对于海量存储的分布式数据库,随着数据量的增大,已有集群容量与算力不够用是不可避免的问题,所以扩容操作不可或缺。在MatrixDB里,你可以自由选择使用图形化界面操作扩容或命令行在线扩容。
注意!
当你想要扩容,你需要提前为新增的节点安装和当前数据库集群版本相同的MatrixDB。
当你点击 "集群管理" 页面右上角的扩容按钮后,会进入扩容的一个说明页,该页面描述了扩容的步骤、时机、以及一些扩容前的装备工作。通过这些,你可以详细的了解什么是扩容,以及扩容带来的影响。
在说明页点击"下一步", 即进入添加节点页面,进入该页面后系统会首先收集下当前集群已经存在的节点信息
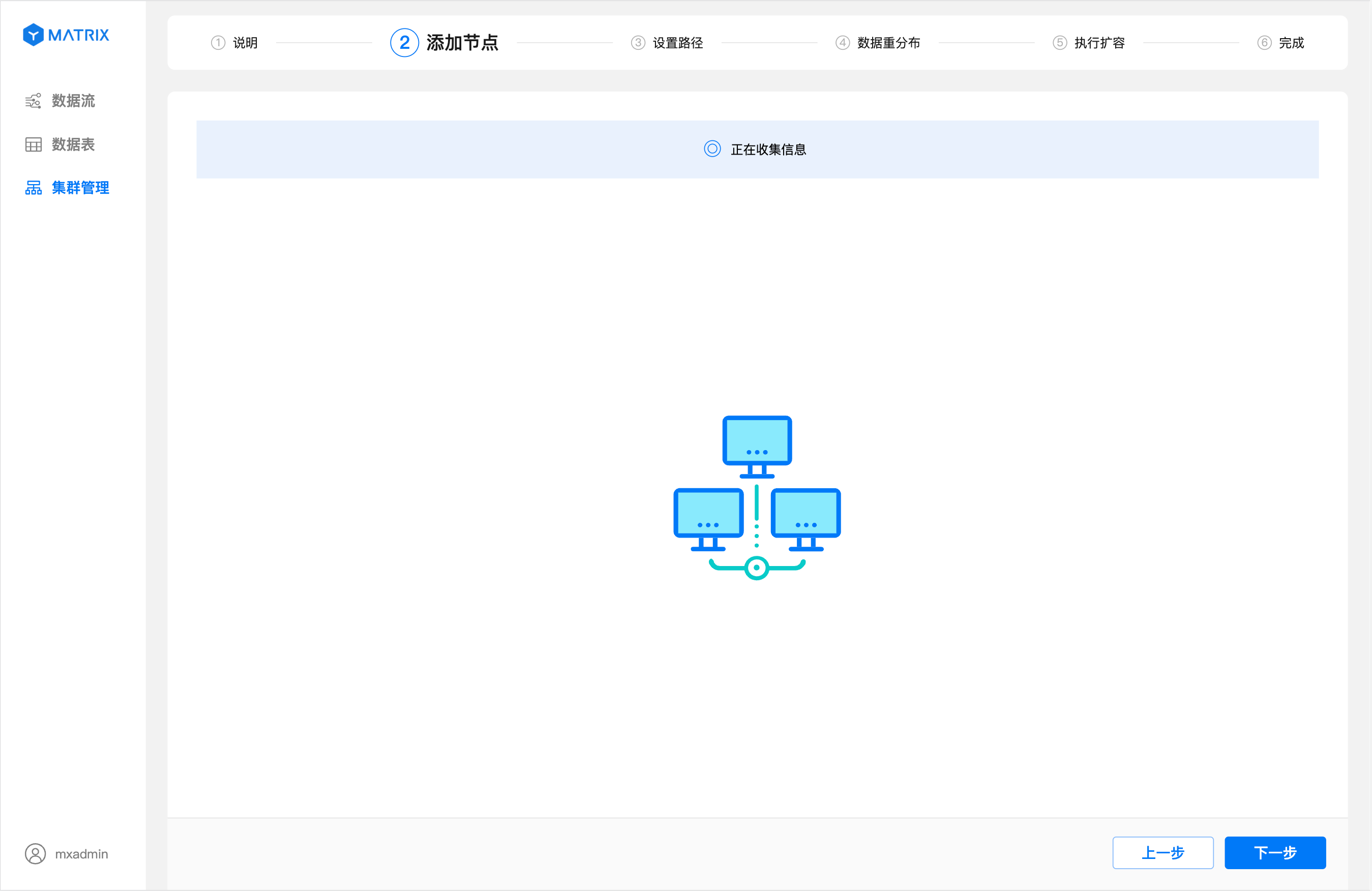
