注意!
灾难恢复能力在 YMatrix 6.0.0 版本中仅作为实验性功能。
本节将介绍如何将一个已部署好的 YMatrix 数据库集群作为主集群,进行 YMatrix 灾难恢复功能组件和备份集群部署的过程。
在灾难恢复功能部署前,我们先了解一下 YMatrix 数据库集群的灾难恢复功能所包含的四个概念:
YMatrix 数据库集群
YMatrix 数据库集群指一个具备完整数据库功能的集群,包括高可用组件、数据库组件等。
主集群
主集群指正常情况下提供数据服务的数据库集群或需进行灾难恢复数据保障的数据库集群。
备份集群
备份集群指已从主集群备份数据并可在灾难发生时提供数据恢复或数据服务的数据库集群。
灾难恢复功能组件
灾难恢复功能组件指可实现主集群数据备份和灾难恢复时可实现数据服务切换的组件,包括主集群侧的 Subscriber 和备份集群侧的 Publisher。
Subscriber
Subscriber 是部署在主集群侧的灾难恢复功能组件,其功能是:
a. 接收从备份集群侧的 Publisher 发送来的备份请求,并将请求发送到主集群。
b. 接收主集群的备份数据,并将备份数据从主集群侧发送到备份集群侧的 Publisher。
Subscriber 应部署在主集群侧的一台独立的机器上,并保证该机器与主集群所有节点的网络连通(位于同一子网内)。
同时,Subscriber 所在的机器应能与备份集群侧的 Publisher 所在的机器保持网络连通(位于同一子网内)。
Publisher
Publisher 是部署在备份集群侧的灾难恢复功能组件,其功能是:
a. 接收备份集群侧的备份请求,并将请求发送到主集群的 Subscriber。
b. 接收主集群侧的 Subscriber 发送来的备份数据,并将数据发送给备份集群。
Publisher 应部署在备份集群侧的一台独立的机器上,并保证该机器与备份集群的所有节点网络连通(位于同一子网内)。
同时 Publisher 所在的机器应能与主集群侧的 Subscriber 所在机器的保持网络连通(位于同一子网内)。
备份集群
备份集群作为备份角色运行时,会通过异步或同步的方式从主集群备份全部数据,并支持只读类型的数据操作。
当发生灾难恢复切换后,备份集群就变为具有完整功能的 YMatrix 数据库集群,提供提供全类型的数据操作。
注:备份集群目前不包含高可用功能,即每个数据分片都只有一个副本。
部署灾难恢复功能,主集群 GUC synchronous_commit 仅支持 off(推荐)、local、remote_apple、on 四种取值。
在部署前,需在主集群 Master 机器中以 mxadmin 的用户身份,使用以下命令修改 synchronous_commit 参数。
gpconfig -c synchronous_commit -v <可取值之一>执行 mxstop -u 命令,重新加载配置以使参数修改生效。
部署的网络链接如下图所示:
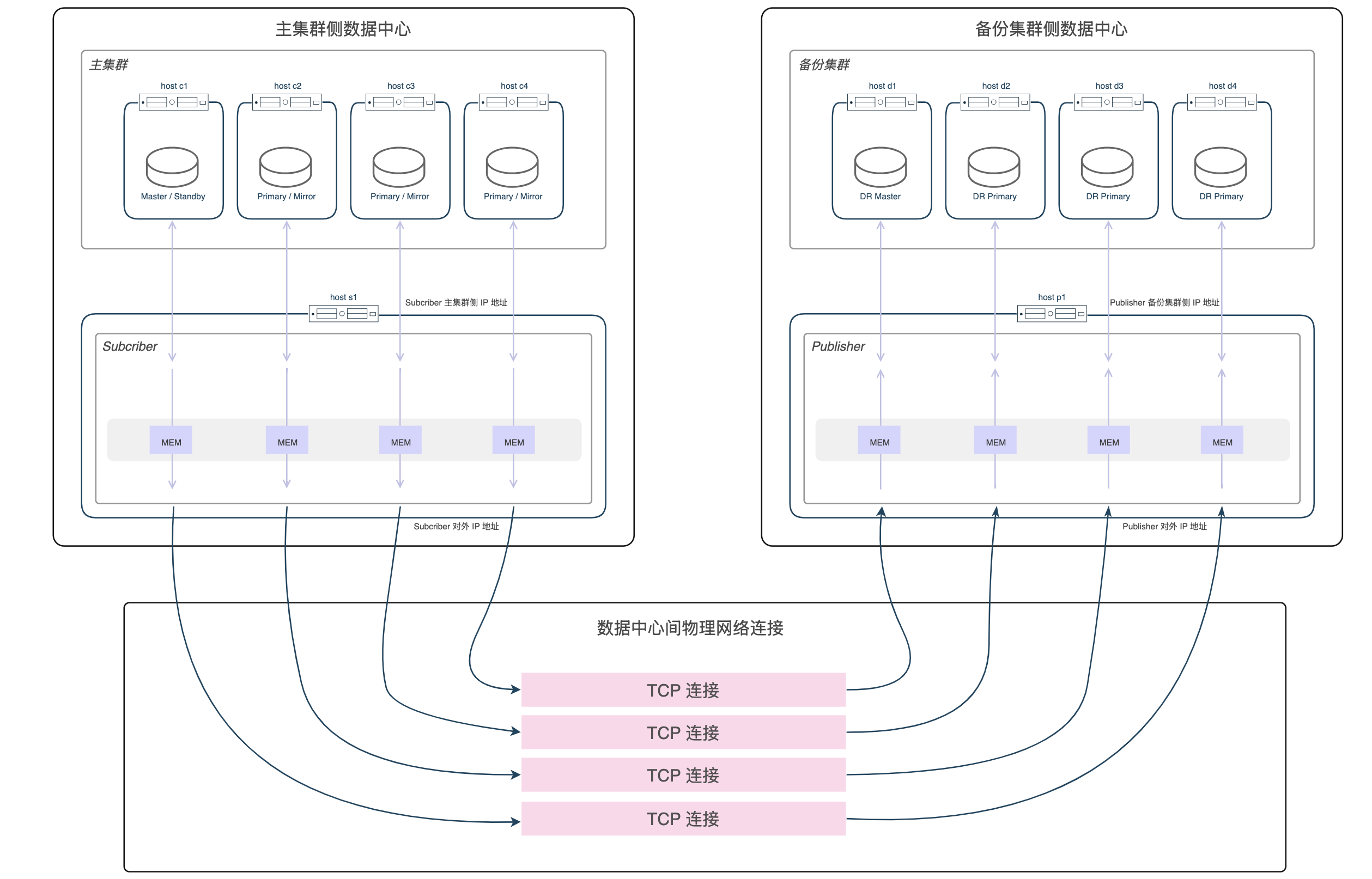
注:该网络环境准备方案仅适用于将备份集群部署到与主集群不同数据中心的情况。对于其他部署情况,需根据实际部署要求进行适当调整。
注意!
灾难恢复功能部署的备份集群所安装的 YMatrix 数据库软件版本应与主集群所安装的 YMatrix 数据库软件版本保持完全一致。灾难恢复功能部署的备份集群的 CPU 架构应与主集群的 CPU 架构保持完全一致。
向主集群侧新增 Subscriber 机器。
