏可以看到整个过程分6步:连接、选择、解析、配置、映射、提交。
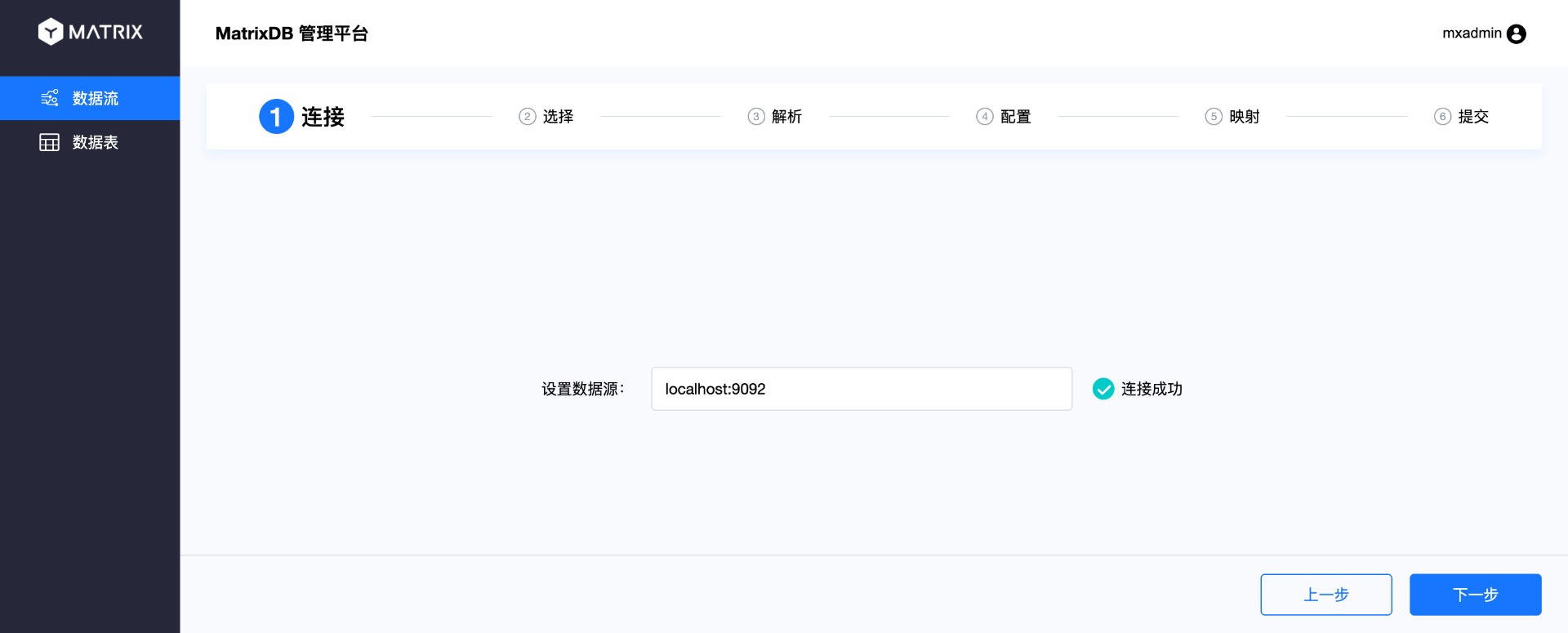
当前进行的是第一步:连接。在数据源里输入Kafka服务器地址,然后点击“下一步”。
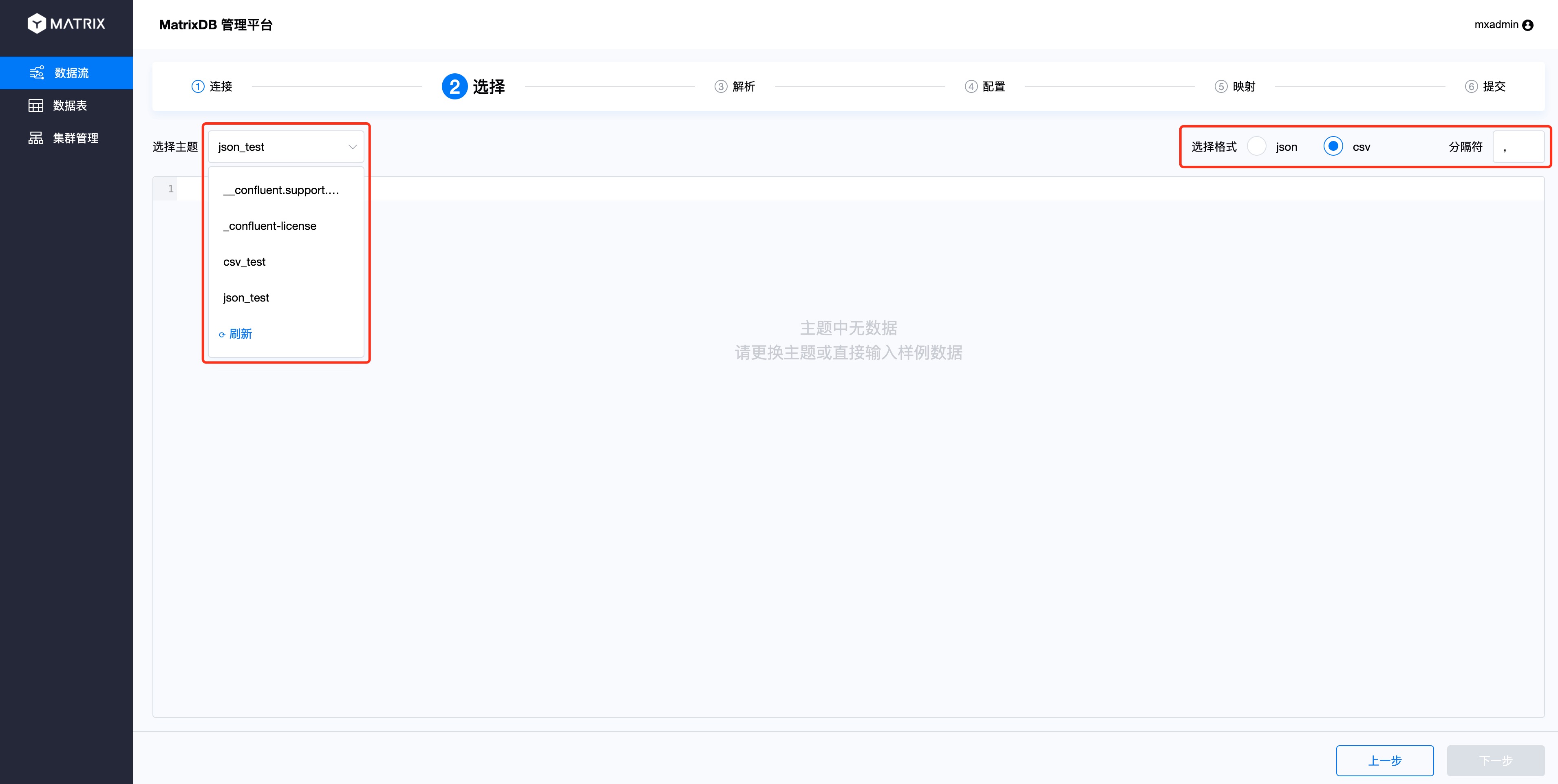
选择界面选择Kafka的Topic,这里选择刚才创建的csv_test Topic。同时右边选择Topic对应的格式,CSV格式还需要指定分隔符。