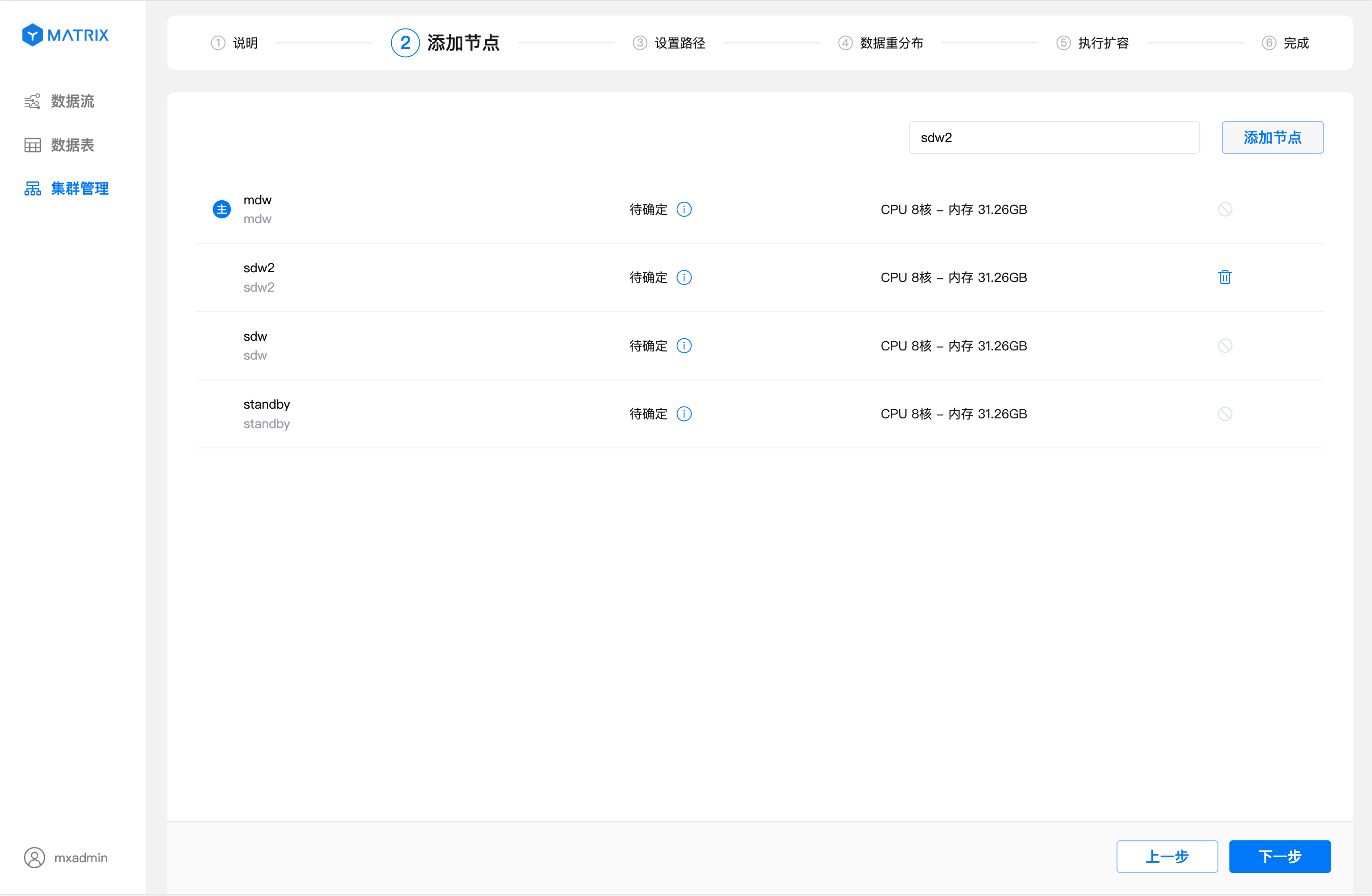
节点信息收集完成后,可以看到已经存在了3个节点:
在右上角的输入框中输入准备好的节点的标识(可以是主机名、FQDN或者IP),点击"添加节点" 按钮
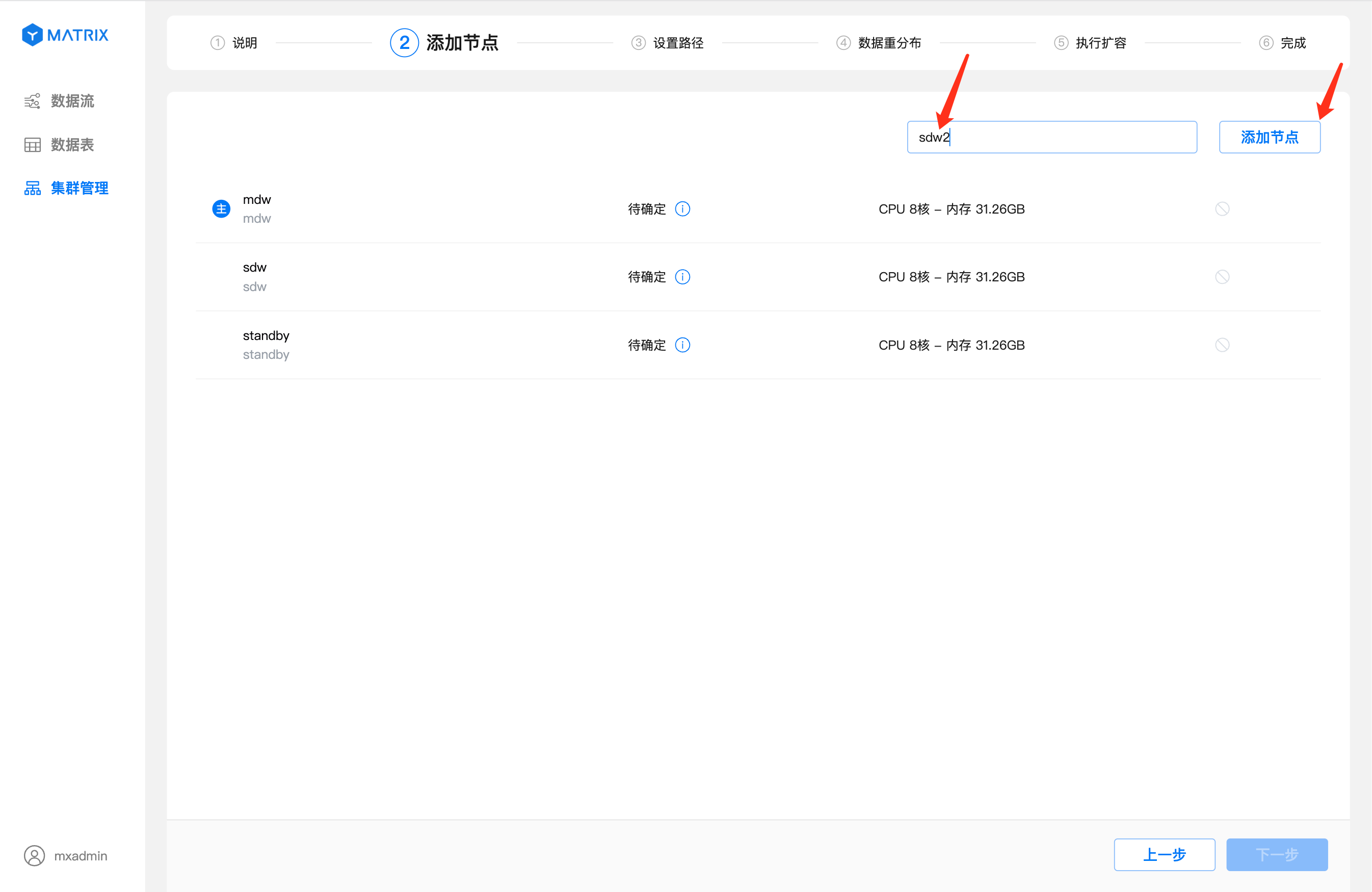
如图所示表示添加节点操作成功,新增的节点会依次位于主节点下方。如果你想要删除节点,点击新增的节点右侧的图标即可删除。
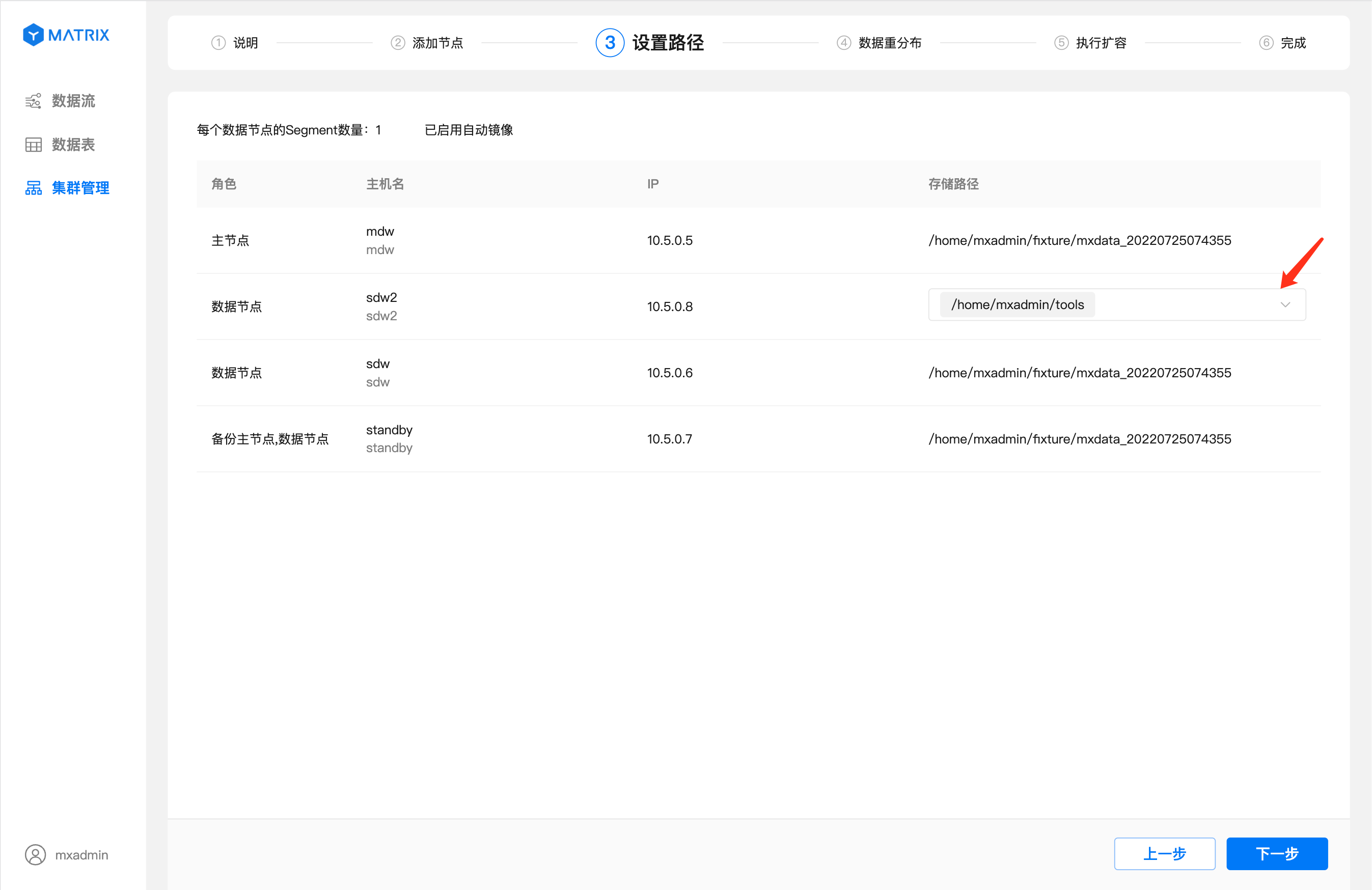
添加节点成功后点击“下一步”,进入设置路径页面,在设置路径页面你可以为新增的节点设置存储路径。
注意!