a. 在 Subscriber 机器上安装与主集群相同版本的 YMatrix 数据库软件。
b. 在主集群侧所在的节点上使用 root 权限在 /etc/hosts 系统文件中添加新增的 Subscriber 主机名(Subscriber 主集群侧 IP 地址)。
c. 在主集群 Master 所在的机器中,以 root 用户身份,创建配置文件目录。
mkdir ~/subscriber并执行以下命令。
# 初始化 expand
/opt/ymatrix/matrixdb6/bin/mxctl expand init \
> ~/subscriber/expand.init
# 添加 subscriber 所在机器
cat ~/subscriber/expand.init | \
/opt/ymatrix/matrixdb6/bin/mxctl expand add --host {{subscriber 主机名或主集群侧 IP 地址}} \
> ~/subscriber/expand.add
# 进行网络互通性检查
cat ~/subscriber/expand.add | \
/opt/ymatrix/matrixdb6/bin/mxctl expand netcheck \
> ~/subscriber/expand.nc
# 生成 plan
cat ~/subscriber/expand.nc | \
/opt/ymatrix/matrixdb6/bin/mxbox deployer expand --physical-cluster-only \
> ~/subscriber/expand.plan
# 执行 plan
cat ~/subscriber/expand.plan | \
/opt/ymatrix/matrixdb6/bin/mxbox deployer execd. 编辑主集群所有 segment(master、standby 以及 primary 和 mirror)的 pg_hba.conf 文件。在“#user access rules”之前(最好是第一个非 trust 规则之前),新增如下一行内容。用来信任来自 Subscriber 的 replication 链接。
host all,replication mxadmin {{subscriber 主集群侧 IP 地址}}/32 truste. 在主集群 Master 机器,以 mxadmin 用户身份,执行以下命令使主集群重新加载配置文件,使 pg_hba.conf 配置生效。
/opt/ymatrix/matrixdb6/bin/mxstop -uSubscriber 配置文件
a. 在 Subscriber 机器,以 mxadmin 用户身份,创建配置文件目录。
mkdir ~/subscriberb. 根据以下模板,以 mxadmin 用户身份,创建 Subscriber 配置文件 ~/subscriber/sub.conf。
# ~/subscriber/sub.conf
module = 'subscriber'
perf_port = 5587
verbose = true # 日志级别根据实际需要
debug = false # 日志级别根据实际需要
[[receiver]]
type = 'db'
cluster_id = '' # 主集群 cluster_id
host = '' # 主集群 master 的主机名或IP
port = 4617 # 主集群 master supervisor 监听端口号