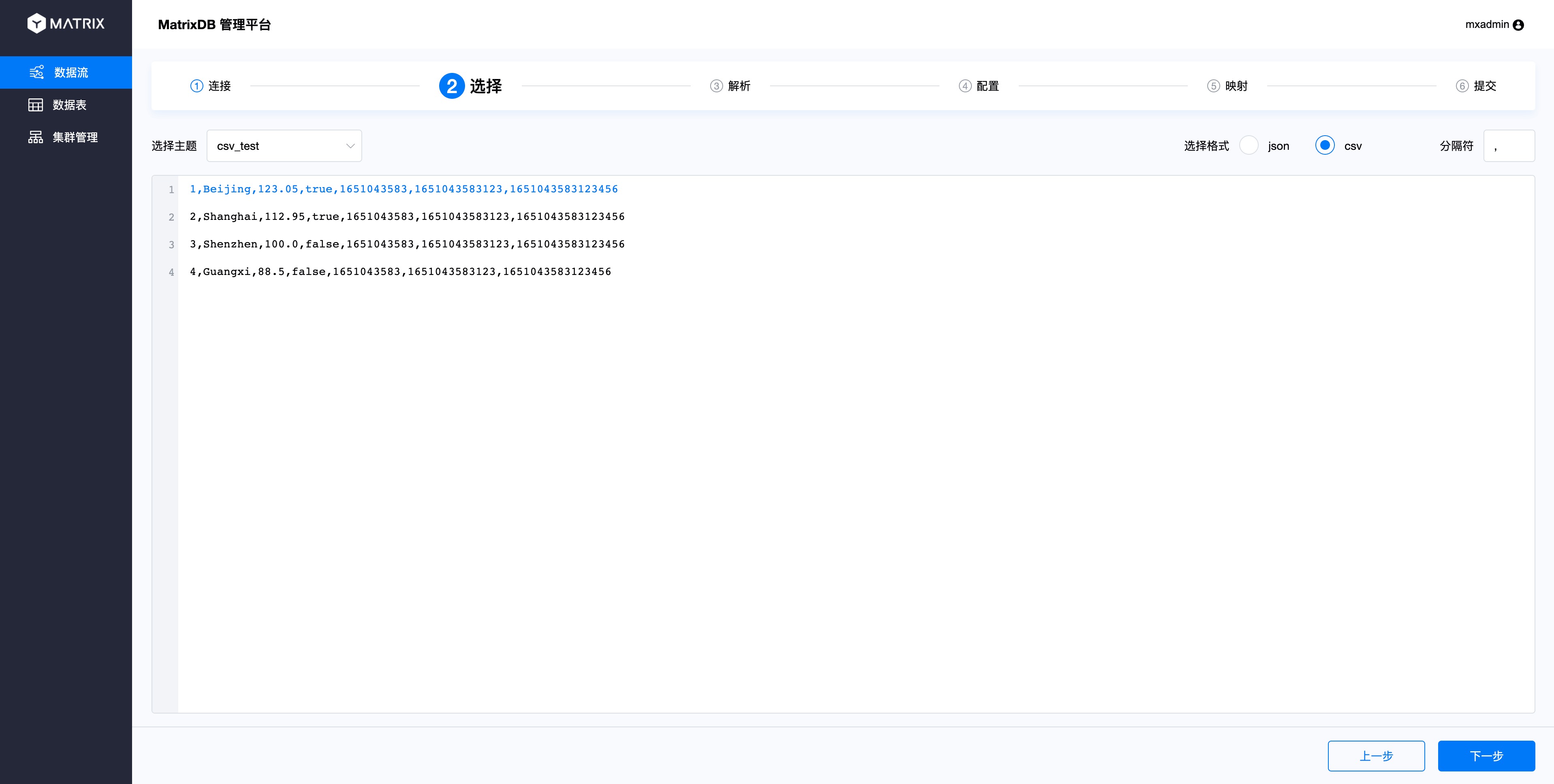
选择好Topic后,会看到Topic里的数据。默认会选前10条作为样例。因为我们只向Topic里写入4条,所以这里可以看到全部4条数据。选择其中一条来做后面的解析和映射。
解析页面会对刚才选择的样例数据进行解析,在右边会看到通过分隔符分割后的索引号和对应的值。确认无误后点击“下一步”:
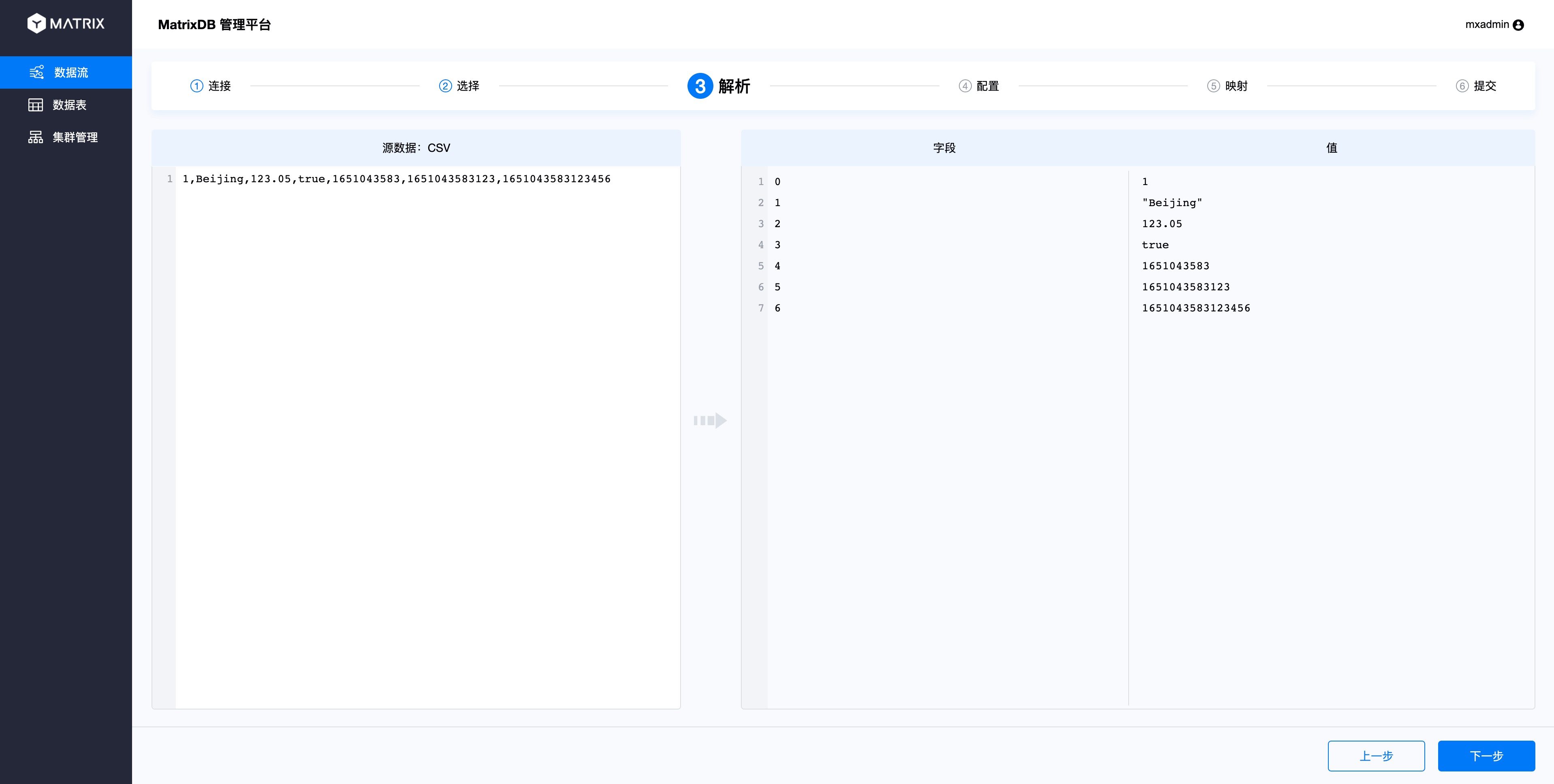