当前使用图形化界面新增的节点均为数据节点,所以,你可以为该节点设置多个存储路径。
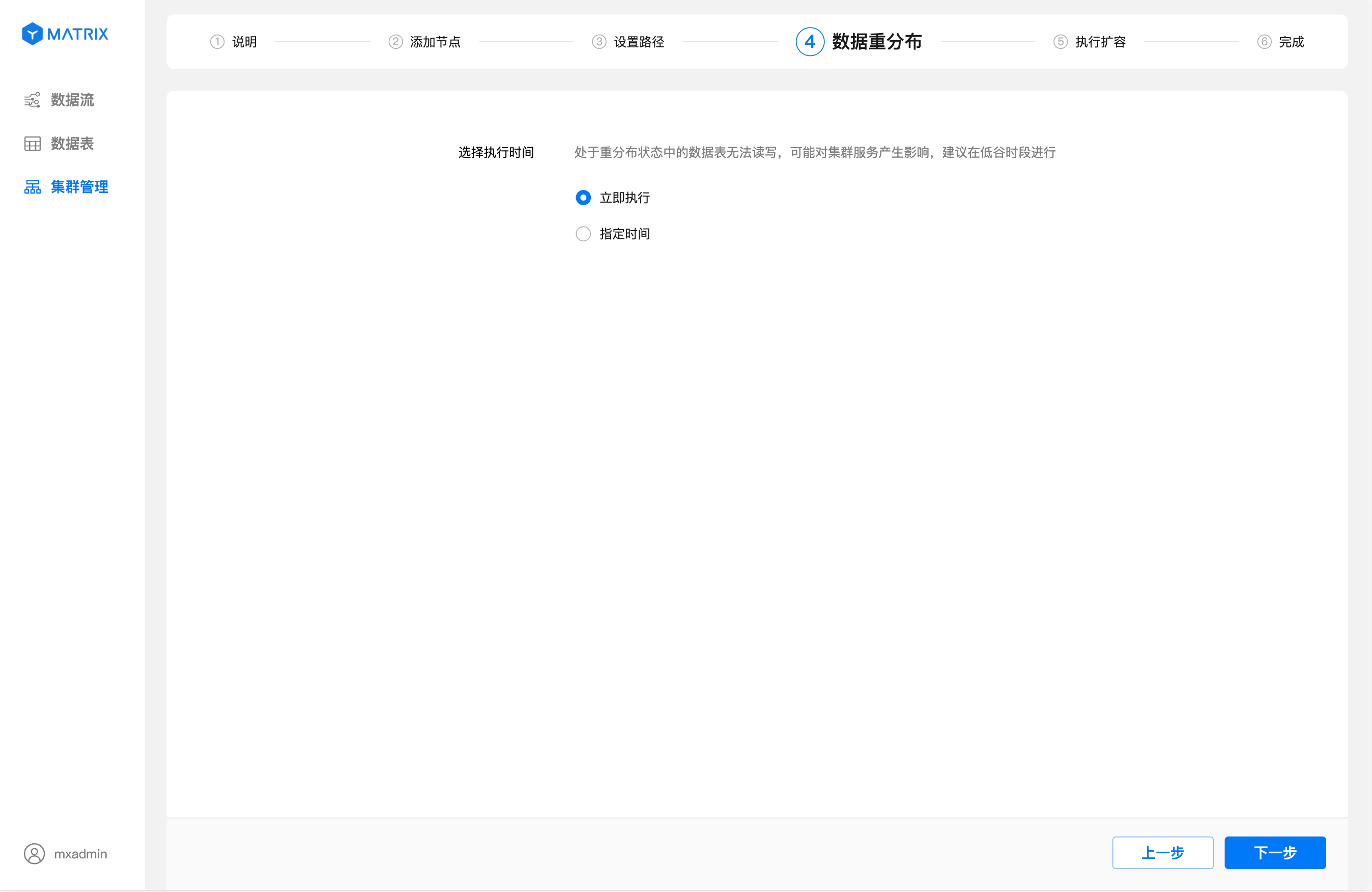
设置完路径,点击“下一步”进入数据重分布页面。 可以在该页面选择数据重分布的时间,共有两种选择: “立即执行”与“指定时间“。
立即执行,即系统在“执行扩容”页面执行完添加节点的计划后,会立即启动数据重分布。