dbname = 'postgres'
username = 'mxadmin'
resume_mode = 'default'
restore_point_creation_interval_minute = '3' # 数据一致性通过 restore point 保障
# 该项控制创建 restore point 的时间间隔
# 根据客户需求调整
# 默认为5分钟
slot = 'internal_disaster_recovery_rep_slot' # 弃用选项(暂时保留)
[[sender]]
type = 'socket'
port = 9320 # subscriber 的监听端口Supervisor 配置文件
a. 以 root 用户身份,在 /etc/matrixdb6/service 下创建 supervisor 托管 subscriber 的配置文件 subscriber.conf。
# /etc/matrixdb/service/subscriber.conf
[program:subscriber]
process_name=subscriber
command=%(ENV_MXHOME)s/bin/mxdr -s <COUNT> -c /home/mxadmin/subscriber/sub.conf
directory=%(ENV_MXHOME)s/bin
autostart=true
autorestart=true
stopsignal=TERM
stdout_logfile=/home/mxadmin/gpAdminLogs/subscriber.log
stdout_logfile_maxbytes=50MB
stdout_logfile_backups=10
redirect_stderr=true
user=mxadmin其中 <COUNT> 为主集群 shard 数量,可以通过执行以下命令获得。
SELECT count(1) FROM gp_segment_configuration WHERE role='p'使用 supervisor 运行和管理 Subscriber
a. 在 Subscriber 机器,以 root 用户身份,执行以下命令,将 Subscriber 托管于 supervisor。
/opt/ymatrix/matrixdb6/bin/supervisorctl update
/opt/ymatrix/matrixdb6/bin/supervisorctl start subscriber在 Publisher 和备份集群机器上安装与主集群相同版本的 YMatrix 数据库软件,并安装依赖。
在备份集群侧所在的节点上使用 root 权限在 /etc/hosts 系统文件中添加新增的 Publisher 主机名(Publisher 主集群侧 IP 地址)。
在 Publisher 机器,以 root 用户身份,创建配置文件目录。
mkdir ~/publisher生产映射配置文件
在主集群 Master 机器,以 mxadmin 用户身份,执行下述 SQL 命令,为备份集群 shard 映射配置文件生成模板 /tmp/mapping.tmp。
COPY (
SELECT content, hostname, port, datadir
FROM gp_segment_configuration
WHERE role='p'
ORDER BY content