配置页面中,选择该Topic的数据接入到哪个目标表,自行选择数据库、模式和表后,会展示出表结构以及选择插入模式。
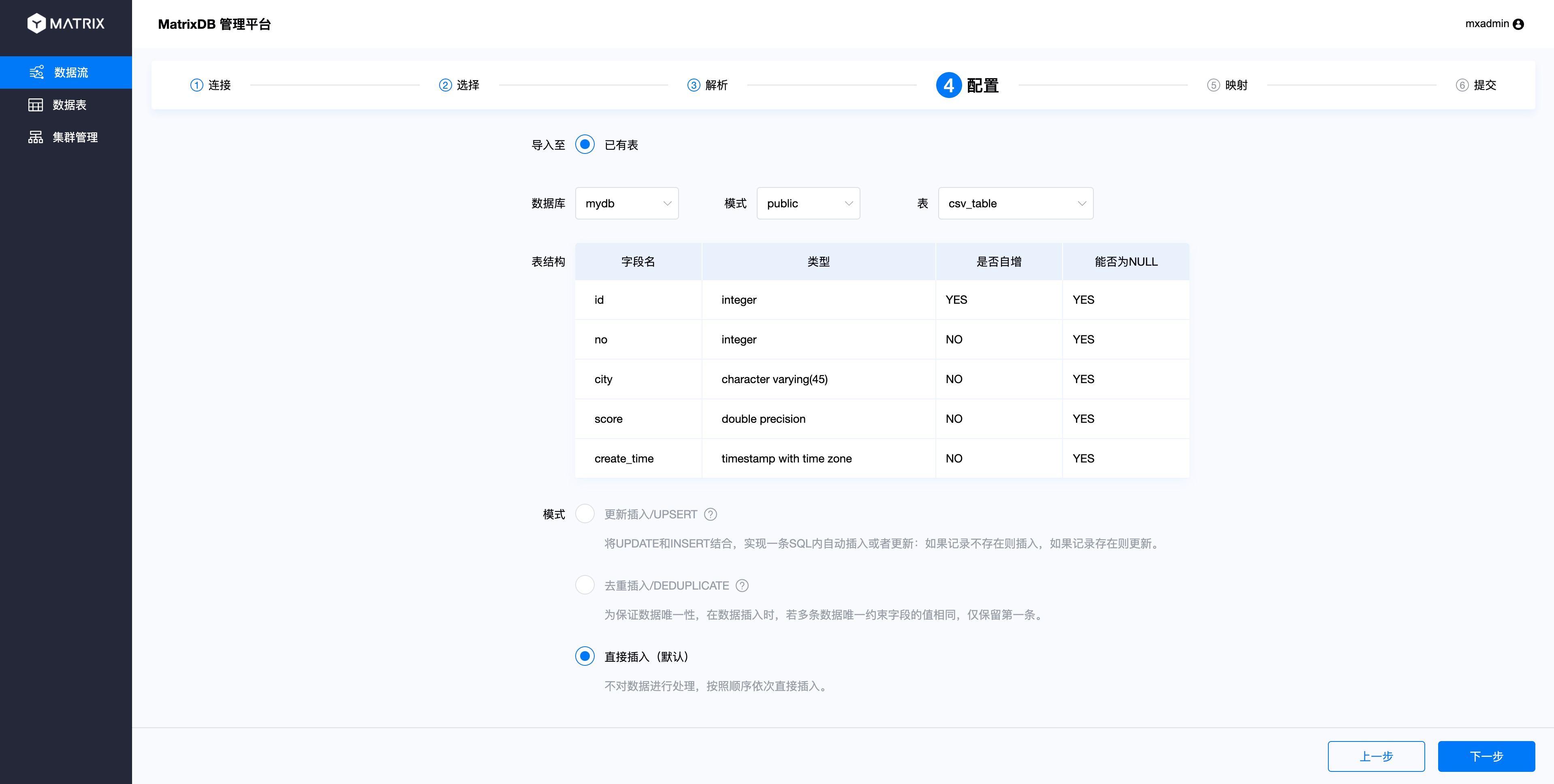
映射页面进行源数据与目标表的映射,即CSV列与数据库表列的映射。操作过程为从源数据中选择一列,然后在目标表中选择映射的列。这样,在右边的映射规则中会出现一条新的映射规则,确认后点击保存。
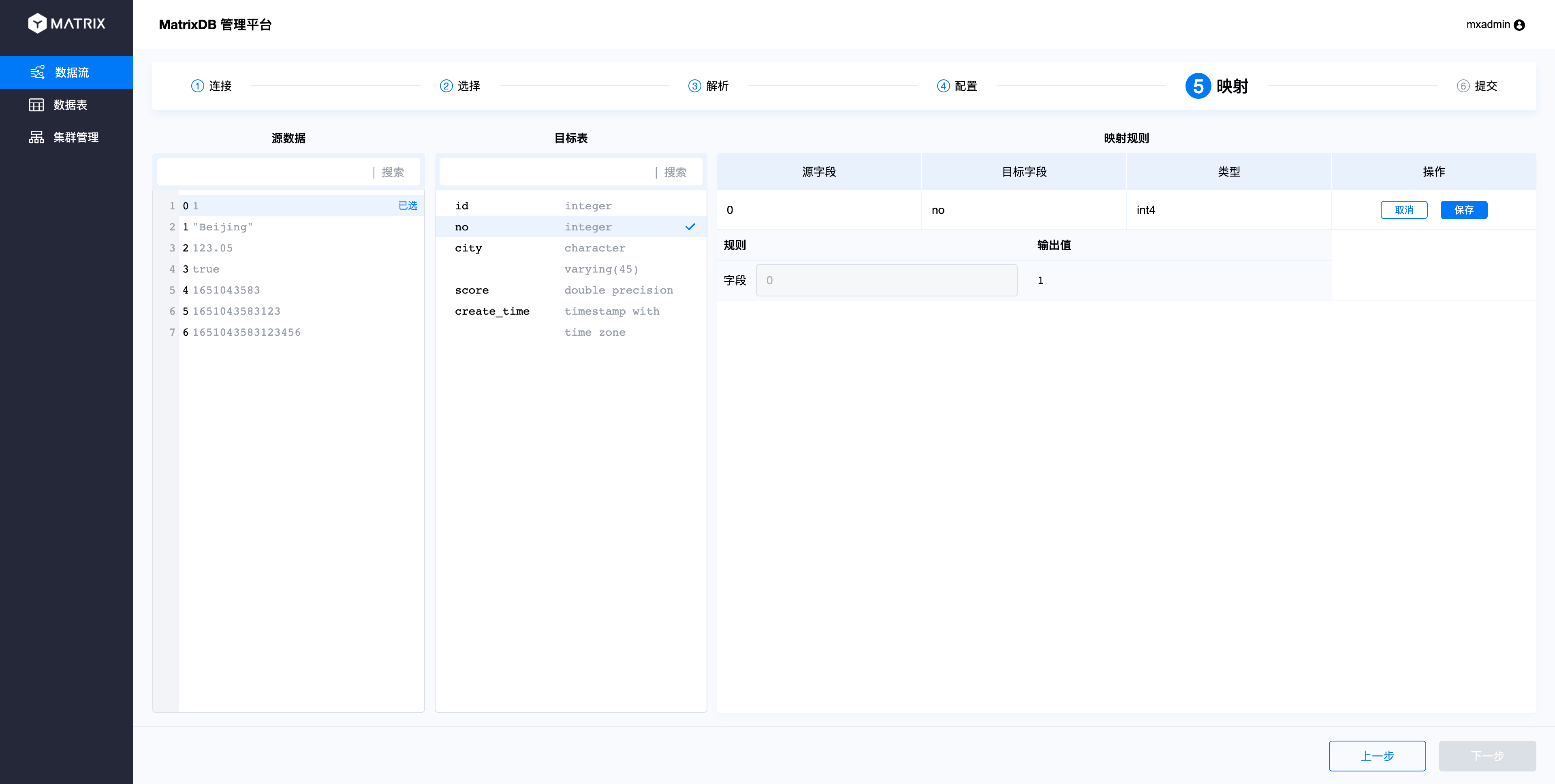
按照这个步骤将所有列完成映射即可。
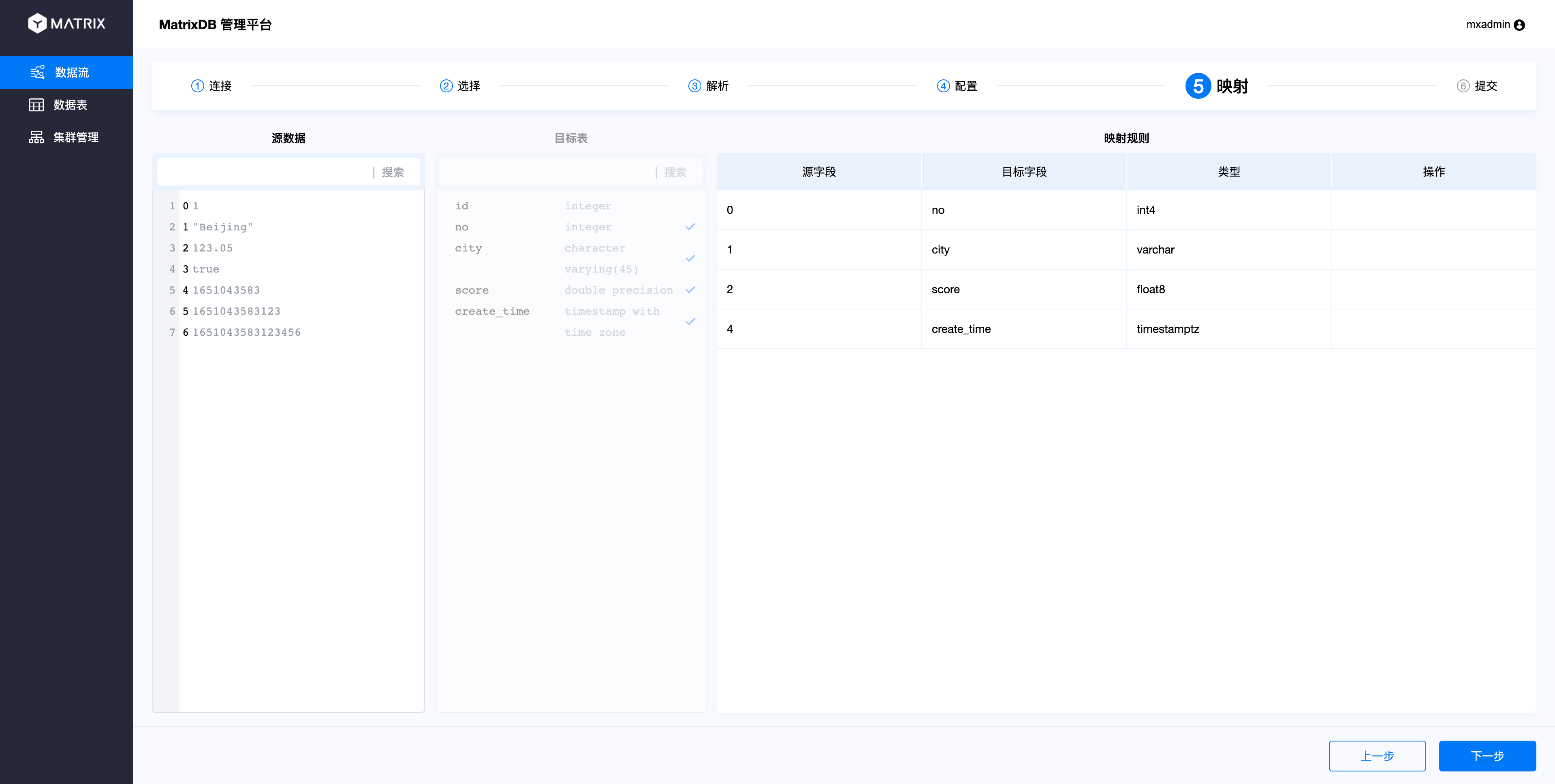
这里需要以下注意几点:
一、当列映射类型不兼容时,会出现如下提示:

二、当目标表字段选择时间戳类型且源数据选择字段的值为Unix时间戳时,输出值右边会显示时间戳格式转换复选框,默认为选中且可用状态,输出值结果自动转换为数据库时间戳格式。
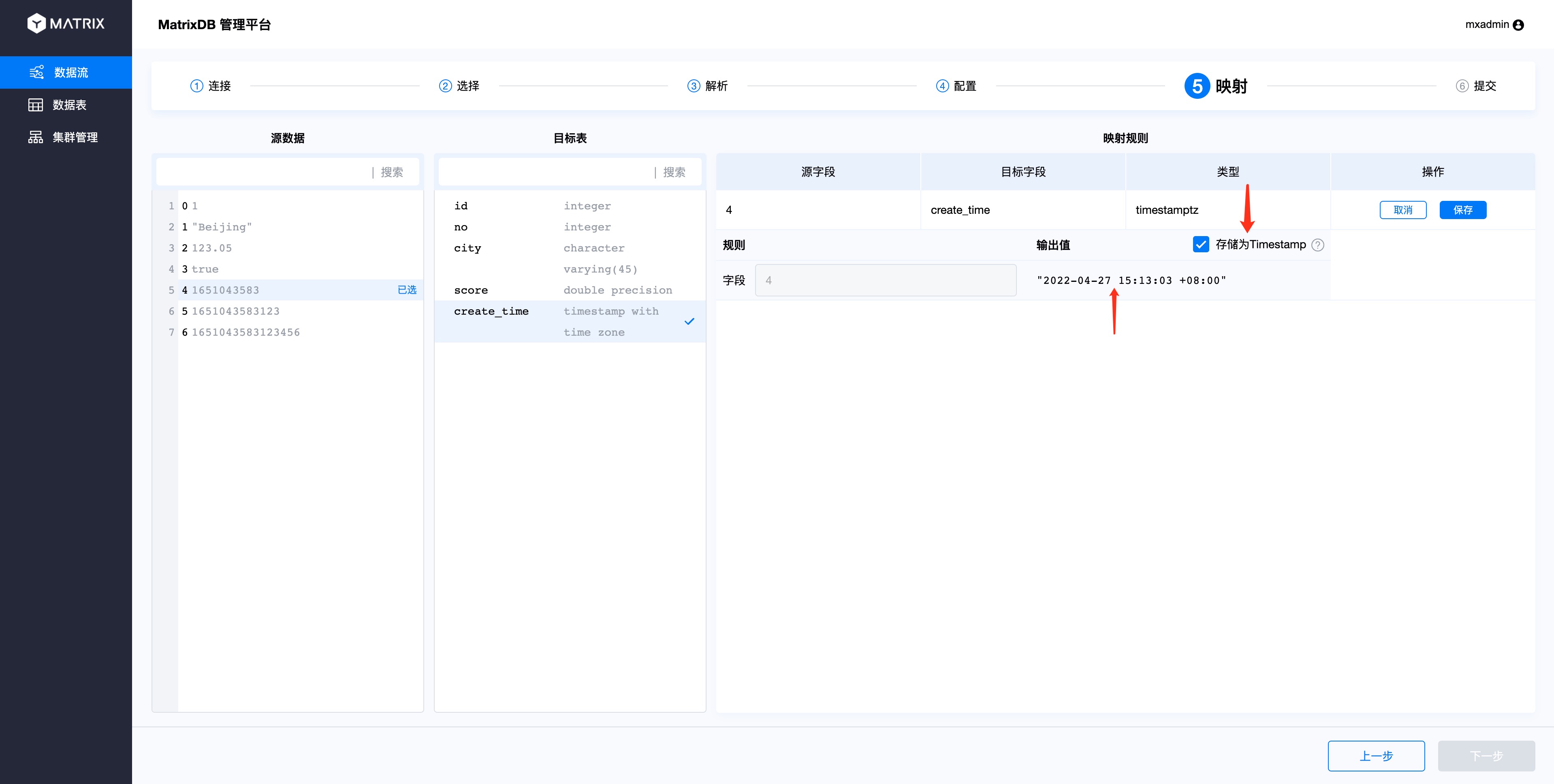
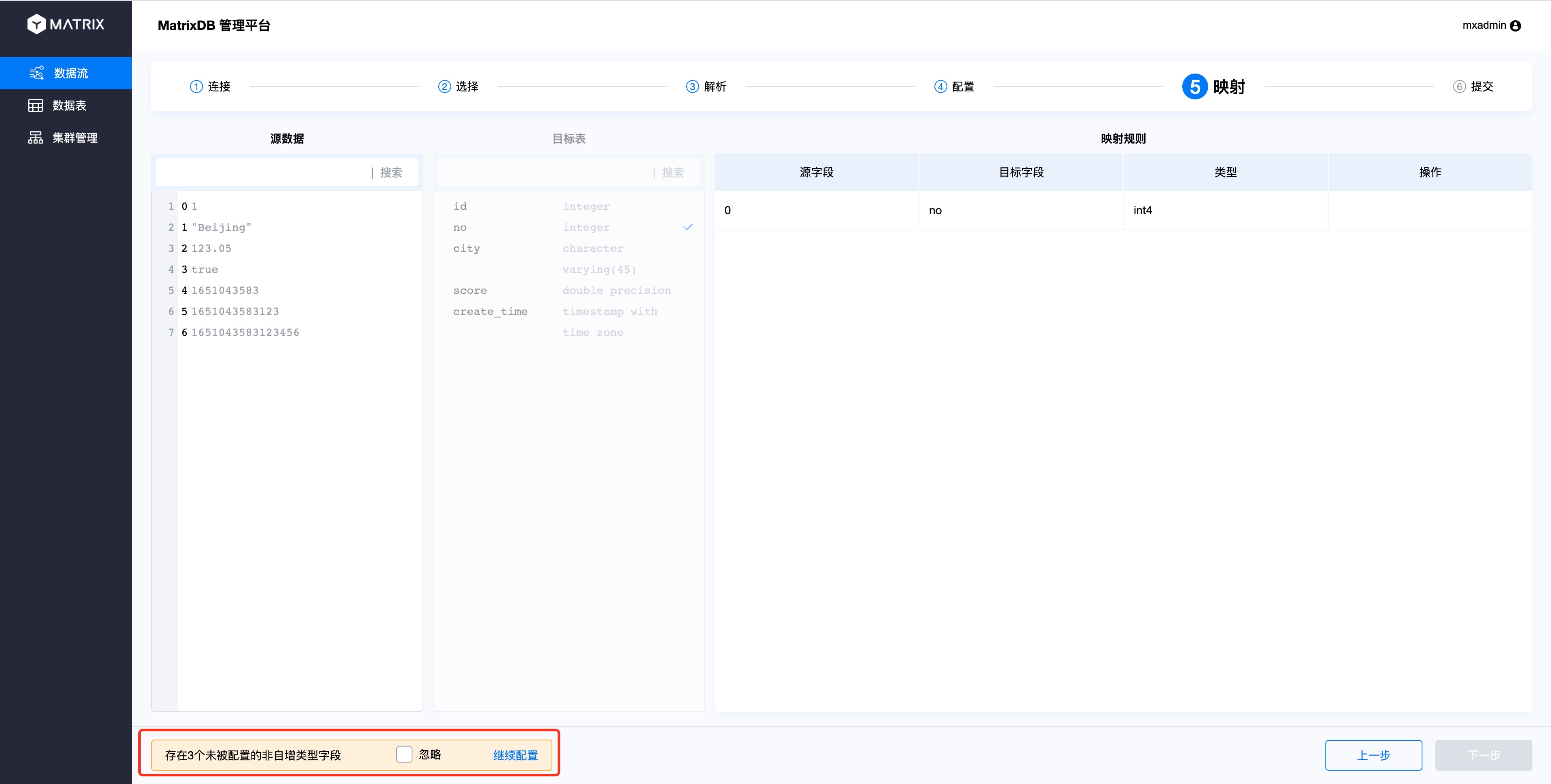
三、如果CSV列数与数据库表列数不一致,或者无法一一对应,则允许出现未被映射的源数据列和数据库表列。未被映射的源数据列会被丢弃;未被映射的目标表列则按照建表规则填充NULL或默认值。
完成映射后,进入到最后一个页面“提交”。该页面汇总了刚才选择的所有结果,使用时间戳格式转换的映射字段规则箭头上方会出现“数据格式转换”的文字。确认无误后点“提交”。

最后进入到完成页面:
目前Kafka数据接入支持两种数据格式:CSV和JSON。刚才演示了CSV格式的接入,下面对比一下JSON格式在接入时的差别。
选择页面中,选择格式里选择JSON。
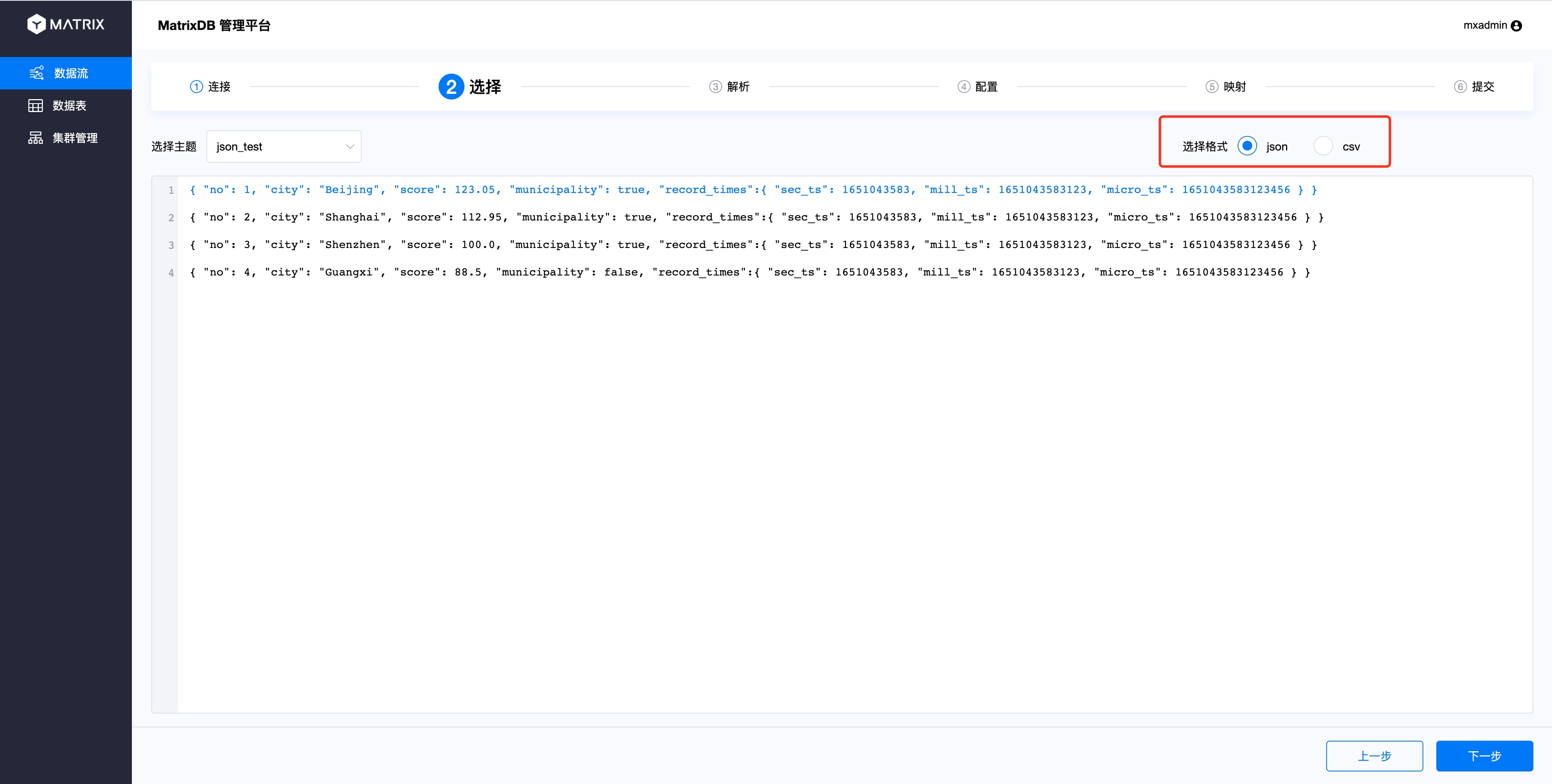
解析页面可以看出,JSON列的索引使用$符号开始,.加列名来索引,索引规则参照JSONPath。
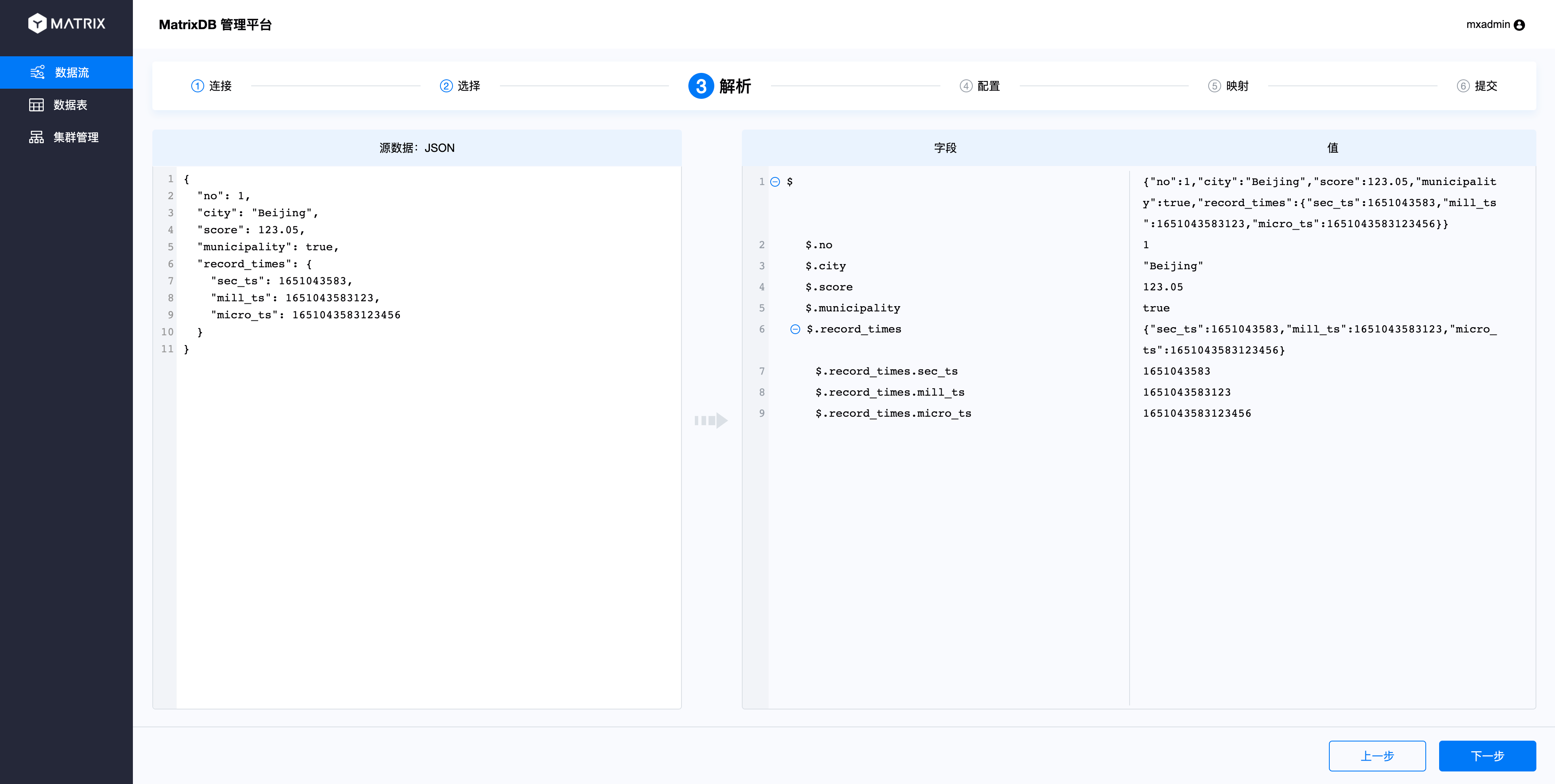
因为JSON支持多层级,所以映射页面里可选择不同层级下的列:

按照上面流程创建接入过程并保存提交后,就完成了数据接入的过程,之前写入到Topic的数据和后面新接入的数据都会流向目标表中。退回到主界面会看到刚才创建的数据流信息:
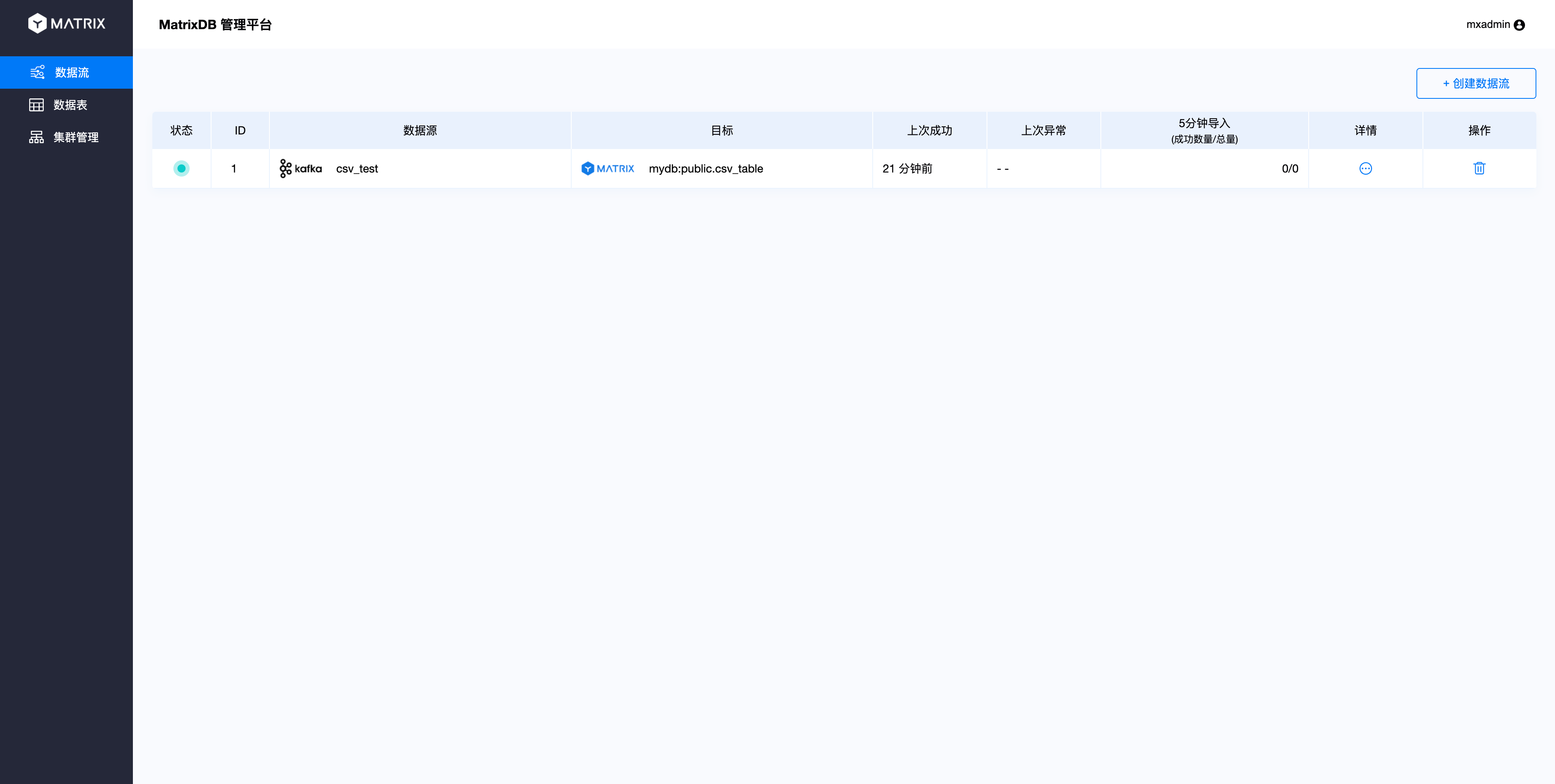
点击详情则会进入到详细信息页面:
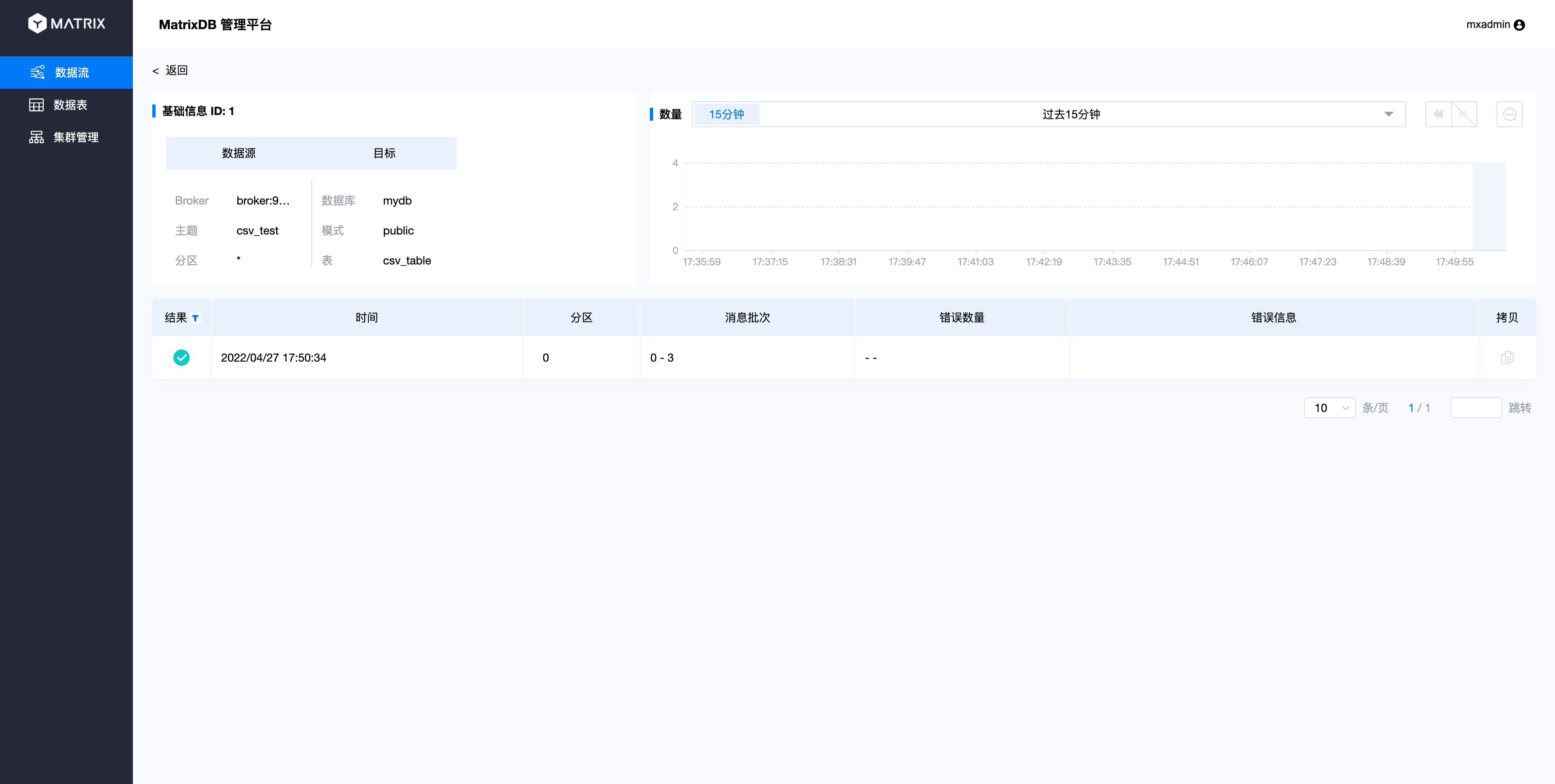
下面登录数据库验证数据已正确接入:
mydb=# select * from csv_table;
id | no | city | score | create_time
----+----+----------+--------+------------------------
1 | 1 | Beijing | 123.05 | 2022-04-27 07:13:03+00
2 | 2 | Shanghai | 112.95 | 2022-04-27 07:13:03+00
3 | 3 | Shenzhen | 100 | 2022-04-27 07:13:03+00
4 | 4 | Guangxi | 88.5 | 2022-04-27 07:13:03+00
(4 rows)