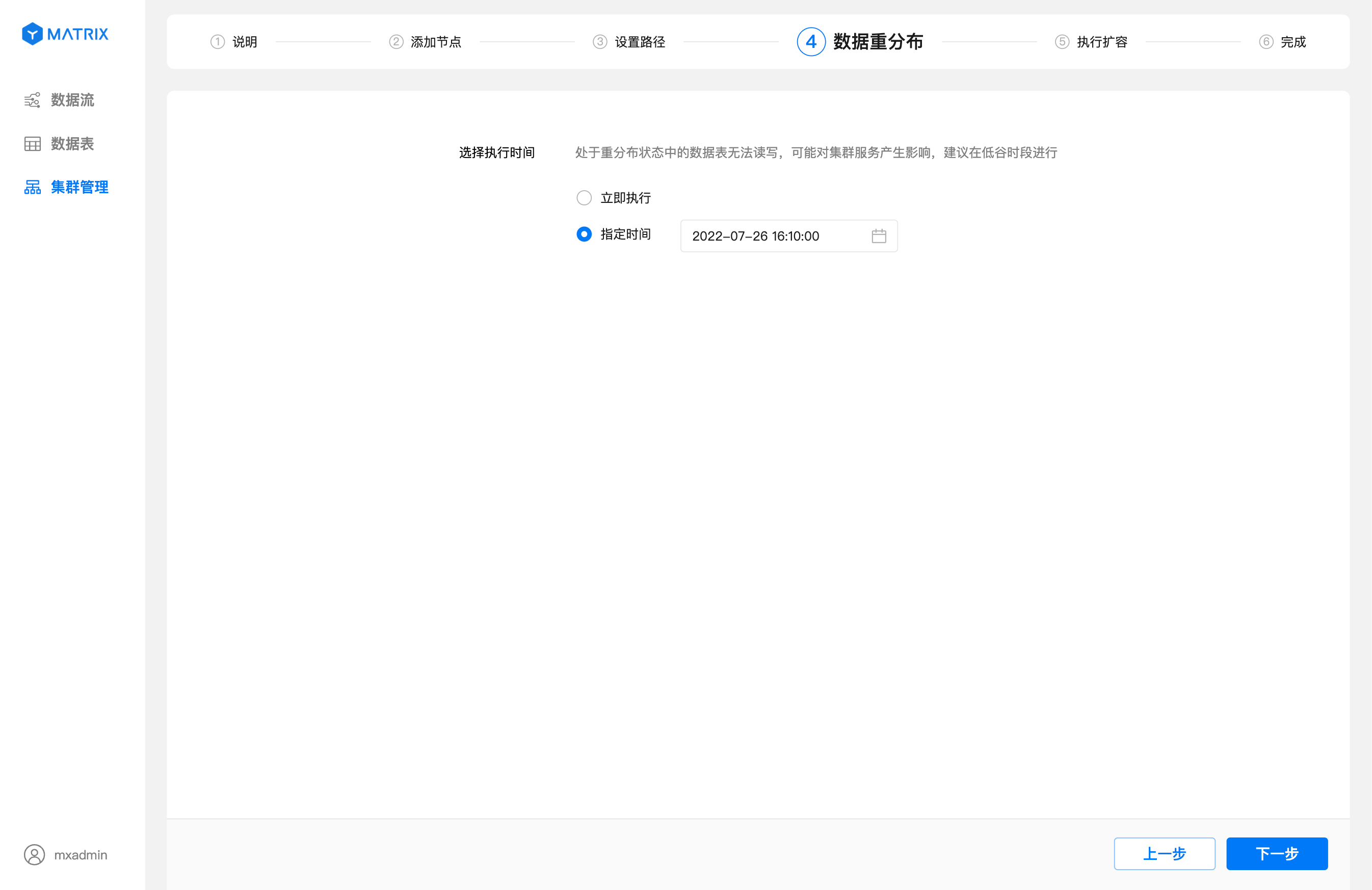
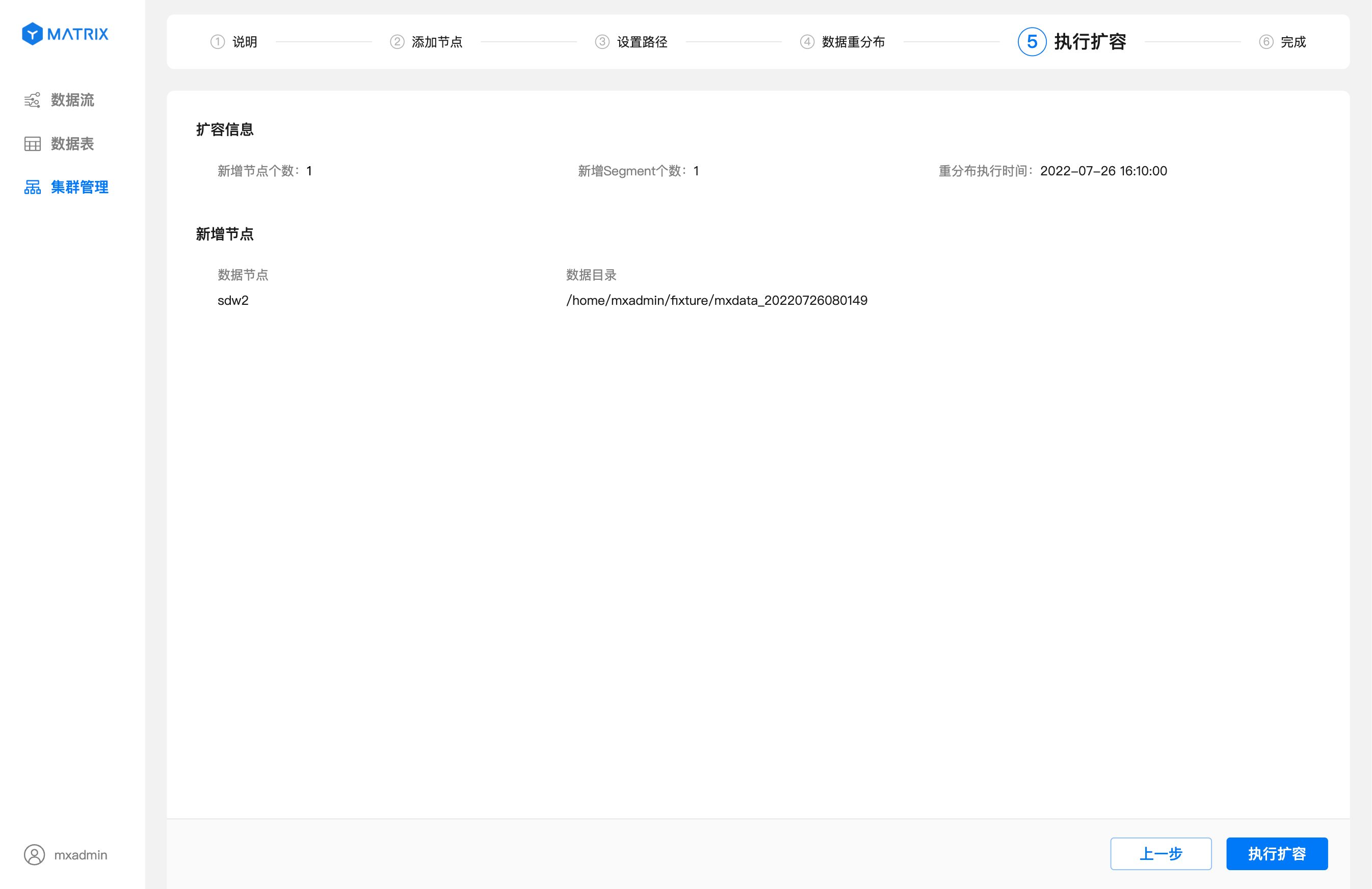
指定时间:即你可以通过设置一个未来的时间,自由决定什么时候开始执行数据重分布。
设置完重分布时间后,点击“下一步”进入执行扩容页面。