400-800-0824

info@ymatrix.cn
400-800-0824
info@ymatrix.cn
400-800-0824
info@ymatrix.cn
关于 YMatrix
标准集群部署
数据写入
数据迁移
数据查询
运维监控
参考指南
工具指南
数据类型
存储引擎
执行引擎
流计算引擎
灾难恢复
系统配置参数
索引
扩展
SQL 参考
常见问题(FAQ)
YMatrix 采用了 Share-nothing 并行架构。其核心特点是各个节点独立运行,不共享内存或存储,节点之间仅通过网络通信进行协作。这种架构广泛应用于分布式数据库、大数据系统和高并发 Web 服务中。
一个完整的 YMatrix 生产集群包括:

数据节点是 YMatrix 进行数据存储、计算的核心单元。数据表的数据会根据配置打散分布至各个主实例(Primary)中,每个主实例独立持有与其他主实例完全不重合的数据分片。当执行查询时,主节点(Master)生成查询计划后分发至所有主实例并行执行,通过并行计算提升查询响应速度
一个节点上可以有多个独立的主实例
一个节点上可以有多个独立的镜像实例
查询经过优化器生成执行计划,然后通过计算引擎、存储引擎读取相应数据,并进行计算,最终得到查询结果。
YMatrix 提供 2 种优化器:
YMatrix 提供 2 种存储引擎:
YMatrix 提供了经过经过全面向量化改造的向量化执行引擎。在大数据量场景下,能够大幅提升查询速度。
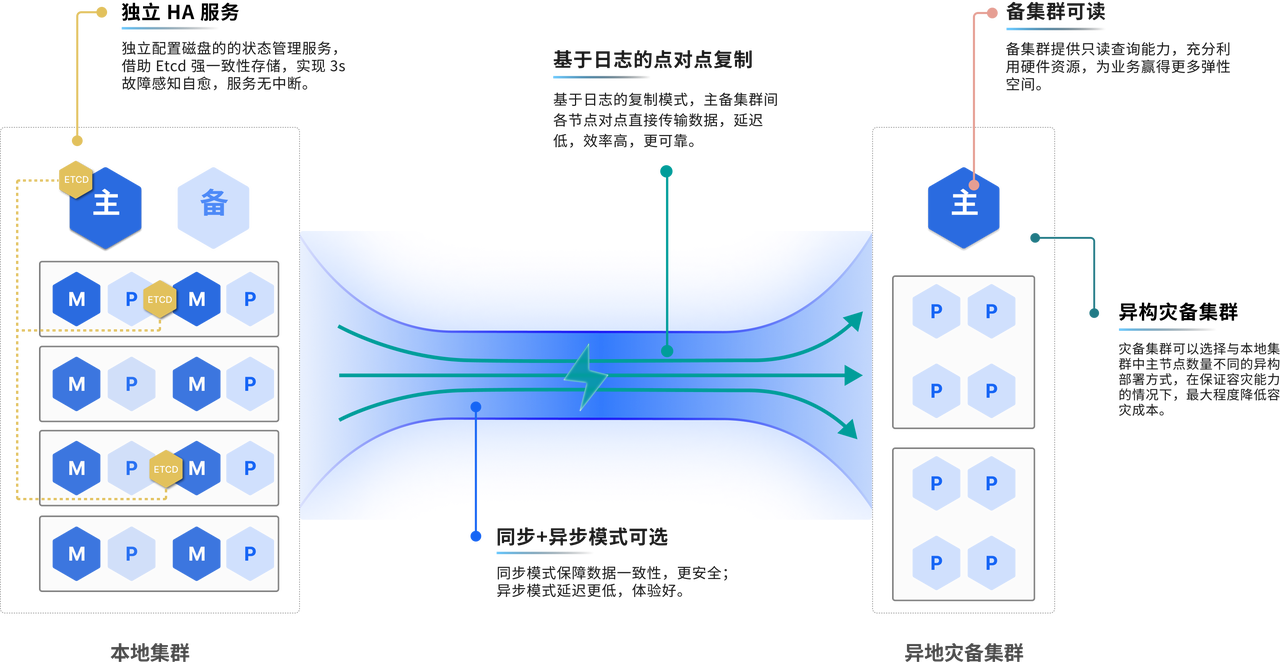
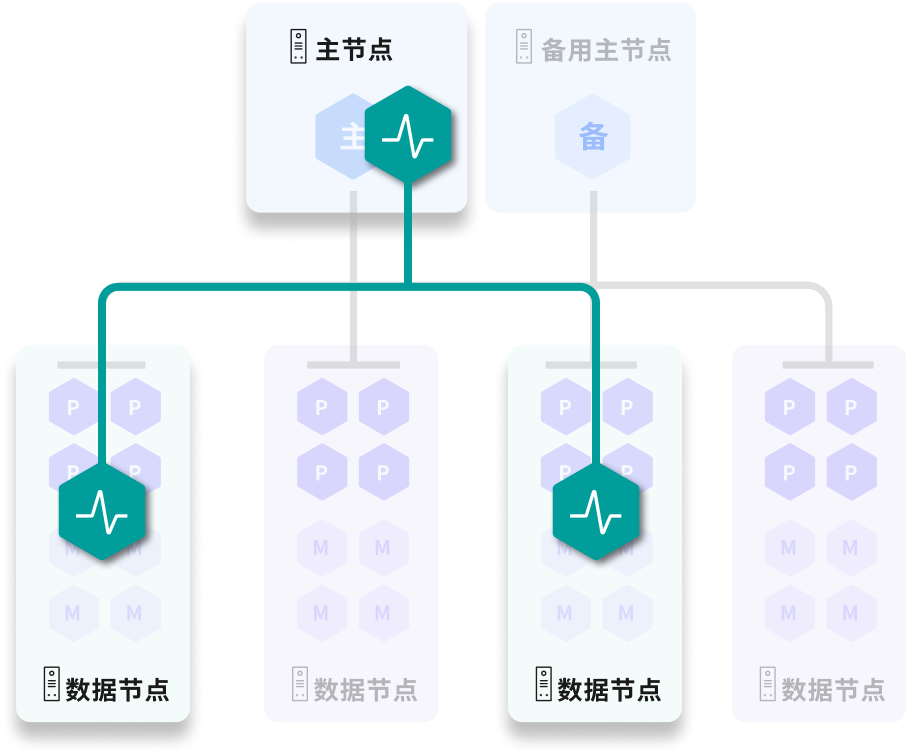
YMatrix 通过镜像机制保障集群的高可用性,同时还提供了异地灾备功能,保障极端条件下能够通过备用集群提供服务。
启用镜像功能后,每个主实例都会对应一个镜像实例,镜像实例与主实例会保持完全一致的数据和功能。在生产环境中,我们会保持主实例与对应的镜像主实例分布在不同的主机上。
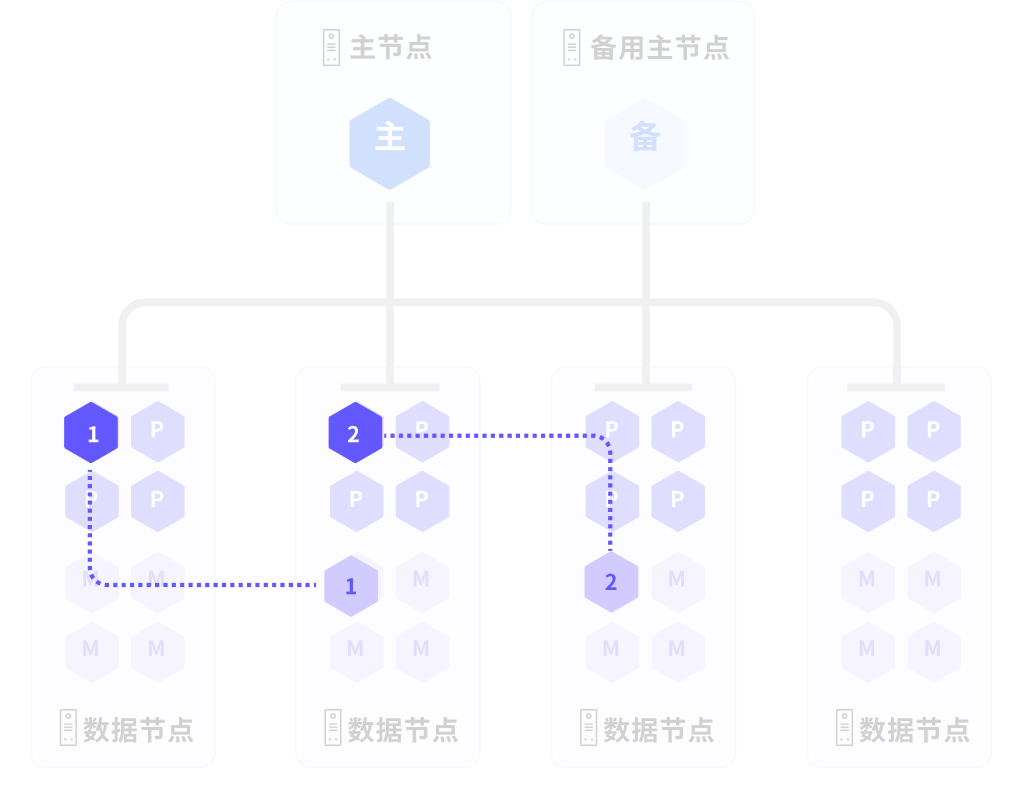
ALOHA(Advanced Least Operation High Availability) 是全新设计的集群状态管理服务。
YMatrix 集群中,会随机选取奇数个节点构建分布式 ETCD 集群 ,用以保存节点、实例状态;当故障(节点宕机/实例故障等)发生时,系统可根据集群状态进行调度,实现主备自动切换、故障自动转移等功能,保障集群的高可用性。
YMatrix 提供异地灾备集群部署方案。一旦主集群侧发生故障,可切换至备份集群,由备份集群提供正常服务,此时该集群的使用方式与正常 YMatrix 数据库集群使用方式保持一致。