) TO '/tmp/mapping.tmp' DELIMITER '|'根据实际情况,对生成的文件进行修改。文件第一列为主集群 content id,无需修改;后三列均为备份集群信息,需要根据实际情况修改,它们的含义分别是主机名、primary 端口号以及数据目录。可执行以下命令查看详细说明。
mxbox deployer dr pub config修改完成后,将该文件移动到 Publisher 机器的 root 用户的 ~/publisher 目录下。
修改示例如下:
| 修改前 | 修改后 |
|---|---|
 |
 |
Publisher 配置文件
根据以下模板,在 Publisher 机器中以 root 用户身份,创建 Publisher 配置文件 ~/Publisher/pub.conf。
# ~/publisher/pub.conf
module = 'publisher'
perf_port = 6698
verbose = true # 日志级别根据实际需要
debug = false # 日志级别根据实际需要
[[receiver]]
type = 'socket'
host = '' # subscriber IP 地址,即上文“subscriber 对外 IP 地址”
port = 9320 # subscriber 的监听端口
[[sender]]
type = 'db'
host = '127.0.0.1'
listen = 6432 # publisher 监听基础端口,范围随shard数量变化
username = 'mxadmin'
dbname = 'postgres'
dir = '/tmp' # 运行过程中临时信息存储目录
schedule = 'disable' # disable M2 scheduler部署备份集群
在 Publisher 所在机器,以 root 用户身份,按以下步骤执行命令。
a. collect
# 收集 master 机器信息
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{备份集群 master 所在机器 IP}} \
> ~/publisher/collect.1
# 收集其他要部署 segment 机器信息
cat ~/publisher/collect.1 | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{备份集群其他机器 IP}} \
> ~/publisher/collect.2
...
# 收集其他要部署 segment 机器信息
cat~/publisher/collect.n-1 | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{备份集群其他机器 IP}} \
> ~/publisher/collect.n
# 收集 publisher 所在机器信息
cat~/publisher/collect.n | \
/opt/ymatrix/matrixdb6/bin/mxctl setup collect --host {{publisher机器 IP}} \
> ~/publisher/collect.ncb. netcheck
cat ~/publisher/collect.nc | \
/opt/ymatrix/matrixdb6/bin/mxctl setup netcheck \
> ~/publisher/plan.ncc. plan