在这个页面你可以查看新增的节点信息,以及设置的重分布执行时间。
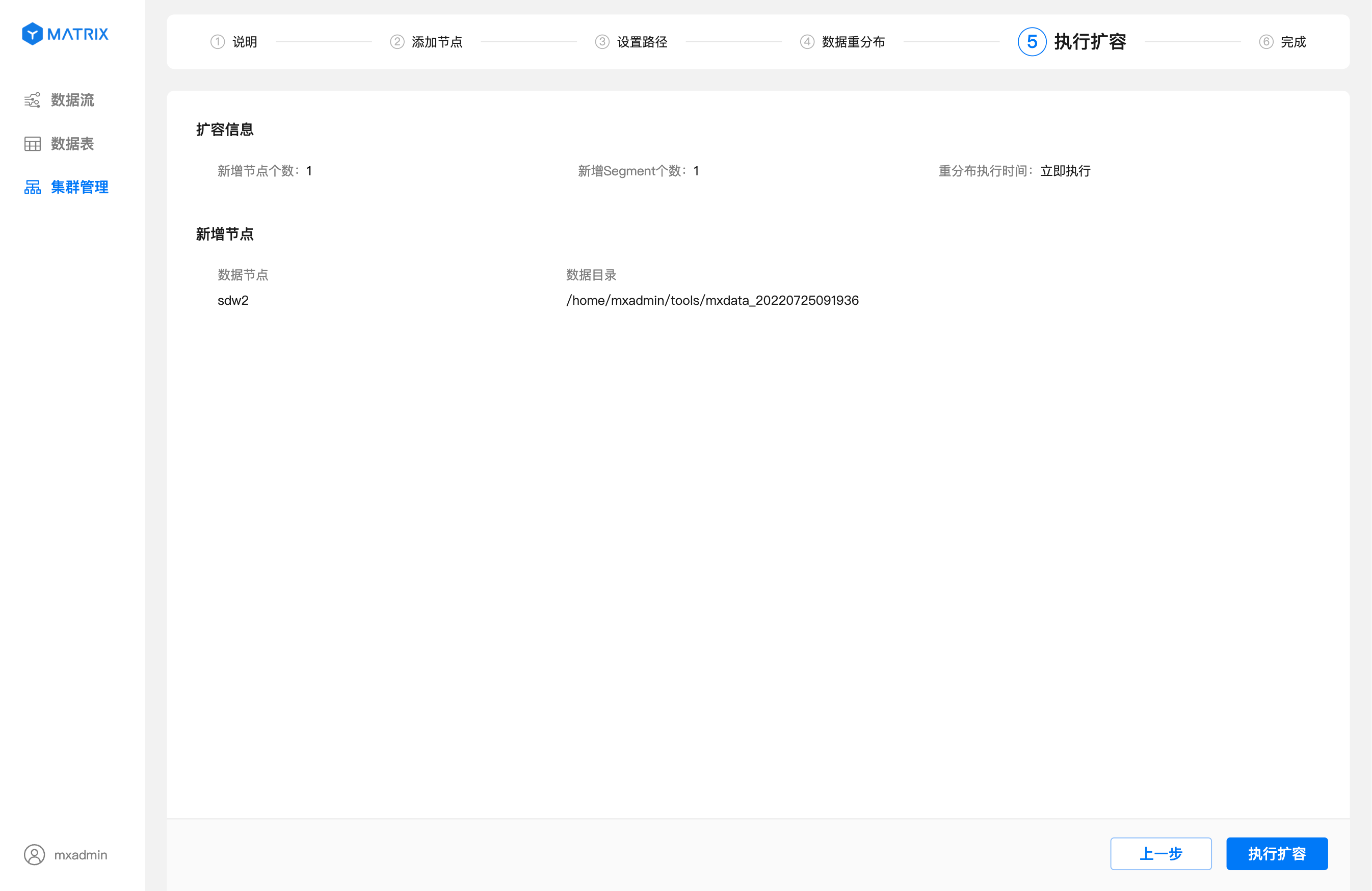
指定重分布时间。
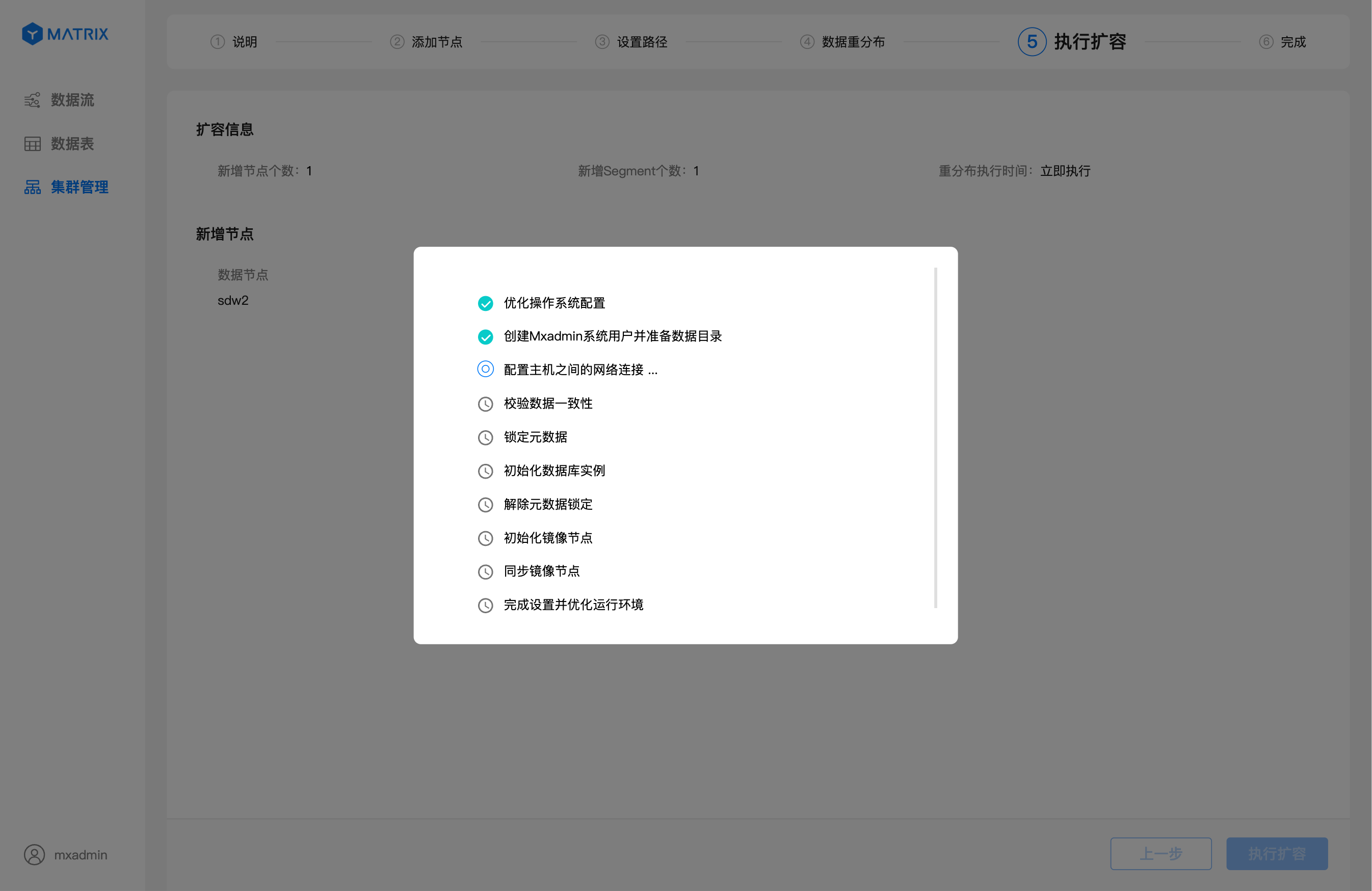
 当你点击右下角的“执行扩容”按钮,系统将正式开始添加节点的计划。
当你点击右下角的“执行扩容”按钮,系统将正式开始添加节点的计划。
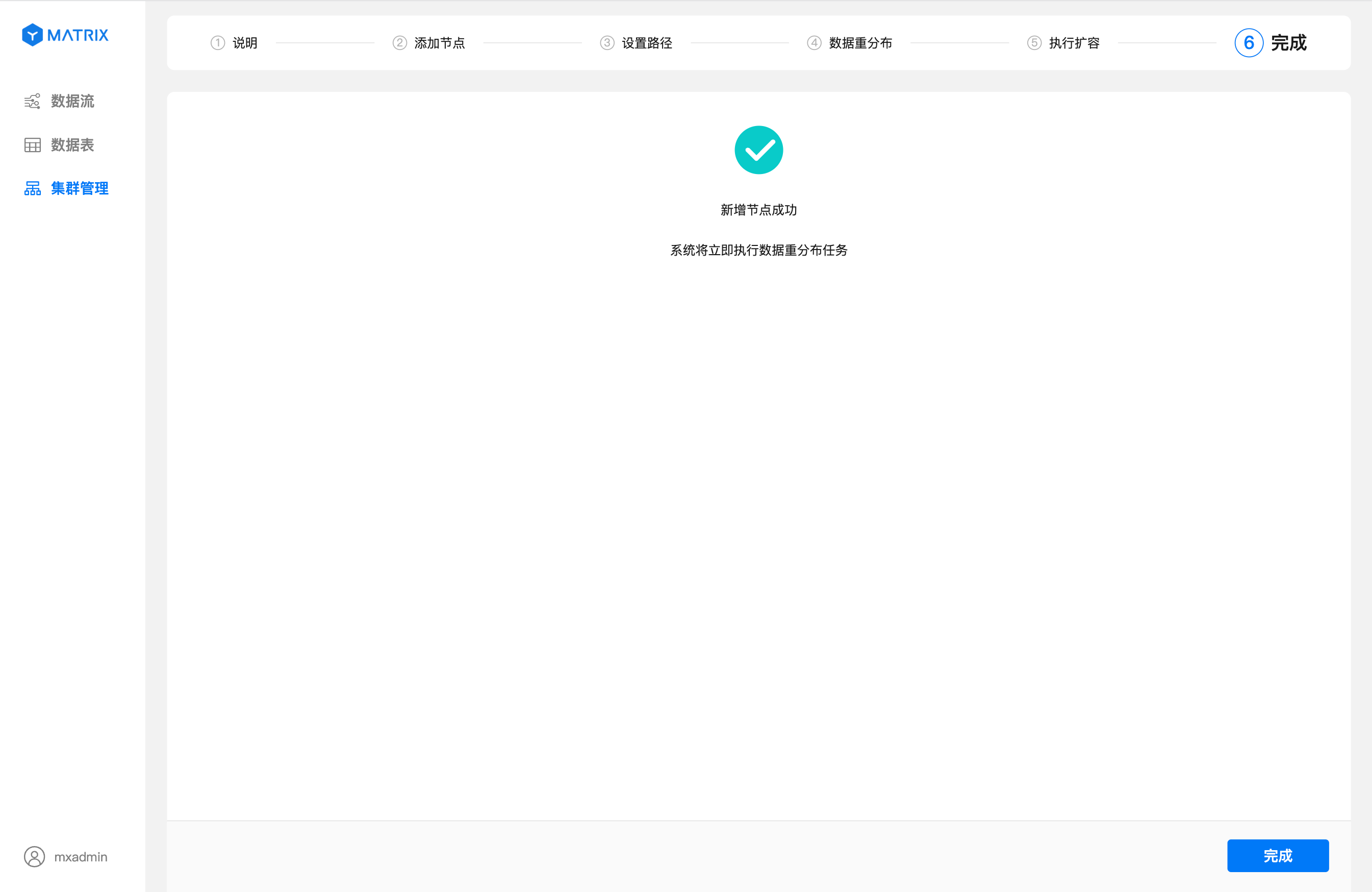
指定重分布时间的完成页。
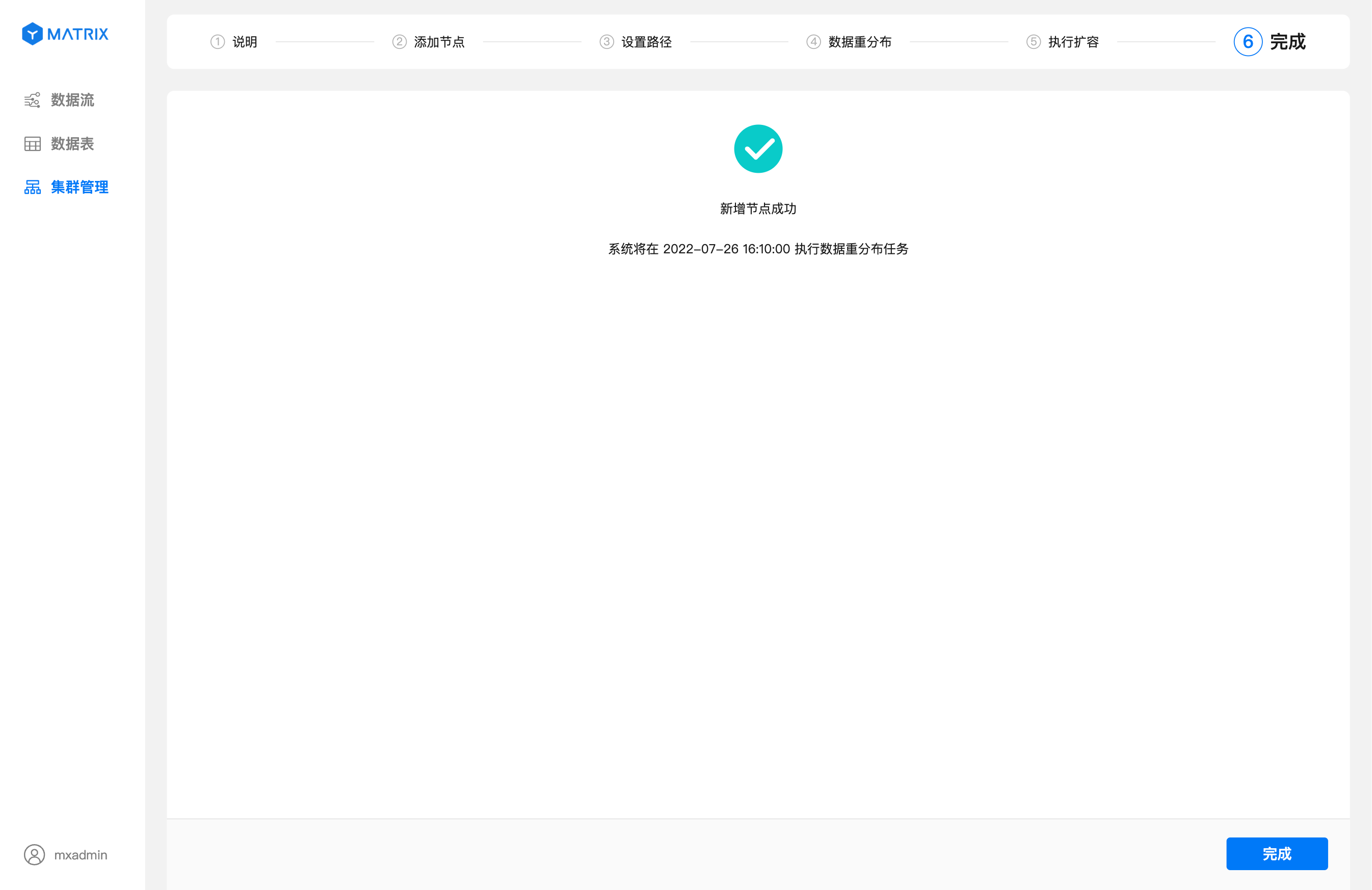
点击右下角的“完成”按钮即可跳转回“集群管理”页,此时可以看到数据重分布的进度信息以及新增的节点信息。
注意!
当存在扩容任务时,集群管理页面的扩容按钮不可再点击。
如果你选择的是“指定时间”重分布。那么,当你点击 “完成” 按钮后跳转到集群管理页后,会看到集群管理页面最上端在展示系统当前的任务。此时点击“详情”就可以查看任务详情。
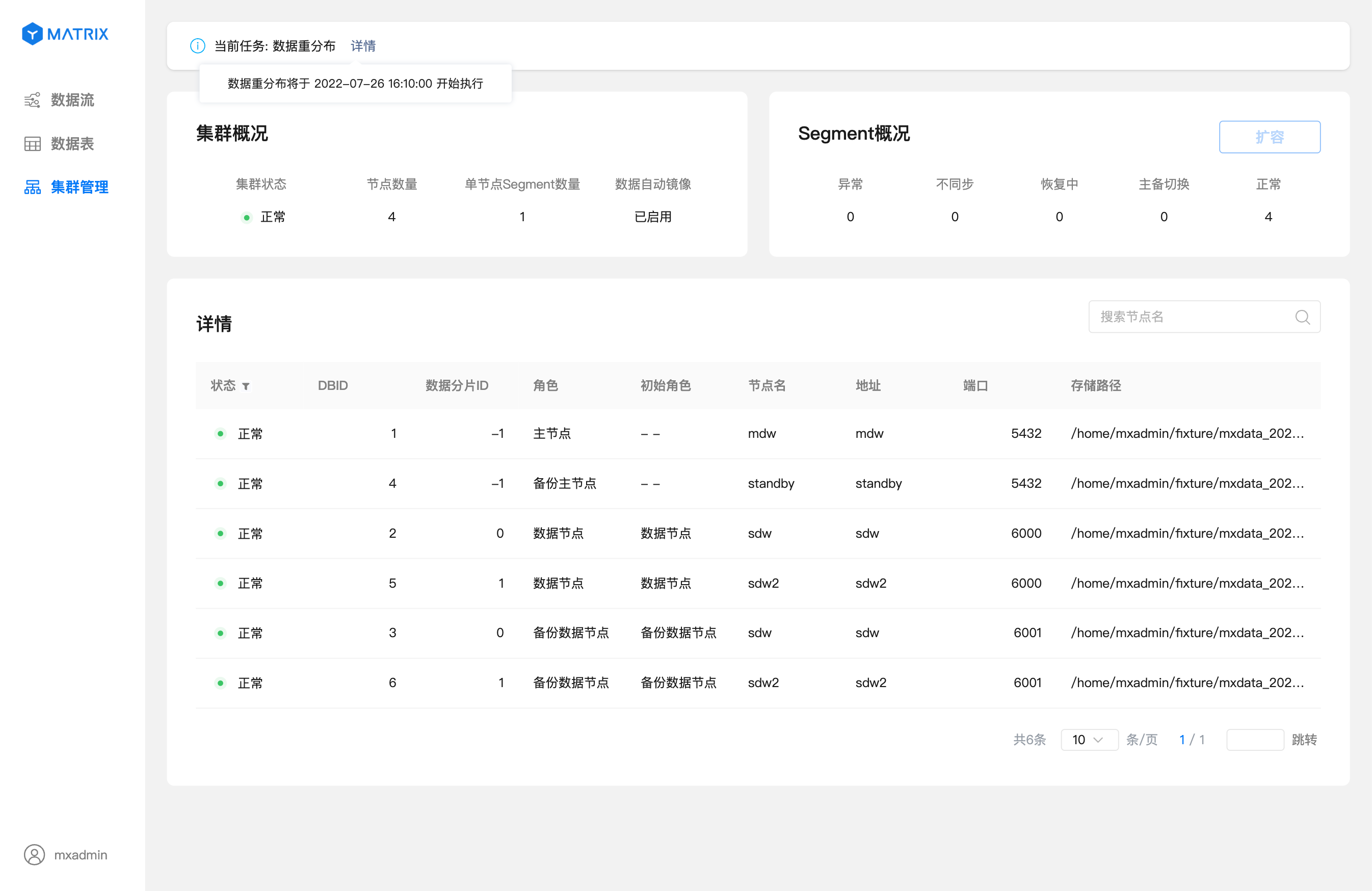
当数据开始按照指定的时间进行重分布时,点击右上角的“详情”可以查看重分布进度信息:
当重分布完成后,全局任务条变更为:

注意!
页面顶端的全局任务条在图形化的任何页面都可以看到,只有在你点击任务条“关闭”按钮时,它才不再展示。
主要内容包括:
命令行在线扩容分两个步骤:
该环节为集群增加新的数据节点(Segment),并启动使用,但原有表数据还存储在老的节点上。
增加新节点首先要提供部署方案配置文件,该文件可以手动编写,也可以使用gpexpand工具自动生成,推荐使用自动生成方式。
执行gpexpand:
[mxadmin@mdw ~]$ gpexpand
......
Please refer to the Admin Guide for more information.
Would you like to initiate a new System Expansion Yy|Nn (default=N):输入y回车:
> y然后要求输入新增节点主机名,逗号分割:
Enter a comma separated list of new hosts you want
to add to your array. Do not include interface hostnames.
**Enter a blank line to only add segments to existing hosts**[]:
> sdw3,sdw4确认新增主机名网络联通,并且与原节点已建立互信。并确保已安装
rsync
每个节点额外增加多少机器?这里输入的值是在原有节点部署 Segment 数量的基础上增加多少 Segment。如果每台主机部署节点数与原主机相同,则直接输入0即可。
How many new primary segments per host do you want to add? (default=0):
> 0
Generating configuration file...
20211102:14:36:24:024562 gpexpand:mdw:mxadmin-[INFO]:-Generating input file...
Input configuration file was written to 'gpexpand_inputfile_20211102_143624'.
Please review the file and make sure that it is correct then re-run
with: gpexpand -i gpexpand_inputfile_20211102_143624
20211102:14:36:24:024562 gpexpand:mdw:mxadmin-[INFO]:-Exiting...执行完毕会在当前目录生成gpexpand_inputfile_20211102_143624配置文件:
[mxadmin@mdw ~]$ cat gpexpand_inputfile_20211102_143624
sdw3|sdw3|7002|/home/mxadmin/gpdemo/datadirs/dbfast1/demoDataDir3|5|3|p
sdw3|sdw3|7003|/home/mxadmin/gpdemo/datadirs/dbfast2/demoDataDir4|6|4|p
sdw3|sdw3|7004|/home/mxadmin/gpdemo/datadirs/dbfast3/demoDataDir5|7|5|p
sdw4|sdw4|7002|/home/mxadmin/gpdemo/datadirs/dbfast1/demoDataDir6|8|6|p
sdw4|sdw4|7003|/home/mxadmin/gpdemo/datadirs/dbfast2/demoDataDir7|9|7|p
sdw4|sdw4|7004|/home/mxadmin/gpdemo/datadirs/dbfast3/demoDataDir8|10|8|p配置文件中包含了新主机信息,以及新 Segment 端口号、数据目录、dbid、角色等信息。这些信息与gp_segment_configuration表对应。该配置文件也可以按照该格式手动编写。
准备好配置文件后,下面执行增加新节点操作:
[mxadmin@mdw ~]$ gpexpand -i gpexpand_inputfile_20211102_143624
......
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Unlocking catalog
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Unlocked catalog
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Creating expansion schema
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database postgres
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database template1
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Populating gpexpand.status_detail with data from database mxadmin
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-************************************************
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Initialization of the system expansion complete.
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-To begin table expansion onto the new segments
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-rerun gpexpand
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-************************************************
20211102:14:54:03:025371 gpexpand:mdw:mxadmin-[INFO]:-Exiting...执行成功后,查询gp_segment_configuration表,即可看到新节点已加入。
在线扩容的第二步操作,是将表数据重分布到新节点上,因为新增加的 Segment 上并没有数据。
MatrixDB支持的3种分布方式:随机、哈希、复制,都要按照规则同步到新 Segment 上。其中,复制表依然要全量存储在新增加的 Segment 上;哈希表则要按照规则做重分布;随机表因为数据分布无规律,不会做数据迁移,只是新插入的数据会按照概率落到新的 Segment 上。
第一阶段执行完毕后,会在postgres数据库创建schema:gpexpand,包含了扩容状态信息:
postgres=# \d
List of relations
Schema | Name | Type | Owner | Storage
----------+--------------------+-------+---------+---------
gpexpand | expansion_progress | view | mxadmin |
gpexpand | status | table | mxadmin | heap
gpexpand | status_detail | table | mxadmin | heap
(3 rows)其中,status_detail表记录了所有需要做重分布的表及重分布状态:
postgres=# select * from gpexpand.status_detail ;
dbname | fq_name | table_oid | root_partition_name | rank | external_writable | status | expansion_started | expansion_finished | source_bytes
---------+-------------+-----------+---------------------+------+-------------------+-------------+-------------------+--------------------+--------------
mxadmin | public.t2 | 16388 | | 2 | f | NOT STARTED | | | 8192
mxadmin | public.t1 | 16385 | | 2 | f | NOT STARTED | | | 16384
mxadmin | public.disk | 16391 | public.disk | 2 | f | NOT STARTED | | | 0
(3 rows)直接运行gpexpand即可执行表重分布:
[mxadmin@mdw ~]$ gpexpand
......
gpexpand:mdw:mxadmin-[INFO]:-Querying gpexpand schema for current expansion state
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.t2
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.t2
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.t1
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.t1
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Expanding mxadmin.public.disk
20211102:15:18:27:026291 gpexpand:mdw:mxadmin-[INFO]:-Finished expanding mxadmin.public.disk
20211102:15:18:32:026291 gpexpand:mdw:mxadmin-[INFO]:-EXPANSION COMPLETED SUCCESSFULLY
20211102:15:18:32:026291 gpexpand:mdw:mxadmin-[INFO]:-Exiting...表重分布完毕后再查询status_detail表,会看到状态已经变成了COMPLETED:
postgres=# select * from gpexpand.status_detail ;
dbname | fq_name | table_oid | root_partition_name | rank | external_writable | status | expansion_started | expansion_finished | source_bytes
---------+-------------+-----------+---------------------+------+-------------------+-----------+----------------------------+----------------------------+--------------
mxadmin | public.t2 | 16388 | | 2 | f | COMPLETED | 2021-11-02 15:18:27.326247 | 2021-11-02 15:18:27.408379 | 8192
mxadmin | public.t1 | 16385 | | 2 | f | COMPLETED | 2021-11-02 15:18:27.431481 | 2021-11-02 15:18:27.507591 | 16384
mxadmin | public.disk | 16391 | public.disk | 2 | f | COMPLETED | 2021-11-02 15:18:27.531727 | 2021-11-02 15:18:27.570559 | 0
(3 rows)如果想增加重分布并发度,可以在执行gpexpand命令时加-B参数,默认值是16,上限是128,如:
[mxadmin@mdw ~]$ gpexpand -B 32重分布完毕后,运行gpexpand -c来清理扩容过程的中间表:
[mxadmin@mdw ~]$ gpexpand -c
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-local Greenplum Version: 'postgres (MatrixDB) 5.0.0-enterprise~alpha (Greenplum Database) 7.0.0 build dev'
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-master Greenplum Version: 'PostgreSQL 12 (MatrixDB 5.0.0-enterprise~alpha) (Greenplum Database 7.0.0 build dev) on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180303 (Red Hat 7.3.1-5), 64-bit compiled on Oct 25 2021 15:24:16'
20211102:15:24:41:026524 gpexpand:mdw:mxadmin-[INFO]:-Querying gpexpand schema for current expansion state
Do you want to dump the gpexpand.status_detail table to file? Yy|Nn (default=Y):
> n
20211102:15:24:46:026524 gpexpand:mdw:mxadmin-[INFO]:-Removing gpexpand schema
20211102:15:24:46:026524 gpexpand:mdw:mxadmin-[INFO]:-Cleanup Finished. exiting...到此,扩容成功。
执行重分布之后系统会自动生成以下系统目录(包含系统表、系统视图等),存放在 matrixmgr 数据库的 matrixmgr_internal 模式下。
| 字段名 | 类型 | 描述 |
|---|---|---|
| status | text | 跟踪一个扩容操作的状态,有效值为: SCHEDULED START,指预约开始执行重分布的时间 SETUP,表示收集数据库数据表信息的开始时间 SETUP DONE,指数据表信息收集完毕的时间 EXPANSION STARTED,指正式开始数据重分布的时间 COMPLETED,指完成所有重分布任务时的时间 LAST SCHEDULED START,指完成所有重分布任务之后,将SCHEDULED START的值保存到LAST SCHEDULED START,而后清空 SCHEDULED START |
| updated_at | timestamp with time zone | 最后状态变化的时间戳 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| dbname | text | 表所属数据库的名称 |
| db_oid | oid | 表所属数据库的 Oid |
| fq_name | text | 表的完全限定名称 |
| table_oid | oid | 表的 OID |
| root_partition_name | text | 对于分区表来说,是根分区的名称。否则为 None |
| rank | int | 等级决定表被扩容的顺序。扩容工具将在 rank 上排序,数字小的表将被优先处理 |
| external_writable | boolean | 标识表是否是外部可写表。(外部可写表需要不同的语法来扩容) |
| status | text | 此表当前的扩容状态。有效值为: NOT STARTED IN PROGRESS PENDING RETRYING COMPLETED FAILED |
| expansion_started_at | timestamp with time zone | 此表扩容开始的时间戳 |
| expansion_finished_at | timestamp with time zone | 此表扩容完成的时间戳。扩容失败也会更新此时间戳 |
| source_bytes | numeric | 还未重分布的数据量。 由于 HEAP 表中的表膨胀及扩容后 Segment 数量的变化,扩容后的尺寸也会不同于源表。 此表提供进度信息并估计扩容全程持续时间 |
| failed_times | integer | 重试次数,默认值为 5 |
| 字段名 | 类型 | 描述 |
|---|---|---|
| name | text | 描述扩容过程的指标名称,包含: Bytes Pending Bytes in Progress Bytes Done Bytes Failed Estimated Expansion Rate Estimated Remaining Time Done Tables Number Pending Tables Number In Progress Tables Number Failed Tables Number |
| value | text | 上述指标的值。如 Bytes Pending: 100023434 |
gpexpand的详细使用方法请参考文档