/opt/ymatrix/matrixdb6/bin/mxbox deployer dr pub plan \
--wait \
--enable-redo-stop-pit \
--collect-file ~/publisher/plan.nc \
--mapping-file ~/publisher/mapping.conf \
--publisher-file ~/publisher/pub.conf \
> ~/publisher/plan注意!
一定要设置--enable-redo-stop-pit,这是保障备份集群数据最终一致性的选项。
d. setup
/opt/ymatrix/matrixdb6/bin/mxbox deployer dr pub setup \
--plan-file ~/publisher/plan在主集群各个 primary 所在机器,以 root 用户身份,执行以下命令。
ps aux | grep postgres | grep walsender应存在与 subscriber 连接的进程,且进程处于 streaming 状态,示例如下:

在 Subscriber 所在机器,以 mxadmin 用户身份,执行以下命令。
supervisorctl status应存在名为 subscriber 的进程,且处于 Running 状态,示例如下:

在 Publisher 所在机器,以 mxadmin 用户身份,执行以下命令。
supervisorctl status应存在名称前缀为 publisher 的进程,且处于 Running 状态,示例如下:

在备份集群各个机器,以 root 用户身份,执行以下命令。
ps aux | grep postgres | grep walreceiver应存在与 subscriber 连接的进程,且进程处于 streaming 状态,示例如下:

注:备份集群中,walreceiver 进程数量总和应与原集群 shard 数量相同。
具体操作步骤如下:
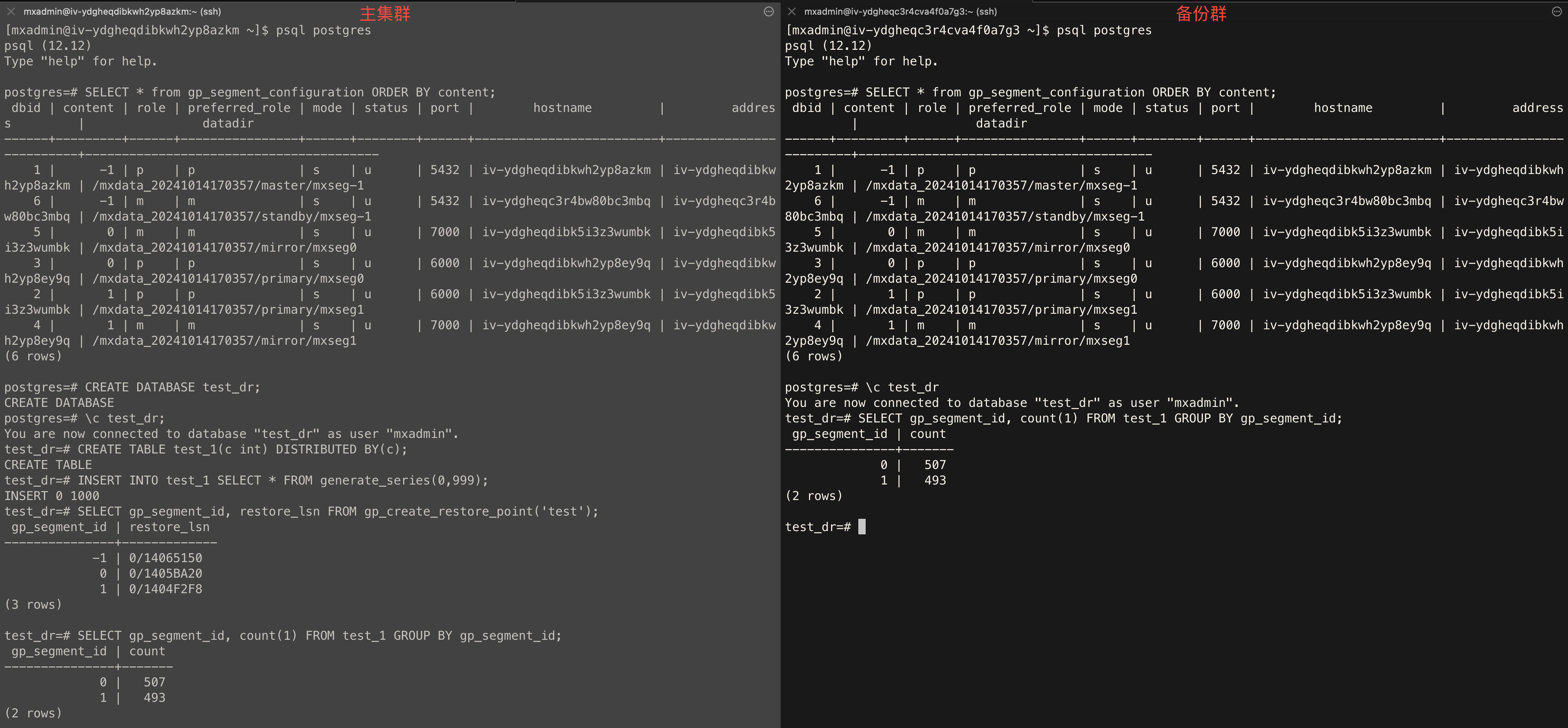
分别连接到主集群和备份集群的 Master,执行以下语句,检查两者结果是否一致。
SELECT * from gp_segment_configuration ORDER BY content, dbid;连接主集群 Master,执行以下语句,创建测试用 test_dr 数据库。
CREATE DATABASE test_dr;连接主集群的 test_dr 库,执行以下语句,创建测试用 test_1 数据表。
CREATE TABLE test_1(c int) DISTRIBUTED BY (c);连接主集群的 test_dr 库,执行以下语句,向 test_1 数据表中插入一些数据。
INSERT INTO test_1 SELECT * FROM generate_series(0,999);连接主集群的 test_dr 库,执行以下语句, 创建一个全局一致性点 test。
SELECT gp_segment_id, restore_lsn FROM gp_create_restore_point('test');分别连接到主备份集群的 test_dr 库,执行以下语句,检查两者结果是否一致。
SELECT gp_segment_id, count(1) FROM test_1 GROUP BY gp_segment_id;示例如下: